 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Modality Hopping Mechanism for Speech Emotion Recognition
Paper and Code
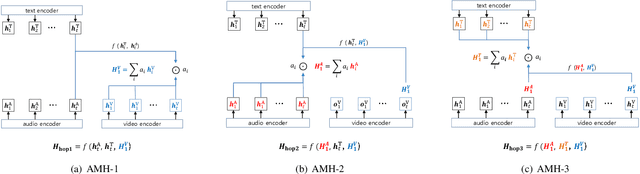
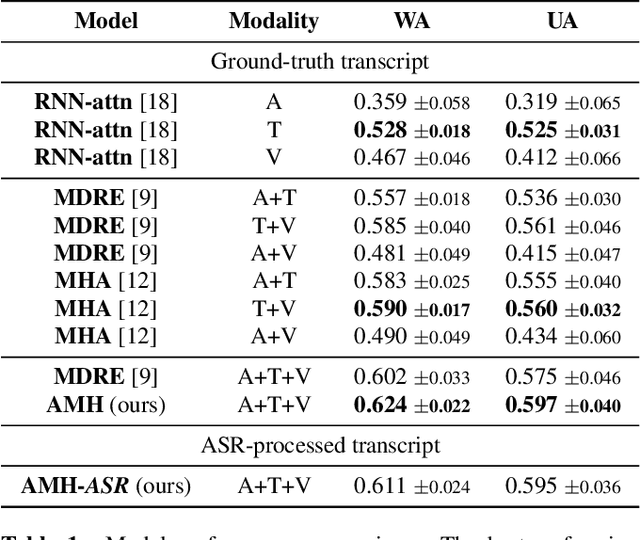
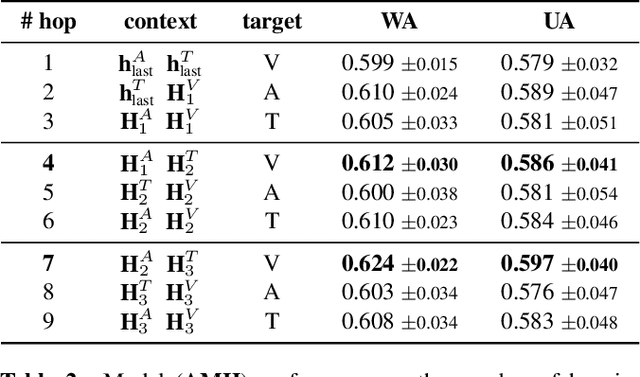
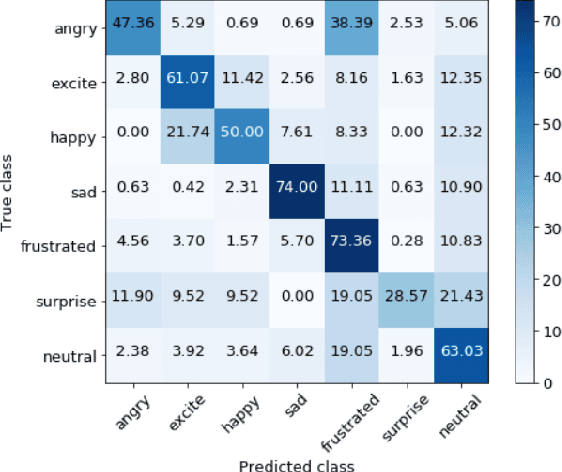
In this work, we explore the impact of visual modality in addition to speech and text for improving the accuracy of the emotion detection system. The traditional approaches tackle this task by fusing the knowledge from the various modalities independently for performing emotion classification. In contrast to these approaches, we tackle the problem by introducing an attention mechanism to combine the information. In this regard, we first apply a neural network to obtain hidden representations of the modalities. Then, the attention mechanism is defined to select and aggregate important parts of the video data by conditioning on the audio and text data. Furthermore, the attention mechanism is again applied to attend important parts of the speech and textual data, by considering other modality. Experiments are performed on the standard IEMOCAP dataset using all three modalities (audio, text, and video). The achieved results show a significant improvement of 3.65% in terms of weighted accuracy compared to the baseline system.