 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neuro-Symbolic Decision Transformer
Mar 10, 2025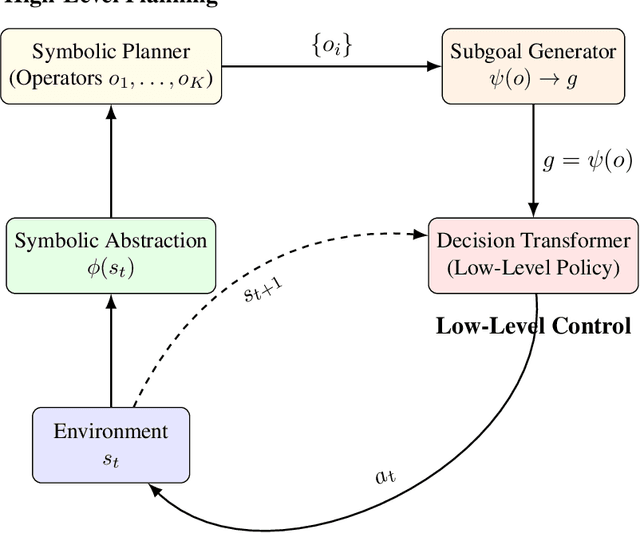
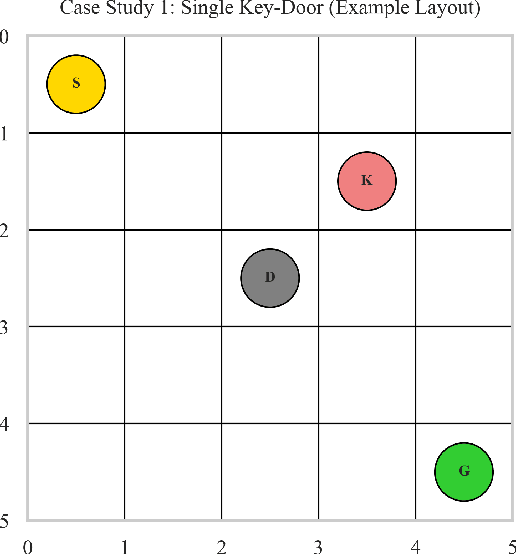
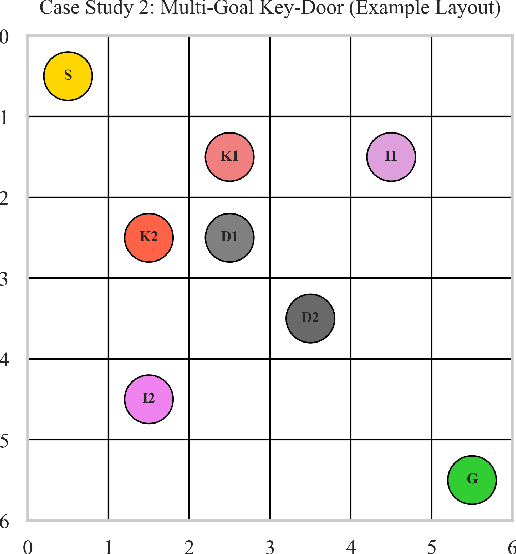
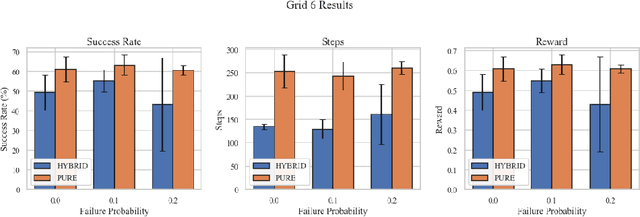
We present a hierarchical neuro-symbolic control framework that couples classical symbolic planning with transformer-based policies to address complex, long-horizon decision-making tasks. At the high level, a symbolic planner constructs an interpretable sequence of operators based on logical propositions, ensuring systematic adherence to global constraints and goals. At the low level, each symbolic operator is translated into a sub-goal token that conditions a decision transformer to generate a fine-grained sequence of actions in uncertain, high-dimensional environments. We provide theoretical analysis showing how approximation errors from both the symbolic planner and the neural execution layer accumulate. Empirical evaluations in grid-worlds with multiple keys, locked doors, and item-collection tasks show that our hierarchical approach outperforms purely end-to-end neural approach in success rates and policy efficiency.
LLMs-augmented Contextual Bandit
Nov 03, 2023

Contextual bandits have emerged as a cornerstone in reinforcement learning, enabling systems to make decisions with partial feedback. However, as contexts grow in complexity, traditional bandit algorithms can face challenges in adequately capturing and utilizing such contexts. In this paper, we propose a novel integration of large language models (LLMs) with the contextual bandit framework. By leveraging LLMs as an encoder, we enrich the representation of the context, providing the bandit with a denser and more informative view. Preliminary results on synthetic datasets demonstrate the potential of this approach, showing notable improvements in cumulative rewards and reductions in regret compared to traditional bandit algorithms. This integration not only showcases the capabilities of LLMs in reinforcement learning but also opens the door to a new era of contextually-aware decision systems.
Using BERT Embeddings to Model Word Importance in Conversational Transcripts for Deaf and Hard of Hearing Users
Jun 24, 2022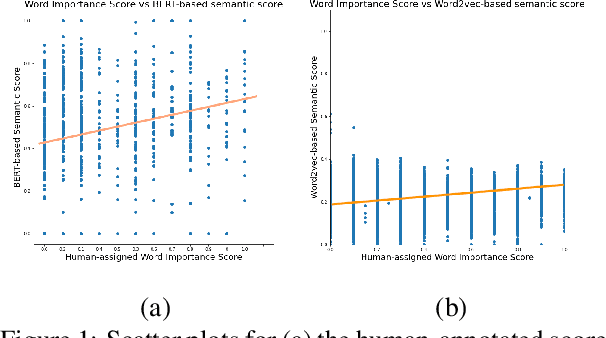
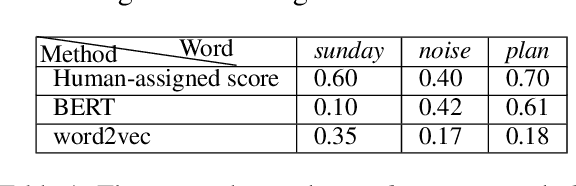

Deaf and hard of hearing individuals regularly rely on captioning while watching live TV. Live TV captioning is evaluated by regulatory agencies using various caption evaluation metrics. However, caption evaluation metrics are often not informed by preferences of DHH users or how meaningful the captions are. There is a need to construct caption evaluation metrics that take the relative importance of words in a transcript into account. We conducted correlation analysis between two types of word embeddings and human-annotated labeled word-importance scores in existing corpus. We found that normalized contextualized word embeddings generated using BERT correlated better with manually annotated importance scores than word2vec-based word embeddings. We make available a pairing of word embeddings and their human-annotated importance scores. We also provide proof-of-concept utility by training word importance models, achieving an F1-score of 0.57 in the 6-class word importance classification task.
Modeling Acoustic-Prosodic Cues for Word Importance Prediction in Spoken Dialogues
Mar 28, 2019
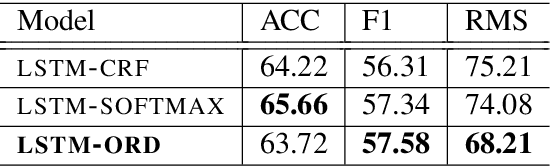
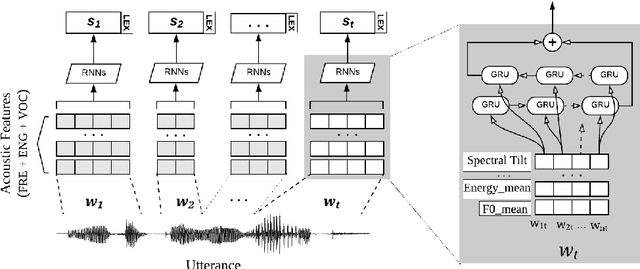
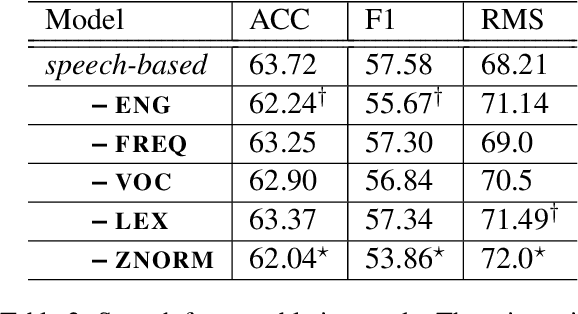
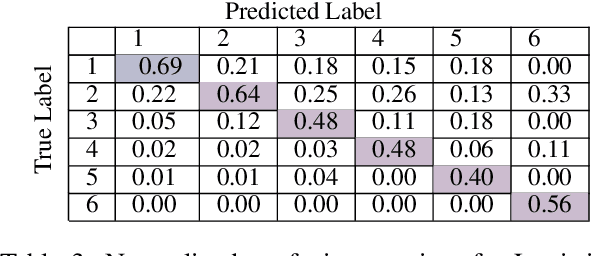
Prosodic cues in conversational speech aid listeners in discerning a message. We investigate whether acoustic cues in spoken dialogue can be used to identify the importance of individual words to the meaning of a conversation turn. Individuals who are Deaf and Hard of Hearing often rely on real-time captions in live meetings. Word error rate, a traditional metric for evaluating automatic speech recognition, fails to capture that some words are more important for a system to transcribe correctly than others. We present and evaluate neural architectures that use acoustic features for 3-class word importance prediction. Our model performs competitively against state-of-the-art text-based word-importance prediction models, and it demonstrates particular benefits when operating on imperfect ASR output.