 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASL-Homework-RGBD Dataset: An annotated dataset of 45 fluent and non-fluent signers performing American Sign Language homeworks
Jul 08, 2022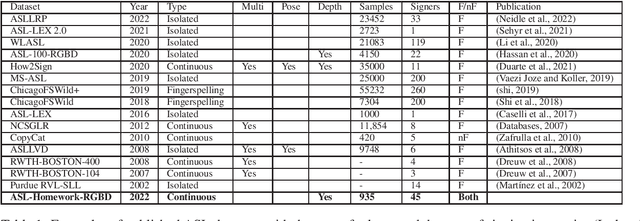
We are releasing a dataset containing videos of both fluent and non-fluent signers using American Sign Language (ASL), which were collected using a Kinect v2 sensor. This dataset was collected as a part of a project to develop and evaluate computer vision algorithms to support new technologies for automatic detection of ASL fluency attributes. A total of 45 fluent and non-fluent participants were asked to perform signing homework assignments that are similar to the assignments used in introductory or intermediate level ASL courses. The data is annotated to identify several aspects of signing including grammatical features and non-manual markers. Sign language recognition is currently very data-driven and this dataset can support the design of recognition technologies, especially technologies that can benefit ASL learners. This dataset might also be interesting to ASL education researchers who want to contrast fluent and non-fluent signing.
Using BERT Embeddings to Model Word Importance in Conversational Transcripts for Deaf and Hard of Hearing Users
Jun 24, 2022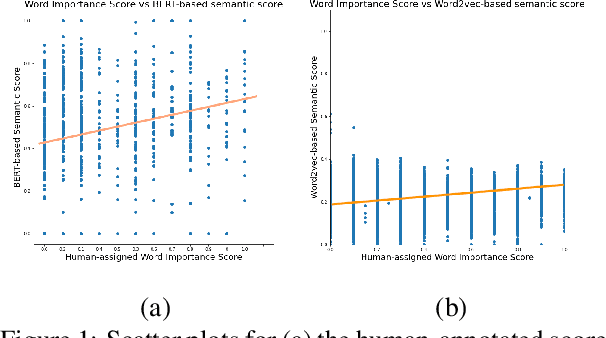
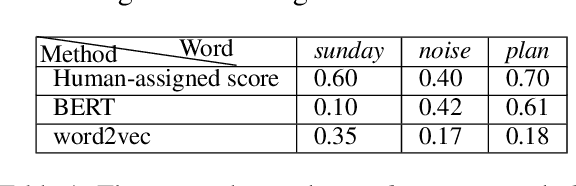

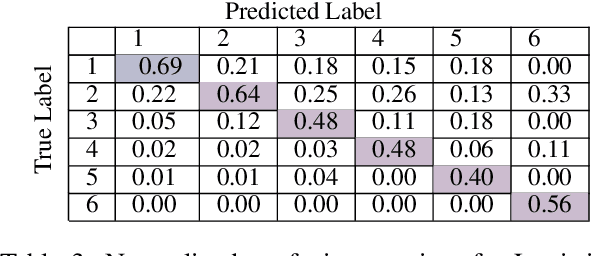
Deaf and hard of hearing individuals regularly rely on captioning while watching live TV. Live TV captioning is evaluated by regulatory agencies using various caption evaluation metrics. However, caption evaluation metrics are often not informed by preferences of DHH users or how meaningful the captions are. There is a need to construct caption evaluation metrics that take the relative importance of words in a transcript into account. We conducted correlation analysis between two types of word embeddings and human-annotated labeled word-importance scores in existing corpus. We found that normalized contextualized word embeddings generated using BERT correlated better with manually annotated importance scores than word2vec-based word embeddings. We make available a pairing of word embeddings and their human-annotated importance scores. We also provide proof-of-concept utility by training word importance models, achieving an F1-score of 0.57 in the 6-class word importance classification task.
Unpacking the Interdependent Systems of Discrimination: Ableist Bias in NLP Systems through an Intersectional Lens
Oct 01, 2021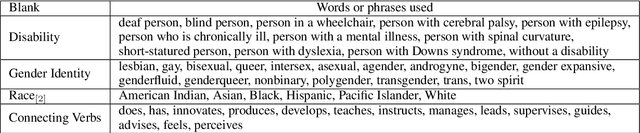



Much of the world's population experiences some form of disability during their lifetime. Caution must be exercised while designing natural language processing (NLP) systems to prevent systems from inadvertently perpetuating ableist bias against people with disabilities, i.e., prejudice that favors those with typical abilities. We report on various analyses based on word predictions of a large-scale BERT language model. Statistically significant results demonstrate that people with disabilities can be disadvantaged. Findings also explore overlapping forms of discrimination related to interconnected gender and race identities.
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
May 01, 2020



As part of the development of an educational tool that can help students achieve fluency in American Sign Language (ASL) through independent and interactive practice with immediate feedback, this paper introduces a near real-time system to recognize grammatical errors in continuous signing videos without necessarily identifying the entire sequence of signs. Our system automatically recognizes if performance of ASL sentences contains grammatical errors made by ASL students. We first recognize the ASL grammatical elements including both manual gestures and nonmanual signals independently from multiple modalities (i.e. hand gestures, facial expressions, and head movements) by 3D-ResNet networks. Then the temporal boundaries of grammatical elements from different modalities are examined to detect ASL grammatical mistakes by using a sliding window-based approach. We have collected a dataset of continuous sign language, ASL-HW-RGBD, covering different aspects of ASL grammars for training and testing. Our system is able to recognize grammatical elements on ASL-HW-RGBD from manual gestures, facial expressions, and head movements and successfully detect 8 ASL grammatical mistakes.
Sign Language Recognition, Generation, and Translation: An Interdisciplinary Perspective
Aug 22, 2019

Developing successful sign language recognition, generation, and translation systems requires expertise in a wide range of fields, including computer vision, computer graphics, natural language processing, human-computer interaction, linguistics, and Deaf culture. Despite the need for deep interdisciplinary knowledge, existing research occurs in separate disciplinary silos, and tackles separate portions of the sign language processing pipeline. This leads to three key questions: 1) What does an interdisciplinary view of the current landscape reveal? 2) What are the biggest challenges facing the field? and 3) What are the calls to action for people working in the field? To help answer these questions, we brought together a diverse group of experts for a two-day workshop. This paper presents the results of that interdisciplinary workshop, providing key background that is often overlooked by computer scientists, a review of the state-of-the-art, a set of pressing challenges, and a call to action for the research community.
Recognizing American Sign Language Manual Signs from RGB-D Videos
Jun 07, 2019


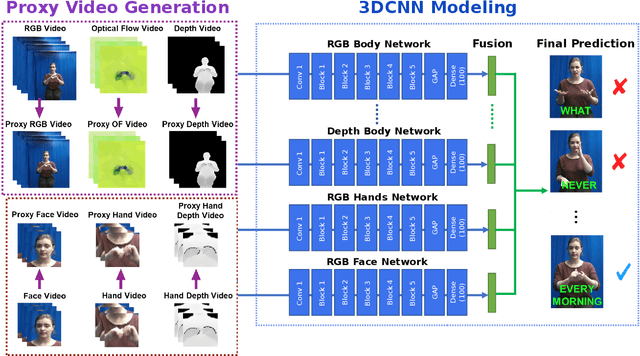
In this paper, we propose a 3D Convolutional Neural Network (3DCNN) based multi-stream framework to recognize American Sign Language (ASL) manual signs (consisting of movements of the hands, as well as non-manual face movements in some cases) in real-time from RGB-D videos, by fusing multimodality features including hand gestures, facial expressions, and body poses from multi-channels (RGB, depth, motion, and skeleton joints). To learn the overall temporal dynamics in a video, a proxy video is generated by selecting a subset of frames for each video which are then used to train the proposed 3DCNN model. We collect a new ASL dataset, ASL-100-RGBD, which contains 42 RGB-D videos captured by a Microsoft Kinect V2 camera, each of 100 ASL manual signs, including RGB channel, depth maps, skeleton joints, face features, and HDface. The dataset is fully annotated for each semantic region (i.e. the time duration of each word that the human signer performs). Our proposed method achieves 92.88 accuracy for recognizing 100 ASL words in our newly collected ASL-100-RGBD dataset. The effectiveness of our framework for recognizing hand gestures from RGB-D videos is further demonstrated on the Chalearn IsoGD dataset and achieves 76 accuracy which is 5.51 higher than the state-of-the-art work in terms of average fusion by using only 5 channels instead of 12 channels in the previous work.
Modeling Acoustic-Prosodic Cues for Word Importance Prediction in Spoken Dialogues
Mar 28, 2019
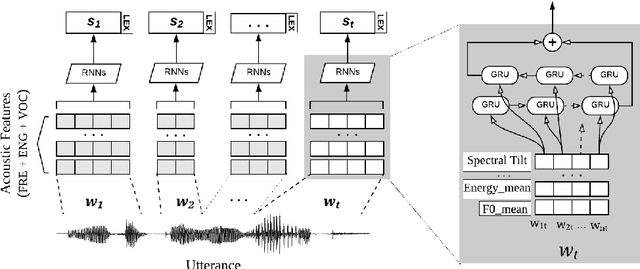
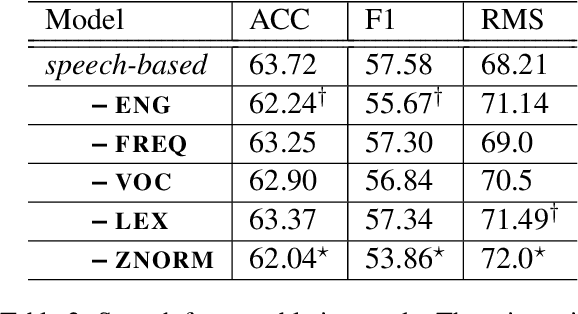
Prosodic cues in conversational speech aid listeners in discerning a message. We investigate whether acoustic cues in spoken dialogue can be used to identify the importance of individual words to the meaning of a conversation turn. Individuals who are Deaf and Hard of Hearing often rely on real-time captions in live meetings. Word error rate, a traditional metric for evaluating automatic speech recognition, fails to capture that some words are more important for a system to transcribe correctly than others. We present and evaluate neural architectures that use acoustic features for 3-class word importance prediction. Our model performs competitively against state-of-the-art text-based word-importance prediction models, and it demonstrates particular benefits when operating on imperfect ASR output.
A Corpus for Modeling Word Importance in Spoken Dialogue Transcripts
Feb 09, 2018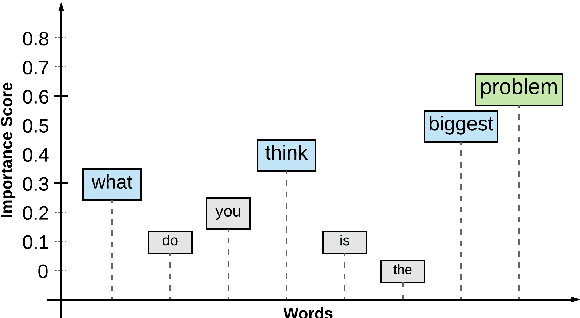

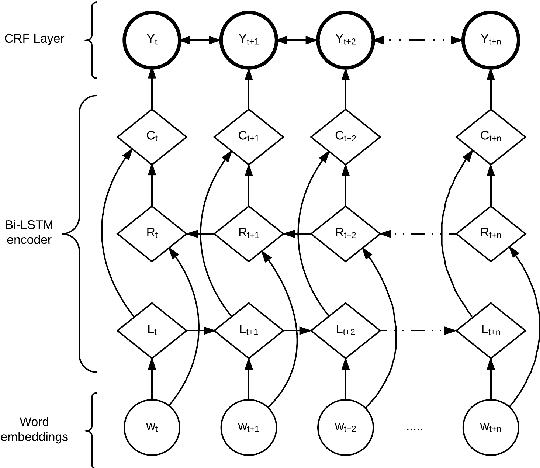
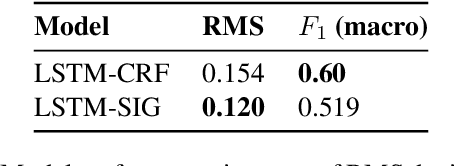
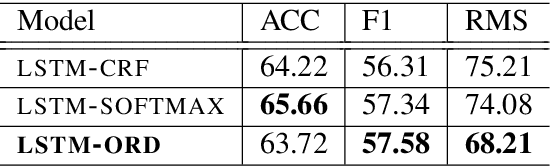
Motivated by a project to create a system for people who are deaf or hard-of-hearing that would use automatic speech recognition (ASR) to produce real-time text captions of spoken English during in-person meetings with hearing individuals, we have augmented a transcript of the Switchboard conversational dialogue corpus with an overlay of word-importance annotations, with a numeric score for each word, to indicate its importance to the meaning of each dialogue turn. Further, we demonstrate the utility of this corpus by training an automatic word importance labeling model; our best performing model has an F-score of 0.60 in an ordinal 6-class word-importance classification task with an agreement (concordance correlation coefficient) of 0.839 with the human annotators (agreement score between annotators is 0.89). Finally, we discuss our intended future applications of this resource, particularly for the task of evaluating ASR performance, i.e. creating metrics that predict ASR-output caption text usability for DHH users better thanWord Error Rate (WER).
* Language Resources and Evaluation Conference (LREC)