 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADM-Loc: Actionness Distribution Modeling for Point-supervised Temporal Action Localization
Nov 27, 2023



This paper addresses the challenge of point-supervised temporal action detection, in which only one frame per action instance is annotated in the training set. Self-training aims to provide supplementary supervision for the training process by generating pseudo-labels (action proposals) from a base model. However, most current methods generate action proposals by applying manually designed thresholds to action classification probabilities and treating adjacent snippets as independent entities. As a result, these methods struggle to generate complete action proposals, exhibit sensitivity to fluctuations in action classification scores, and generate redundant and overlapping action proposals. This paper proposes a novel framework termed ADM-Loc, which stands for Actionness Distribution Modeling for point-supervised action Localization. ADM-Loc generates action proposals by fitting a composite distribution, comprising both Gaussian and uniform distributions, to the action classification signals. This fitting process is tailored to each action class present in the video and is applied separately for each action instance, ensuring the distinctiveness of their distributions. ADM-Loc significantly enhances the alignment between the generated action proposals and ground-truth action instances and offers high-quality pseudo-labels for self-training. Moreover, to model action boundary snippets, it enforces consistency in action classification scores during training by employing Gaussian kernels, supervised with the proposed loss functions. ADM-Loc outperforms the state-of-the-art point-supervised methods on THUMOS14 and ActivityNet-v1.2 datasets.
POTLoc: Pseudo-Label Oriented Transformer for Point-Supervised Temporal Action Localization
Oct 20, 2023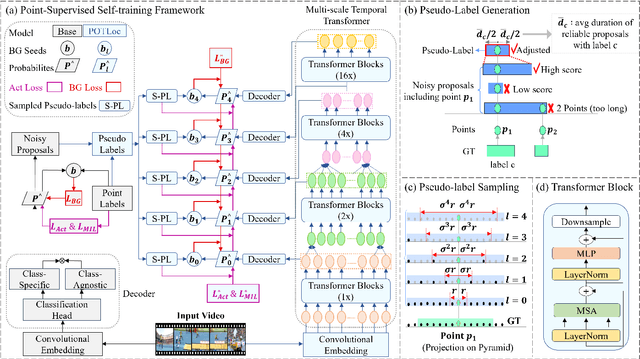
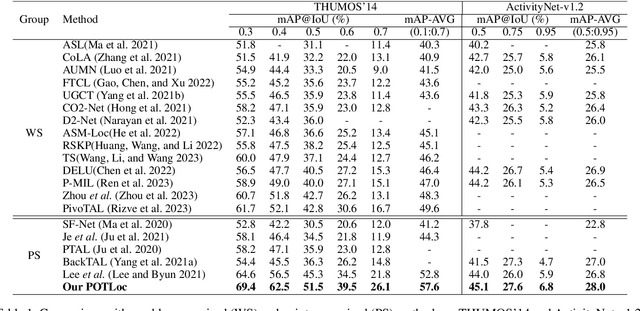
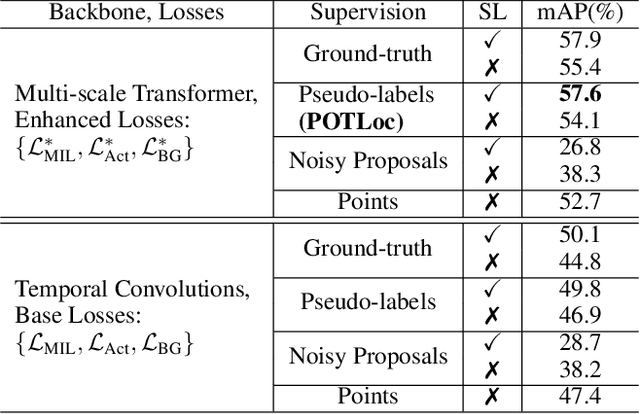
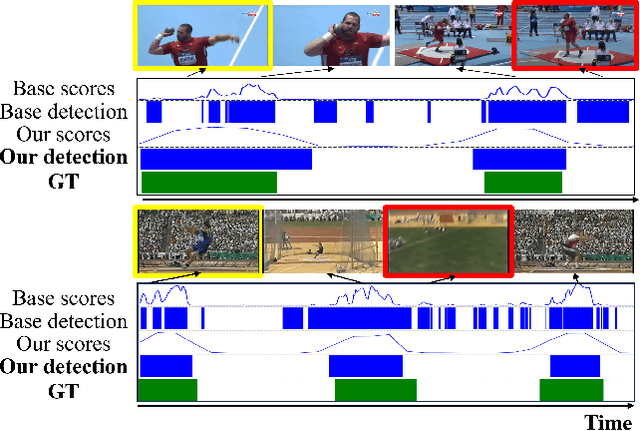
This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a Pseudo-label Oriented Transformer for weakly-supervised Action Localization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of `pseudo-labels' to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS'14 and ActivityNet-v1.2 datasets, showing a significant improvement of 5% average mAP on the former.
Deep Learning-based Action Detection in Untrimmed Videos: A Survey
Sep 30, 2021
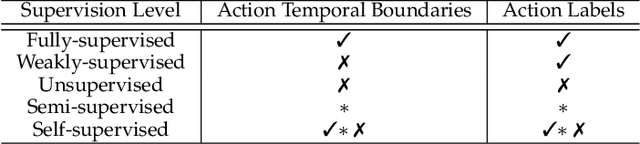


Understanding human behavior and activity facilitates advancement of numerous real-world applications, and is critical for video analysis. Despite the progress of action recognition algorithms in trimmed videos, the majority of real-world videos are lengthy and untrimmed with sparse segments of interest. The task of temporal activity detection in untrimmed videos aims to localize the temporal boundary of actions and classify the action categories. Temporal activity detection task has been investigated in full and limited supervision settings depending on the availability of action annotations. This paper provides an extensive overview of deep learning-based algorithms to tackle temporal action detection in untrimmed videos with different supervision levels including fully-supervised, weakly-supervised, unsupervised, self-supervised, and semi-supervised. In addition, this paper also reviews advances in spatio-temporal action detection where actions are localized in both temporal and spatial dimensions. Moreover, the commonly used action detection benchmark datasets and evaluation metrics are described, and the performance of the state-of-the-art methods are compared. Finally, real-world applications of temporal action detection in untrimmed videos and a set of future directions are discussed.
Cross-modal Center Loss
Aug 08, 2020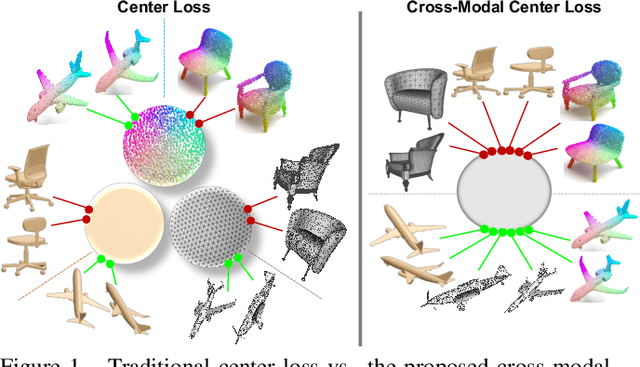
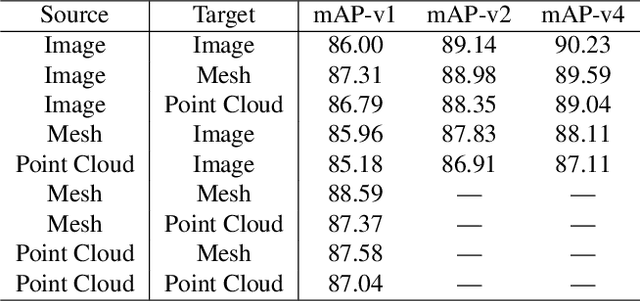
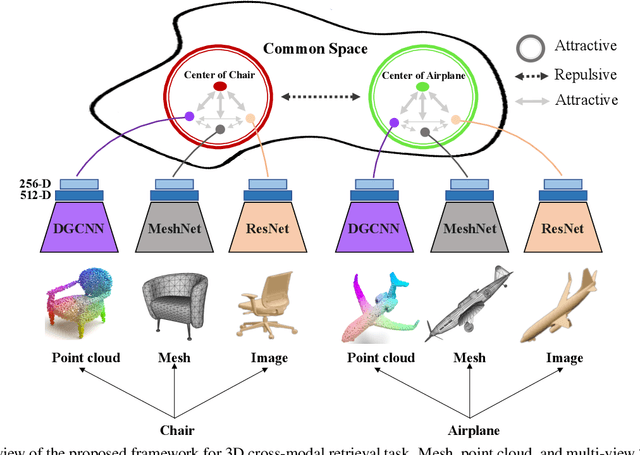
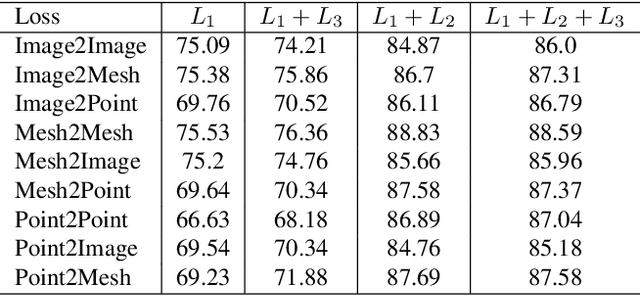
Cross-modal retrieval aims to learn discriminative and modal-invariant features for data from different modalities. Unlike the existing methods which usually learn from the features extracted by offline networks, in this paper, we propose an approach to jointly train the components of cross-modal retrieval framework with metadata, and enable the network to find optimal features. The proposed end-to-end framework is updated with three loss functions: 1) a novel cross-modal center loss to eliminate cross-modal discrepancy, 2) cross-entropy loss to maximize inter-class variations, and 3) mean-square-error loss to reduce modality variations. In particular, our proposed cross-modal center loss minimizes the distances of features from objects belonging to the same class across all modalities. Extensive experiments have been conducted on the retrieval tasks across multi-modalities, including 2D image, 3D point cloud, and mesh data. The proposed framework significantly outperforms the state-of-the-art methods on the ModelNet40 dataset.
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
May 01, 2020



As part of the development of an educational tool that can help students achieve fluency in American Sign Language (ASL) through independent and interactive practice with immediate feedback, this paper introduces a near real-time system to recognize grammatical errors in continuous signing videos without necessarily identifying the entire sequence of signs. Our system automatically recognizes if performance of ASL sentences contains grammatical errors made by ASL students. We first recognize the ASL grammatical elements including both manual gestures and nonmanual signals independently from multiple modalities (i.e. hand gestures, facial expressions, and head movements) by 3D-ResNet networks. Then the temporal boundaries of grammatical elements from different modalities are examined to detect ASL grammatical mistakes by using a sliding window-based approach. We have collected a dataset of continuous sign language, ASL-HW-RGBD, covering different aspects of ASL grammars for training and testing. Our system is able to recognize grammatical elements on ASL-HW-RGBD from manual gestures, facial expressions, and head movements and successfully detect 8 ASL grammatical mistakes.
Recognizing American Sign Language Manual Signs from RGB-D Videos
Jun 07, 2019


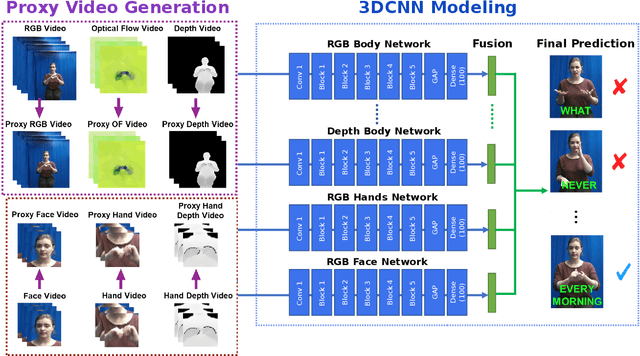
In this paper, we propose a 3D Convolutional Neural Network (3DCNN) based multi-stream framework to recognize American Sign Language (ASL) manual signs (consisting of movements of the hands, as well as non-manual face movements in some cases) in real-time from RGB-D videos, by fusing multimodality features including hand gestures, facial expressions, and body poses from multi-channels (RGB, depth, motion, and skeleton joints). To learn the overall temporal dynamics in a video, a proxy video is generated by selecting a subset of frames for each video which are then used to train the proposed 3DCNN model. We collect a new ASL dataset, ASL-100-RGBD, which contains 42 RGB-D videos captured by a Microsoft Kinect V2 camera, each of 100 ASL manual signs, including RGB channel, depth maps, skeleton joints, face features, and HDface. The dataset is fully annotated for each semantic region (i.e. the time duration of each word that the human signer performs). Our proposed method achieves 92.88 accuracy for recognizing 100 ASL words in our newly collected ASL-100-RGBD dataset. The effectiveness of our framework for recognizing hand gestures from RGB-D videos is further demonstrated on the Chalearn IsoGD dataset and achieves 76 accuracy which is 5.51 higher than the state-of-the-art work in terms of average fusion by using only 5 channels instead of 12 channels in the previous work.