 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Based Depressive Mood Detection in the Presence of Multiple Sclerosis: A Cross-Corpus and Cross-Lingual Study
Aug 25, 2025



Depression commonly co-occurs with neurodegenerative disorders like Multiple Sclerosis (MS), yet the potential of speech-based Artificial Intelligence for detecting depression in such contexts remains unexplored. This study examines the transferability of speech-based depression detection methods to people with MS (pwMS) through cross-corpus and cross-lingual analysis using English data from the general population and German data from pwMS. Our approach implements supervised machine learning models using: 1) conventional speech and language features commonly used in the field, 2) emotional dimensions derived from a Speech Emotion Recognition (SER) model, and 3) exploratory speech feature analysis. Despite limited data, our models detect depressive mood in pwMS with moderate generalisability, achieving a 66% Unweighted Average Recall (UAR) on a binary task. Feature selection further improved performance, boosting UAR to 74%. Our findings also highlight the relevant role emotional changes have as an indicator of depressive mood in both the general population and within PwMS. This study provides an initial exploration into generalising speech-based depression detection, even in the presence of co-occurring conditions, such as neurodegenerative diseases.
Going Retro: Astonishingly Simple Yet Effective Rule-based Prosody Modelling for Speech Synthesis Simulating Emotion Dimensions
Jul 05, 2023We introduce two rule-based models to modify the prosody of speech synthesis in order to modulate the emotion to be expressed. The prosody modulation is based on speech synthesis markup language (SSML) and can be used with any commercial speech synthesizer. The models as well as the optimization result are evaluated against human emotion annotations. Results indicate that with a very simple method both dimensions arousal (.76 UAR) and valence (.43 UAR) can be simulated.
Probing Speech Emotion Recognition Transformers for Linguistic Knowledge
Apr 01, 2022
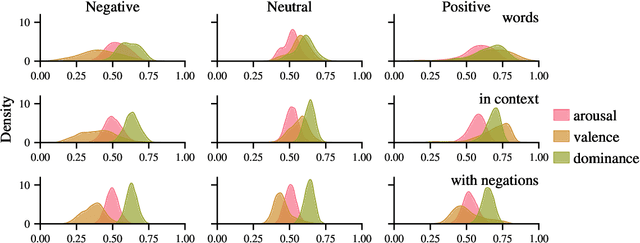
Large, pre-trained neural networks consisting of self-attention layers (transformers) have recently achieved state-of-the-art results on several speech emotion recognition (SER) datasets. These models are typically pre-trained in self-supervised manner with the goal to improve automatic speech recognition performance -- and thus, to understand linguistic information. In this work, we investigate the extent in which this information is exploited during SER fine-tuning. Using a reproducible methodology based on open-source tools, we synthesise prosodically neutral speech utterances while varying the sentiment of the text. Valence predictions of the transformer model are very reactive to positive and negative sentiment content, as well as negations, but not to intensifiers or reducers, while none of those linguistic features impact arousal or dominance. These findings show that transformers can successfully leverage linguistic information to improve their valence predictions, and that linguistic analysis should be included in their testing.
Multistage linguistic conditioning of convolutional layers for speech emotion recognition
Oct 13, 2021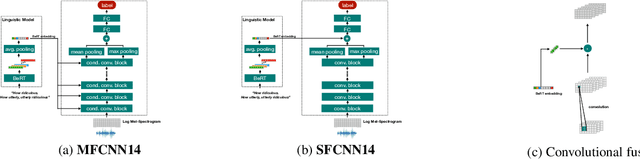
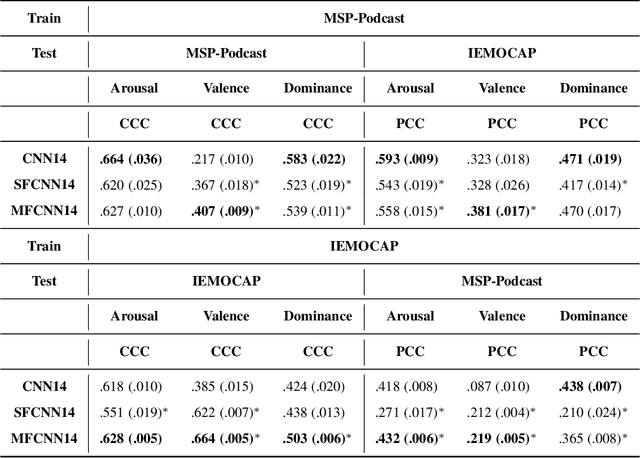
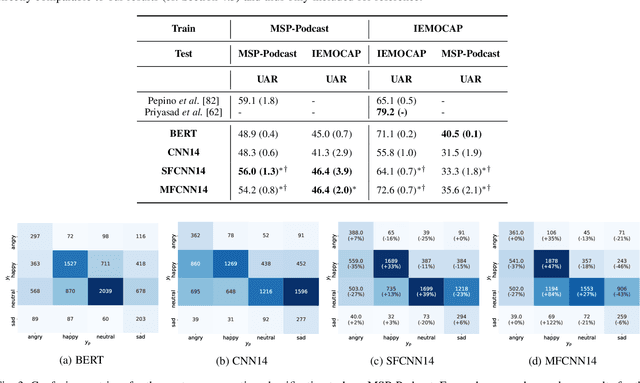
In this contribution, we investigate the effectiveness of deep fusion of text and audio features for categorical and dimensional speech emotion recognition (SER). We propose a novel, multistage fusion method where the two information streams are integrated in several layers of a deep neural network (DNN), and contrast it with a single-stage one where the streams are merged in a single point. Both methods depend on extracting summary linguistic embeddings from a pre-trained BERT model, and conditioning one or more intermediate representations of a convolutional model operating on log-Mel spectrograms. Experiments on the widely used IEMOCAP and MSP-Podcast databases demonstrate that the two fusion methods clearly outperform a shallow (late) fusion baseline and their unimodal constituents, both in terms of quantitative performance and qualitative behaviour. Our accompanying analysis further reveals a hitherto unexplored role of the underlying dialogue acts on unimodal and bimodal SER, with different models showing a biased behaviour across different acts. Overall, our multistage fusion shows better quantitative performance, surpassing all alternatives on most of our evaluations. This illustrates the potential of multistage fusion in better assimilating text and audio information.