 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClean Text and Full-Body Transformer: Microsoft's Submission to the WMT22 Shared Task on Sign Language Translation
Oct 24, 2022



This paper describes Microsoft's submission to the first shared task on sign language translation at WMT 2022, a public competition tackling sign language to spoken language translation for Swiss German sign language. The task is very challenging due to data scarcity and an unprecedented vocabulary size of more than 20k words on the target side. Moreover, the data is taken from real broadcast news, includes native signing and covers scenarios of long videos. Motivated by recent advances in action recognition, we incorporate full body information by extracting features from a pre-trained I3D model and applying a standard transformer network. The accuracy of the system is further improved by applying careful data cleaning on the target text. We obtain BLEU scores of 0.6 and 0.78 on the test and dev set respectively, which is the best score among the participants of the shared task. Also in the human evaluation the submission reaches the first place. The BLEU score is further improved to 1.08 on the dev set by applying features extracted from a lip reading model.
Dialectal Speech Recognition and Translation of Swiss German Speech to Standard German Text: Microsoft's Submission to SwissText 2021
Jul 01, 2021

This paper describes the winning approach in the Shared Task 3 at SwissText 2021 on Swiss German Speech to Standard German Text, a public competition on dialect recognition and translation. Swiss German refers to the multitude of Alemannic dialects spoken in the German-speaking parts of Switzerland. Swiss German differs significantly from standard German in pronunciation, word inventory and grammar. It is mostly incomprehensible to native German speakers. Moreover, it lacks a standardized written script. To solve the challenging task, we propose a hybrid automatic speech recognition system with a lexicon that incorporates translations, a 1st pass language model that deals with Swiss German particularities, a transfer-learned acoustic model and a strong neural language model for 2nd pass rescoring. Our submission reaches 46.04% BLEU on a blind conversational test set and outperforms the second best competitor by a 12% relative margin.
Attentive Modality Hopping Mechanism for Speech Emotion Recognition
Nov 29, 2019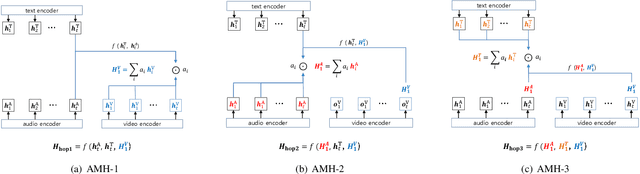
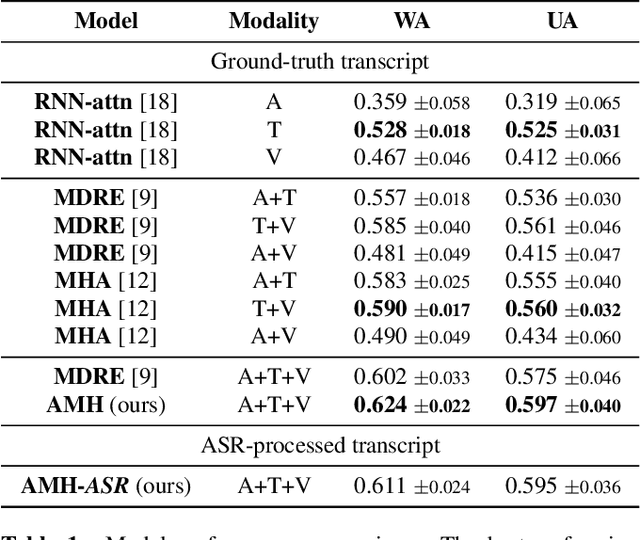
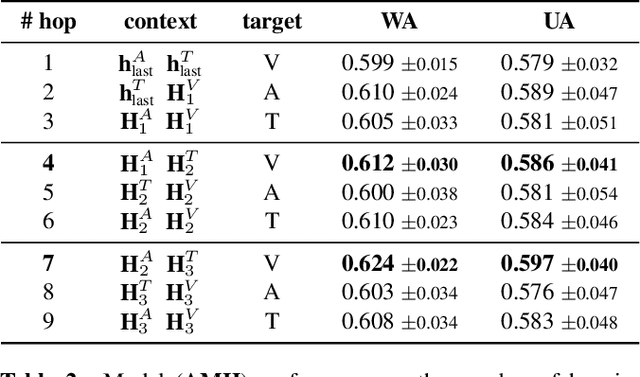
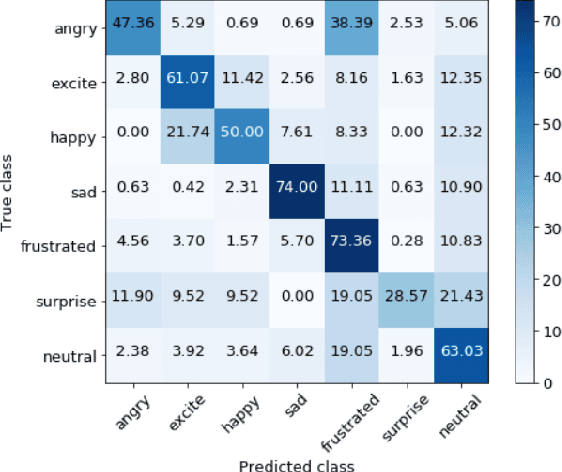
In this work, we explore the impact of visual modality in addition to speech and text for improving the accuracy of the emotion detection system. The traditional approaches tackle this task by fusing the knowledge from the various modalities independently for performing emotion classification. In contrast to these approaches, we tackle the problem by introducing an attention mechanism to combine the information. In this regard, we first apply a neural network to obtain hidden representations of the modalities. Then, the attention mechanism is defined to select and aggregate important parts of the video data by conditioning on the audio and text data. Furthermore, the attention mechanism is again applied to attend important parts of the speech and textual data, by considering other modality. Experiments are performed on the standard IEMOCAP dataset using all three modalities (audio, text, and video). The achieved results show a significant improvement of 3.65% in terms of weighted accuracy compared to the baseline system.
Exploiting semi-supervised training through a dropout regularization in end-to-end speech recognition
Aug 08, 2019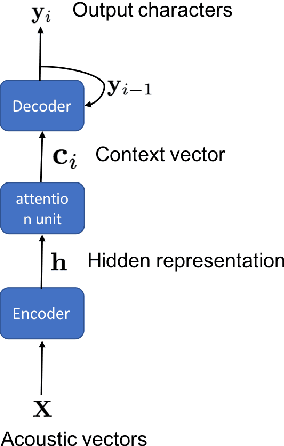
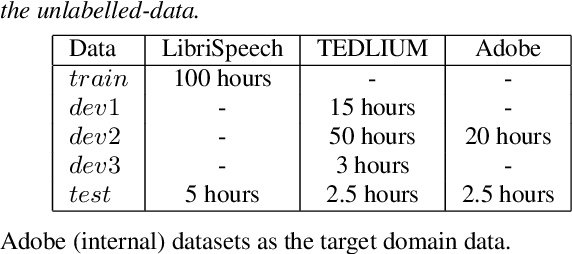
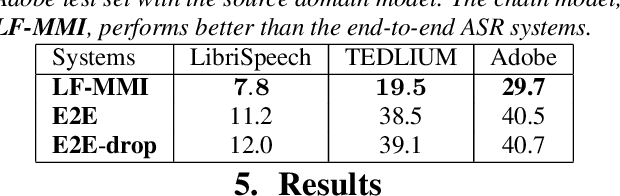

In this paper, we explore various approaches for semi supervised learning in an end to end automatic speech recognition (ASR) framework. The first step in our approach involves training a seed model on the limited amount of labelled data. Additional unlabelled speech data is employed through a data selection mechanism to obtain the best hypothesized output, further used to retrain the seed model. However, uncertainties of the model may not be well captured with a single hypothesis. As opposed to this technique, we apply a dropout mechanism to capture the uncertainty by obtaining multiple hypothesized text transcripts of an speech recording. We assume that the diversity of automatically generated transcripts for an utterance will implicitly increase the reliability of the model. Finally, the data selection process is also applied on these hypothesized transcripts to reduce the uncertainty. Experiments on freely available TEDLIUM corpus and proprietary Adobe's internal dataset show that the proposed approach significantly reduces ASR errors, compared to the baseline model.