 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Signer Overlap for Sign Language Detection
Mar 19, 2023Sign language detection, identifying if someone is signing or not, is becoming crucially important for its applications in remote conferencing software and for selecting useful sign data for training sign language recognition or translation tasks. We argue that the current benchmark data sets for sign language detection estimate overly positive results that do not generalize well due to signer overlap between train and test partitions. We quantify this with a detailed analysis of the effect of signer overlap on current sign detection benchmark data sets. Comparing accuracy with and without overlap on the DGS corpus and Signing in the Wild, we observed a relative decrease in accuracy of 4.17% and 6.27%, respectively. Furthermore, we propose new data set partitions that are free of overlap and allow for more realistic performance assessment. We hope this work will contribute to improving the accuracy and generalization of sign language detection systems.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022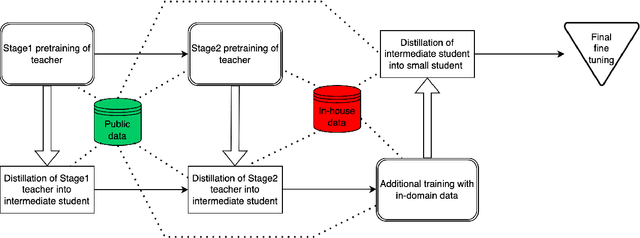
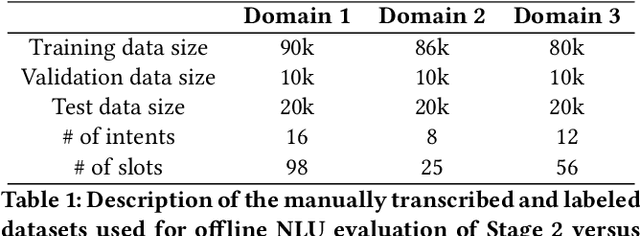
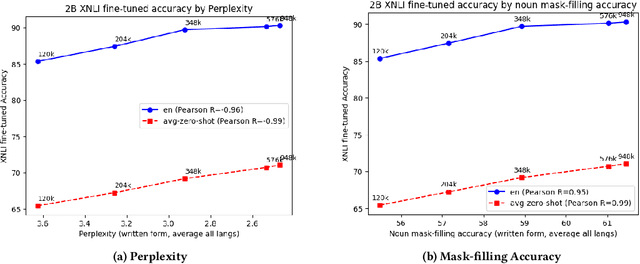
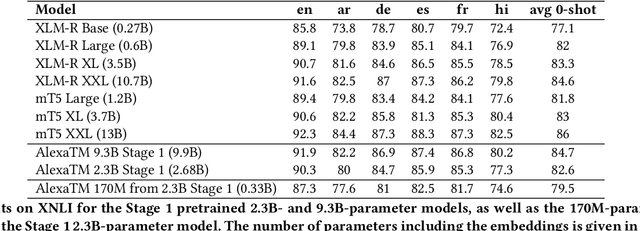
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022