 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Signer Overlap for Sign Language Detection
Mar 19, 2023



Sign language detection, identifying if someone is signing or not, is becoming crucially important for its applications in remote conferencing software and for selecting useful sign data for training sign language recognition or translation tasks. We argue that the current benchmark data sets for sign language detection estimate overly positive results that do not generalize well due to signer overlap between train and test partitions. We quantify this with a detailed analysis of the effect of signer overlap on current sign detection benchmark data sets. Comparing accuracy with and without overlap on the DGS corpus and Signing in the Wild, we observed a relative decrease in accuracy of 4.17% and 6.27%, respectively. Furthermore, we propose new data set partitions that are free of overlap and allow for more realistic performance assessment. We hope this work will contribute to improving the accuracy and generalization of sign language detection systems.
Clean Text and Full-Body Transformer: Microsoft's Submission to the WMT22 Shared Task on Sign Language Translation
Oct 24, 2022



This paper describes Microsoft's submission to the first shared task on sign language translation at WMT 2022, a public competition tackling sign language to spoken language translation for Swiss German sign language. The task is very challenging due to data scarcity and an unprecedented vocabulary size of more than 20k words on the target side. Moreover, the data is taken from real broadcast news, includes native signing and covers scenarios of long videos. Motivated by recent advances in action recognition, we incorporate full body information by extracting features from a pre-trained I3D model and applying a standard transformer network. The accuracy of the system is further improved by applying careful data cleaning on the target text. We obtain BLEU scores of 0.6 and 0.78 on the test and dev set respectively, which is the best score among the participants of the shared task. Also in the human evaluation the submission reaches the first place. The BLEU score is further improved to 1.08 on the dev set by applying features extracted from a lip reading model.
Dialectal Speech Recognition and Translation of Swiss German Speech to Standard German Text: Microsoft's Submission to SwissText 2021
Jul 01, 2021

This paper describes the winning approach in the Shared Task 3 at SwissText 2021 on Swiss German Speech to Standard German Text, a public competition on dialect recognition and translation. Swiss German refers to the multitude of Alemannic dialects spoken in the German-speaking parts of Switzerland. Swiss German differs significantly from standard German in pronunciation, word inventory and grammar. It is mostly incomprehensible to native German speakers. Moreover, it lacks a standardized written script. To solve the challenging task, we propose a hybrid automatic speech recognition system with a lexicon that incorporates translations, a 1st pass language model that deals with Swiss German particularities, a transfer-learned acoustic model and a strong neural language model for 2nd pass rescoring. Our submission reaches 46.04% BLEU on a blind conversational test set and outperforms the second best competitor by a 12% relative margin.
Multi-channel Transformers for Multi-articulatory Sign Language Translation
Sep 01, 2020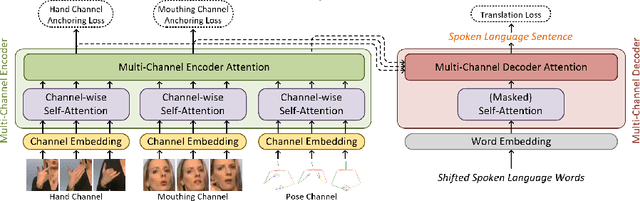
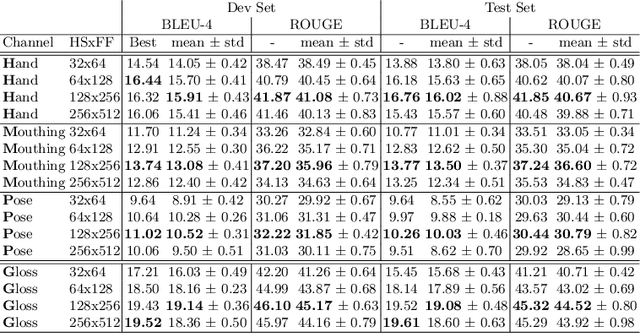
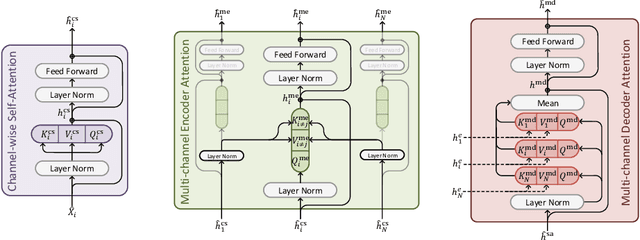
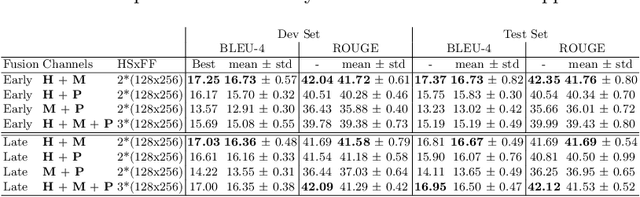
Sign languages use multiple asynchronous information channels (articulators), not just the hands but also the face and body, which computational approaches often ignore. In this paper we tackle the multi-articulatory sign language translation task and propose a novel multi-channel transformer architecture. The proposed architecture allows both the inter and intra contextual relationships between different sign articulators to be modelled within the transformer network itself, while also maintaining channel specific information. We evaluate our approach on the RWTH-PHOENIX-Weather-2014T dataset and report competitive translation performance. Importantly, we overcome the reliance on gloss annotations which underpin other state-of-the-art approaches, thereby removing future need for expensive curated datasets.
Quantitative Survey of the State of the Art in Sign Language Recognition
Aug 29, 2020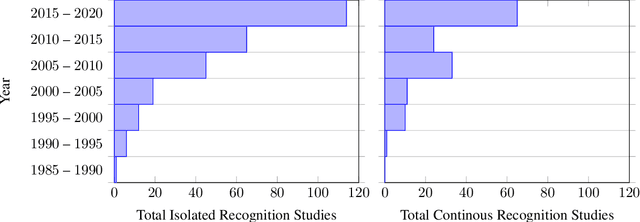
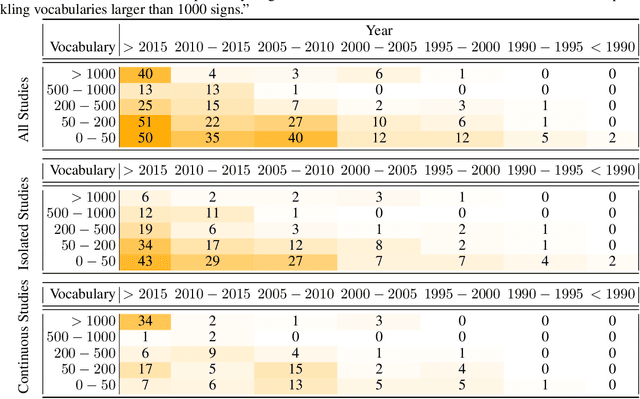
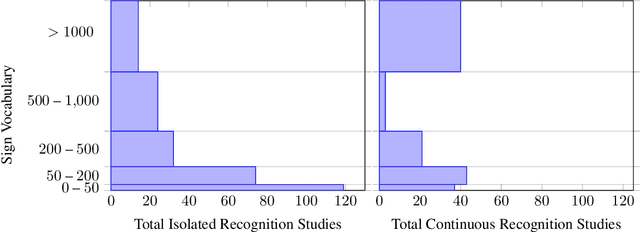
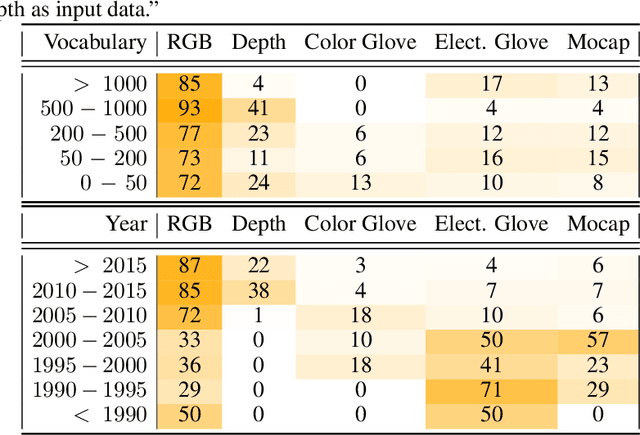
This work presents a meta study covering around 300 published sign language recognition papers with over 400 experimental results. It includes most papers between the start of the field in 1983 and 2020. Additionally, it covers a fine-grained analysis on over 25 studies that have compared their recognition approaches on RWTH-PHOENIX-Weather 2014, the standard benchmark task of the field. Research in the domain of sign language recognition has progressed significantly in the last decade, reaching a point where the task attracts much more attention than ever before. This study compiles the state of the art in a concise way to help advance the field and reveal open questions. Moreover, all of this meta study's source data is made public, easing future work with it and further expansion. The analyzed papers have been manually labeled with a set of categories. The data reveals many insights, such as, among others, shifts in the field from intrusive to non-intrusive capturing, from local to global features and the lack of non-manual parameters included in medium and larger vocabulary recognition systems. Surprisingly, RWTH-PHOENIX-Weather with a vocabulary of 1080 signs represents the only resource for large vocabulary continuous sign language recognition benchmarking world wide.
Sign Language Transformers: Joint End-to-end Sign Language Recognition and Translation
Mar 30, 2020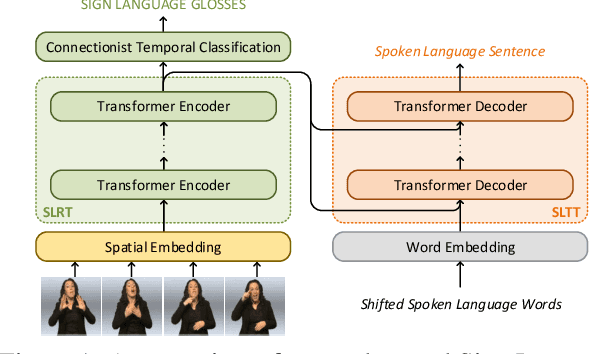
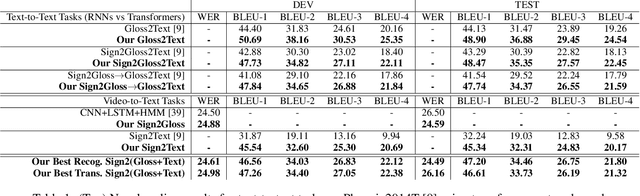
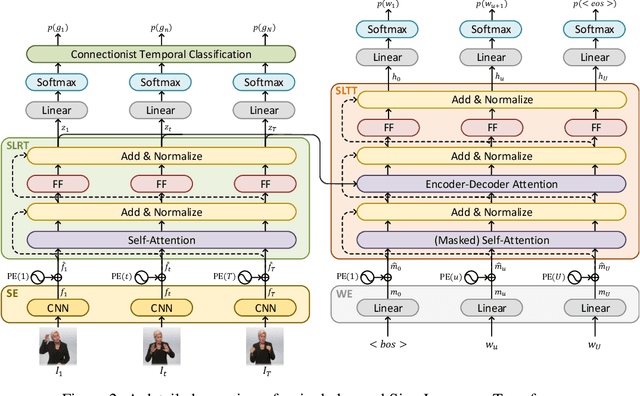
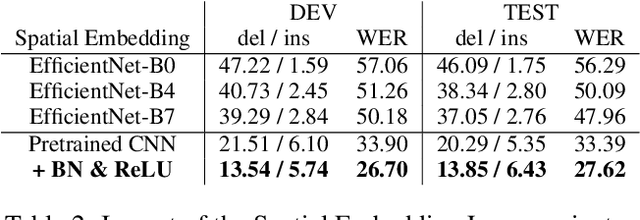
Prior work on Sign Language Translation has shown that having a mid-level sign gloss representation (effectively recognizing the individual signs) improves the translation performance drastically. In fact, the current state-of-the-art in translation requires gloss level tokenization in order to work. We introduce a novel transformer based architecture that jointly learns Continuous Sign Language Recognition and Translation while being trainable in an end-to-end manner. This is achieved by using a Connectionist Temporal Classification (CTC) loss to bind the recognition and translation problems into a single unified architecture. This joint approach does not require any ground-truth timing information, simultaneously solving two co-dependant sequence-to-sequence learning problems and leads to significant performance gains. We evaluate the recognition and translation performances of our approaches on the challenging RWTH-PHOENIX-Weather-2014T (PHOENIX14T) dataset. We report state-of-the-art sign language recognition and translation results achieved by our Sign Language Transformers. Our translation networks outperform both sign video to spoken language and gloss to spoken language translation models, in some cases more than doubling the performance (9.58 vs. 21.80 BLEU-4 Score). We also share new baseline translation results using transformer networks for several other text-to-text sign language translation tasks.
Sign Language Recognition, Generation, and Translation: An Interdisciplinary Perspective
Aug 22, 2019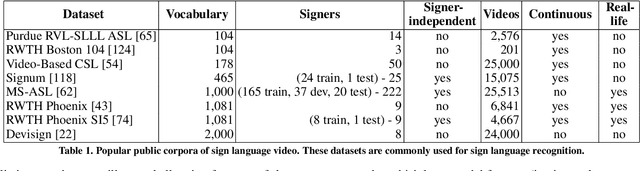

Developing successful sign language recognition, generation, and translation systems requires expertise in a wide range of fields, including computer vision, computer graphics, natural language processing, human-computer interaction, linguistics, and Deaf culture. Despite the need for deep interdisciplinary knowledge, existing research occurs in separate disciplinary silos, and tackles separate portions of the sign language processing pipeline. This leads to three key questions: 1) What does an interdisciplinary view of the current landscape reveal? 2) What are the biggest challenges facing the field? and 3) What are the calls to action for people working in the field? To help answer these questions, we brought together a diverse group of experts for a two-day workshop. This paper presents the results of that interdisciplinary workshop, providing key background that is often overlooked by computer scientists, a review of the state-of-the-art, a set of pressing challenges, and a call to action for the research community.
MS-ASL: A Large-Scale Data Set and Benchmark for Understanding American Sign Language
Dec 03, 2018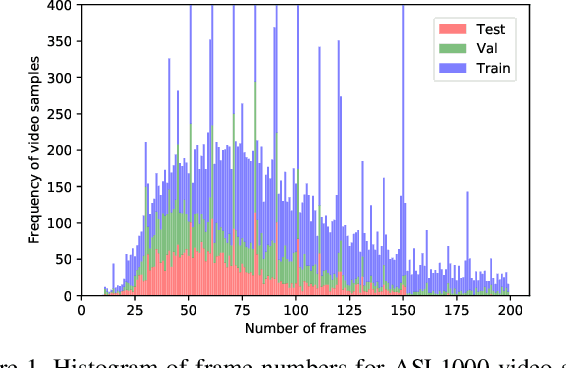

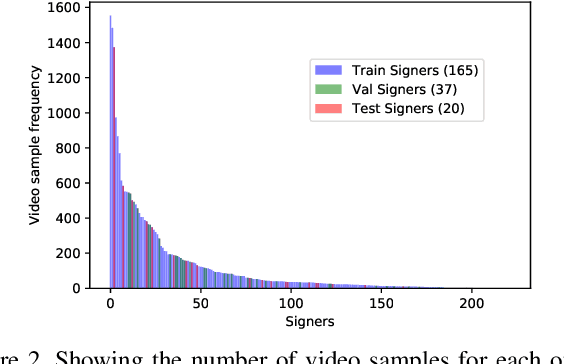
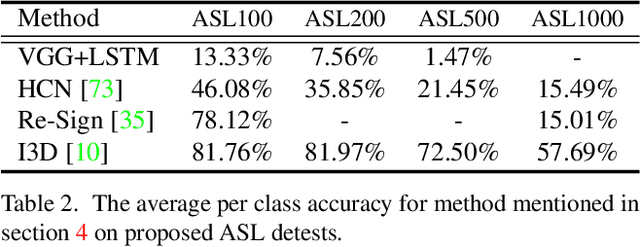
Computer Vision has been improved significantly in the past few decades. It has enabled machine to do many human tasks. However, the real challenge is in enabling machine to carry out tasks that an average human does not have the skills for. One such challenge that we have tackled in this paper is providing accessibility for deaf individual by providing means of communication with others with the aid of computer vision. Unlike other frequent works focusing on multiple camera, depth camera, electrical glove or visual gloves, we focused on the sole use of RGB which allows everybody to communicate with a deaf individual through their personal devices. This is not a new approach but the lack of realistic large-scale data set prevented recent computer vision trends on video classification in this filed. In this paper, we propose the first large scale ASL data set that covers over 200 signers, signer independent sets, challenging and unconstrained recording conditions and a large class count of 1000 signs. We evaluate baselines from action recognition techniques on the data set. We propose I3D, known from video classifications, as a powerful and suitable architecture for sign language recognition. We also propose new pre-trained model more appropriate for sign language recognition. Finally, We estimate the effect of number of classes and number of training samples on the recognition accuracy.