 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Signer Overlap for Sign Language Detection
Mar 19, 2023



Sign language detection, identifying if someone is signing or not, is becoming crucially important for its applications in remote conferencing software and for selecting useful sign data for training sign language recognition or translation tasks. We argue that the current benchmark data sets for sign language detection estimate overly positive results that do not generalize well due to signer overlap between train and test partitions. We quantify this with a detailed analysis of the effect of signer overlap on current sign detection benchmark data sets. Comparing accuracy with and without overlap on the DGS corpus and Signing in the Wild, we observed a relative decrease in accuracy of 4.17% and 6.27%, respectively. Furthermore, we propose new data set partitions that are free of overlap and allow for more realistic performance assessment. We hope this work will contribute to improving the accuracy and generalization of sign language detection systems.
Multistage linguistic conditioning of convolutional layers for speech emotion recognition
Oct 13, 2021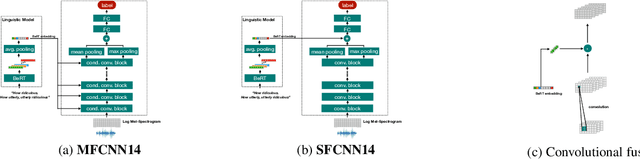
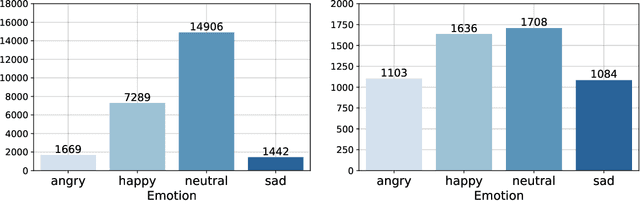
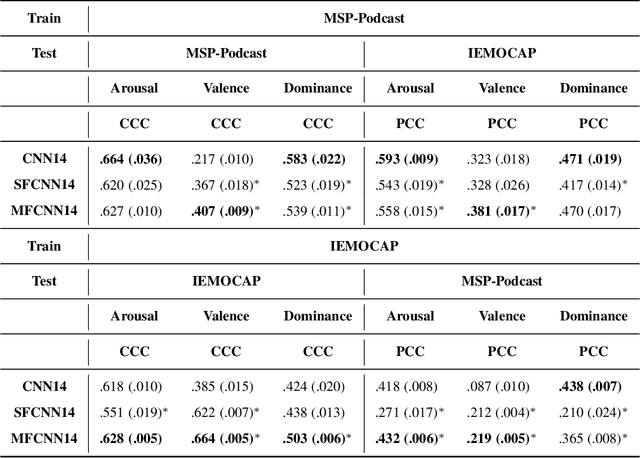
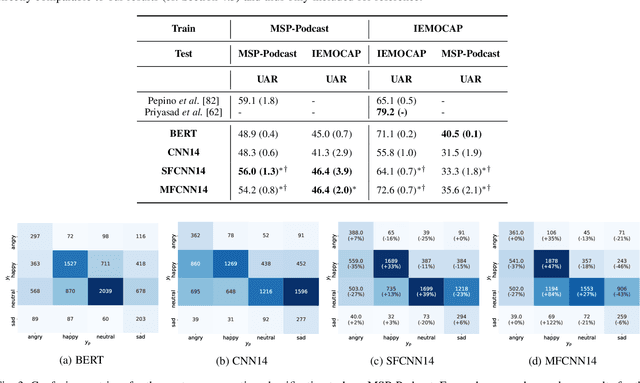
In this contribution, we investigate the effectiveness of deep fusion of text and audio features for categorical and dimensional speech emotion recognition (SER). We propose a novel, multistage fusion method where the two information streams are integrated in several layers of a deep neural network (DNN), and contrast it with a single-stage one where the streams are merged in a single point. Both methods depend on extracting summary linguistic embeddings from a pre-trained BERT model, and conditioning one or more intermediate representations of a convolutional model operating on log-Mel spectrograms. Experiments on the widely used IEMOCAP and MSP-Podcast databases demonstrate that the two fusion methods clearly outperform a shallow (late) fusion baseline and their unimodal constituents, both in terms of quantitative performance and qualitative behaviour. Our accompanying analysis further reveals a hitherto unexplored role of the underlying dialogue acts on unimodal and bimodal SER, with different models showing a biased behaviour across different acts. Overall, our multistage fusion shows better quantitative performance, surpassing all alternatives on most of our evaluations. This illustrates the potential of multistage fusion in better assimilating text and audio information.