 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Speech Emotion Recognition Transformers for Linguistic Knowledge
Apr 01, 2022
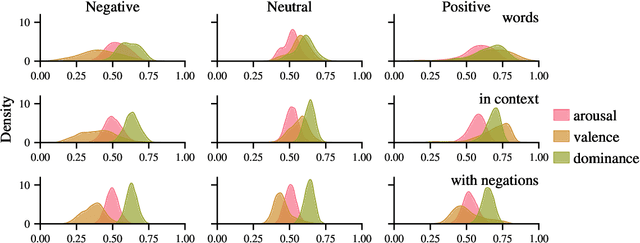
Large, pre-trained neural networks consisting of self-attention layers (transformers) have recently achieved state-of-the-art results on several speech emotion recognition (SER) datasets. These models are typically pre-trained in self-supervised manner with the goal to improve automatic speech recognition performance -- and thus, to understand linguistic information. In this work, we investigate the extent in which this information is exploited during SER fine-tuning. Using a reproducible methodology based on open-source tools, we synthesise prosodically neutral speech utterances while varying the sentiment of the text. Valence predictions of the transformer model are very reactive to positive and negative sentiment content, as well as negations, but not to intensifiers or reducers, while none of those linguistic features impact arousal or dominance. These findings show that transformers can successfully leverage linguistic information to improve their valence predictions, and that linguistic analysis should be included in their testing.
Dawn of the transformer era in speech emotion recognition: closing the valence gap
Mar 16, 2022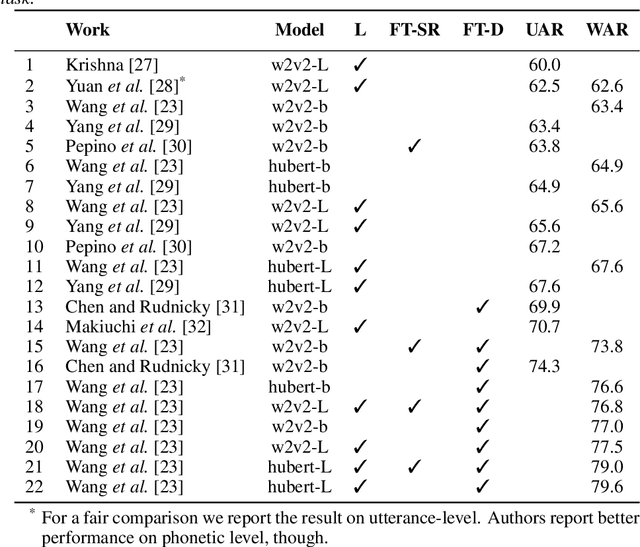
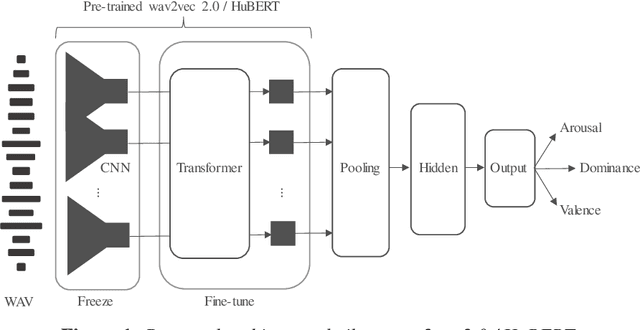
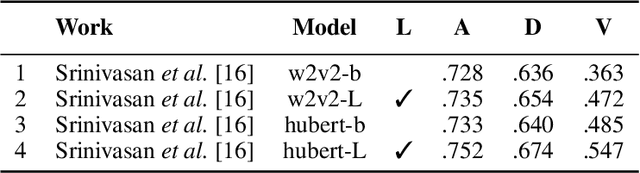
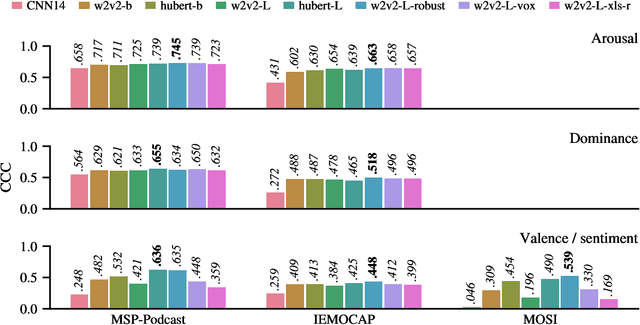
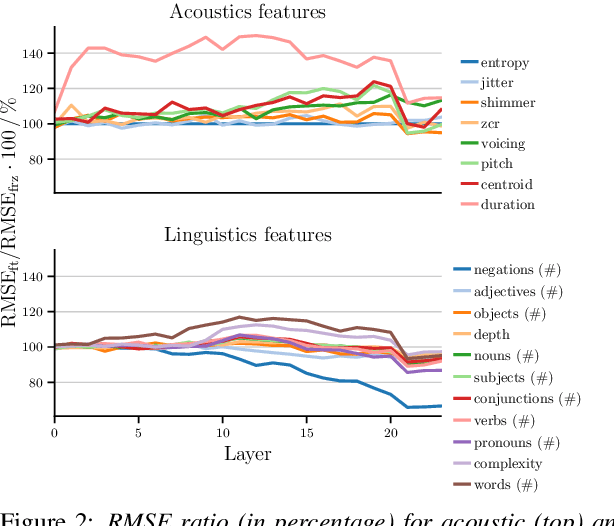
Recent advances in transformer-based architectures which are pre-trained in self-supervised manner have shown great promise in several machine learning tasks. In the audio domain, such architectures have also been successfully utilised in the field of speech emotion recognition (SER). However, existing works have not evaluated the influence of model size and pre-training data on downstream performance, and have shown limited attention to generalisation, robustness, fairness, and efficiency. The present contribution conducts a thorough analysis of these aspects on several pre-trained variants of wav2vec 2.0 and HuBERT that we fine-tuned on the dimensions arousal, dominance, and valence of MSP-Podcast, while additionally using IEMOCAP and MOSI to test cross-corpus generalisation. To the best of our knowledge, we obtain the top performance for valence prediction without use of explicit linguistic information, with a concordance correlation coefficient (CCC) of .638 on MSP-Podcast. Furthermore, our investigations reveal that transformer-based architectures are more robust to small perturbations compared to a CNN-based baseline and fair with respect to biological sex groups, but not towards individual speakers. Finally, we are the first to show that their extraordinary success on valence is based on implicit linguistic information learnt during fine-tuning of the transformer layers, which explains why they perform on-par with recent multimodal approaches that explicitly utilise textual information. Our findings collectively paint the following picture: transformer-based architectures constitute the new state-of-the-art in SER, but further advances are needed to mitigate remaining robustness and individual speaker issues. To make our findings reproducible, we release the best performing model to the community.
A German Corpus for Fine-Grained Named Entity Recognition and Relation Extraction of Traffic and Industry Events
Apr 07, 2020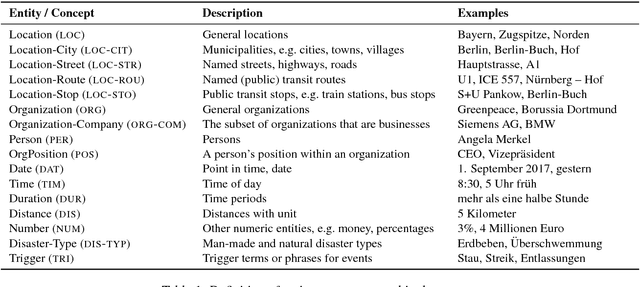


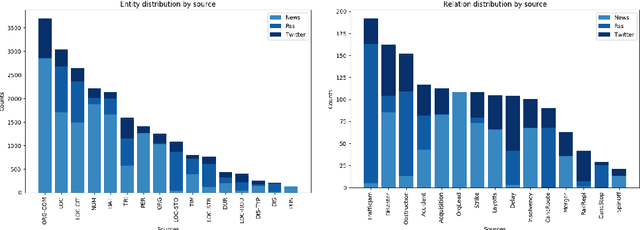
Monitoring mobility- and industry-relevant events is important in areas such as personal travel planning and supply chain management, but extracting events pertaining to specific companies, transit routes and locations from heterogeneous, high-volume text streams remains a significant challenge. This work describes a corpus of German-language documents which has been annotated with fine-grained geo-entities, such as streets, stops and routes, as well as standard named entity types. It has also been annotated with a set of 15 traffic- and industry-related n-ary relations and events, such as accidents, traffic jams, acquisitions, and strikes. The corpus consists of newswire texts, Twitter messages, and traffic reports from radio stations, police and railway companies. It allows for training and evaluating both named entity recognition algorithms that aim for fine-grained typing of geo-entities, as well as n-ary relation extraction systems.
AVEC 2019 Workshop and Challenge: State-of-Mind, Detecting Depression with AI, and Cross-Cultural Affect Recognition
Jul 10, 2019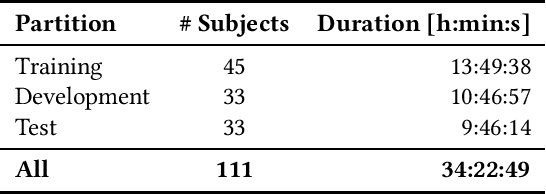
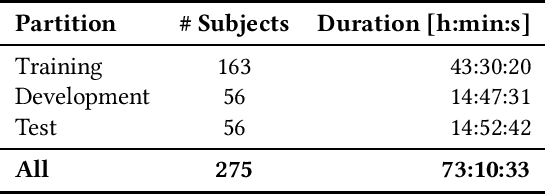
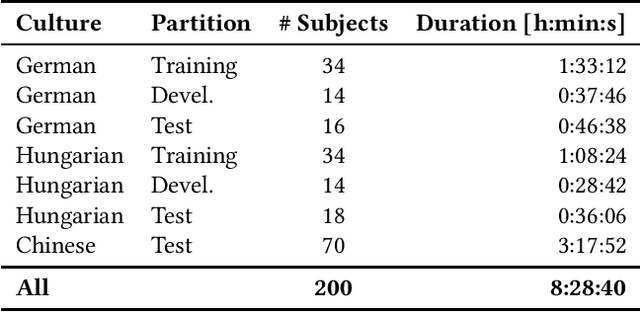
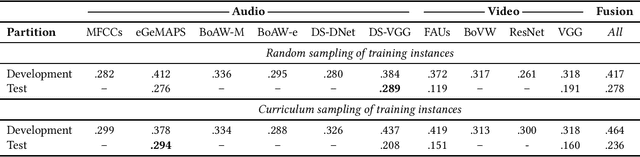
The Audio/Visual Emotion Challenge and Workshop (AVEC 2019) "State-of-Mind, Detecting Depression with AI, and Cross-cultural Affect Recognition" is the ninth competition event aimed at the comparison of multimedia processing and machine learning methods for automatic audiovisual health and emotion analysis, with all participants competing strictly under the same conditions. The goal of the Challenge is to provide a common benchmark test set for multimodal information processing and to bring together the health and emotion recognition communities, as well as the audiovisual processing communities, to compare the relative merits of various approaches to health and emotion recognition from real-life data. This paper presents the major novelties introduced this year, the challenge guidelines, the data used, and the performance of the baseline systems on the three proposed tasks: state-of-mind recognition, depression assessment with AI, and cross-cultural affect sensing, respectively.
SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild
Jan 09, 2019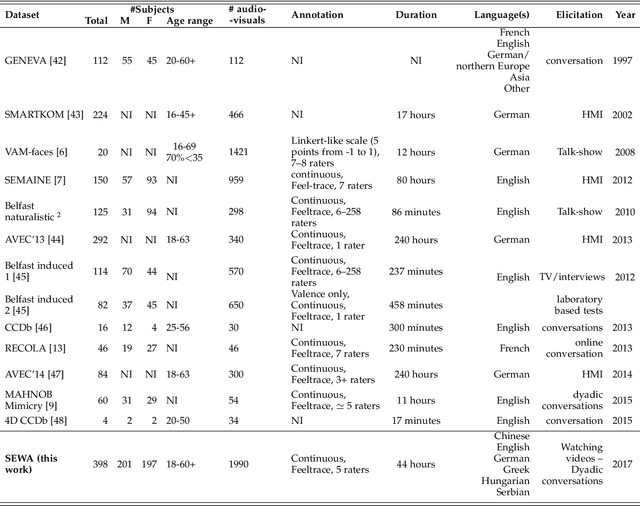
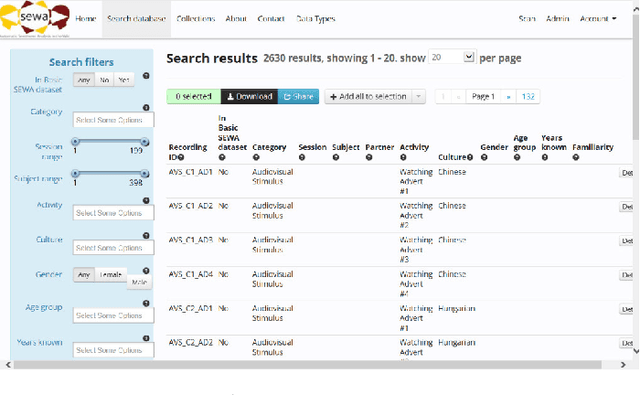
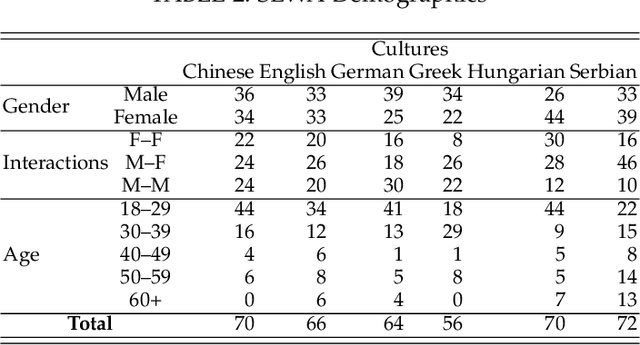

Natural human-computer interaction and audio-visual human behaviour sensing systems, which would achieve robust performance in-the-wild are more needed than ever as digital devices are becoming indispensable part of our life more and more. Accurately annotated real-world data are the crux in devising such systems. However, existing databases usually consider controlled settings, low demographic variability, and a single task. In this paper, we introduce the SEWA database of more than 2000 minutes of audio-visual data of 398 people coming from six cultures, 50% female, and uniformly spanning the age range of 18 to 65 years old. Subjects were recorded in two different contexts: while watching adverts and while discussing adverts in a video chat. The database includes rich annotations of the recordings in terms of facial landmarks, facial action units (FAU), various vocalisations, mirroring, and continuously valued valence, arousal, liking, agreement, and prototypic examples of (dis)liking. This database aims to be an extremely valuable resource for researchers in affective computing and automatic human sensing and is expected to push forward the research in human behaviour analysis, including cultural studies. Along with the database, we provide extensive baseline experiments for automatic FAU detection and automatic valence, arousal and (dis)liking intensity estimation.
Weakly Supervised One-Shot Detection with Attention Similarity Networks
Jun 27, 2018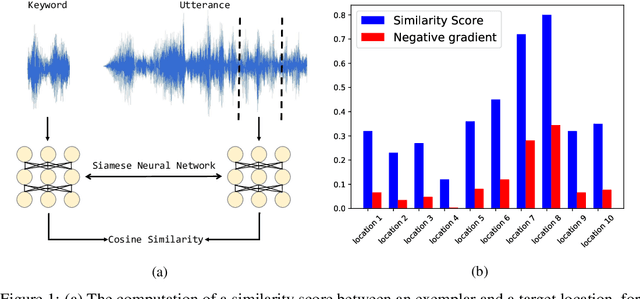
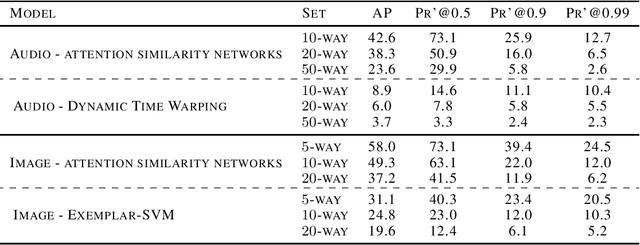

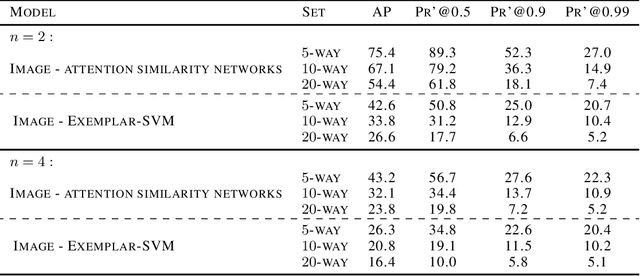
Neural network models that are not conditioned on class identities were shown to facilitate knowledge transfer between classes and to be well-suited for one-shot learning tasks. Following this motivation, we further explore and establish such models and present a novel neural network architecture for the task of weakly supervised one-shot detection. Our model is only conditioned on a single exemplar of an unseen class and a larger target example that may or may not contain an instance of the same class as the exemplar. By pairing a Siamese similarity network with an attention mechanism, we design a model that manages to simultaneously identify and localise instances of classes unseen at training time. In experiments with datasets from the computer vision and audio domains, the proposed method considerably outperforms the baseline methods for the weakly supervised one-shot detection task.
openXBOW - Introducing the Passau Open-Source Crossmodal Bag-of-Words Toolkit
May 22, 2016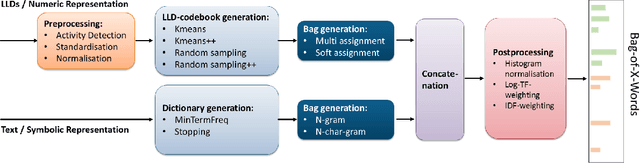

We introduce openXBOW, an open-source toolkit for the generation of bag-of-words (BoW) representations from multimodal input. In the BoW principle, word histograms were first used as features in document classification, but the idea was and can easily be adapted to, e.g., acoustic or visual low-level descriptors, introducing a prior step of vector quantisation. The openXBOW toolkit supports arbitrary numeric input features and text input and concatenates computed subbags to a final bag. It provides a variety of extensions and options. To our knowledge, openXBOW is the first publicly available toolkit for the generation of crossmodal bags-of-words. The capabilities of the tool are exemplified in two sample scenarios: time-continuous speech-based emotion recognition and sentiment analysis in tweets where improved results over other feature representation forms were observed.