 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
MultiTACRED: A Multilingual Version of the TAC Relation Extraction Dataset
May 15, 2023Relation extraction (RE) is a fundamental task in information extraction, whose extension to multilingual settings has been hindered by the lack of supervised resources comparable in size to large English datasets such as TACRED (Zhang et al., 2017). To address this gap, we introduce the MultiTACRED dataset, covering 12 typologically diverse languages from 9 language families, which is created by machine-translating TACRED instances and automatically projecting their entity annotations. We analyze translation and annotation projection quality, identify error categories, and experimentally evaluate fine-tuned pretrained mono- and multilingual language models in common transfer learning scenarios. Our analyses show that machine translation is a viable strategy to transfer RE instances, with native speakers judging more than 83% of the translated instances to be linguistically and semantically acceptable. We find monolingual RE model performance to be comparable to the English original for many of the target languages, and that multilingual models trained on a combination of English and target language data can outperform their monolingual counterparts. However, we also observe a variety of translation and annotation projection errors, both due to the MT systems and linguistic features of the target languages, such as pronoun-dropping, compounding and inflection, that degrade dataset quality and RE model performance.
Cross-lingual Approaches for the Detection of Adverse Drug Reactions in German from a Patient's Perspective
Aug 03, 2022
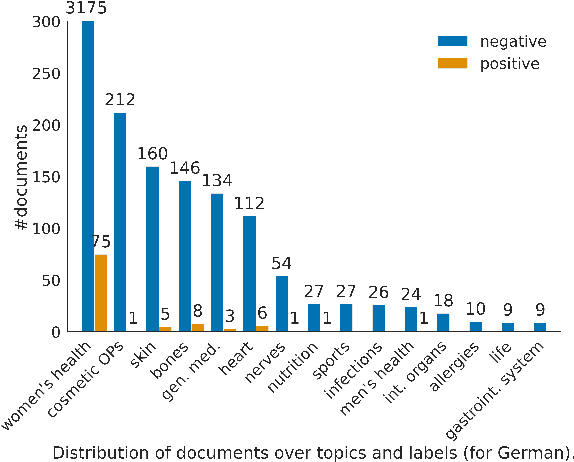

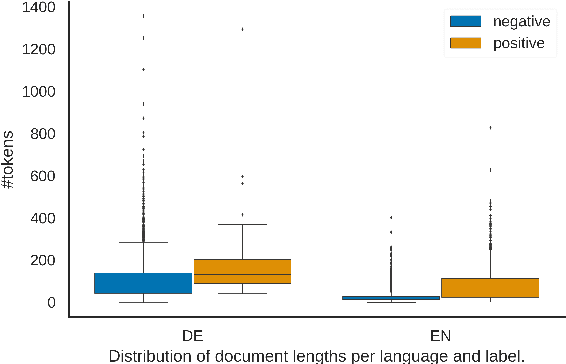
In this work, we present the first corpus for German Adverse Drug Reaction (ADR) detection in patient-generated content. The data consists of 4,169 binary annotated documents from a German patient forum, where users talk about health issues and get advice from medical doctors. As is common in social media data in this domain, the class labels of the corpus are very imbalanced. This and a high topic imbalance make it a very challenging dataset, since often, the same symptom can have several causes and is not always related to a medication intake. We aim to encourage further multi-lingual efforts in the domain of ADR detection and provide preliminary experiments for binary classification using different methods of zero- and few-shot learning based on a multi-lingual model. When fine-tuning XLM-RoBERTa first on English patient forum data and then on the new German data, we achieve an F1-score of 37.52 for the positive class. We make the dataset and models publicly available for the community.
SIA: A Scalable Interoperable Annotation Server for Biomedical Named Entities
Apr 08, 2020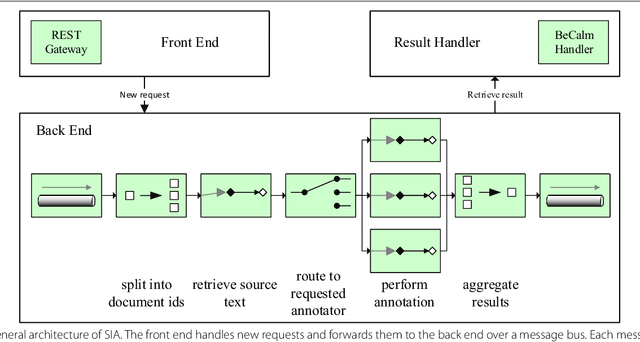
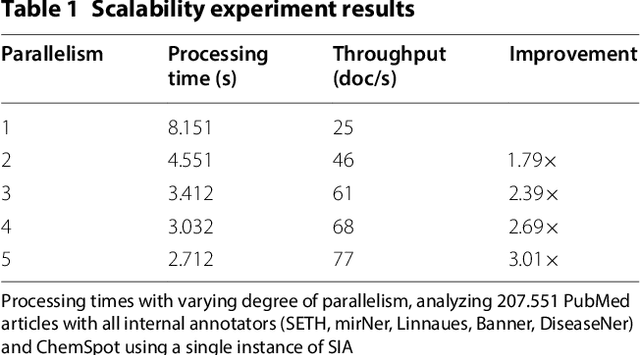
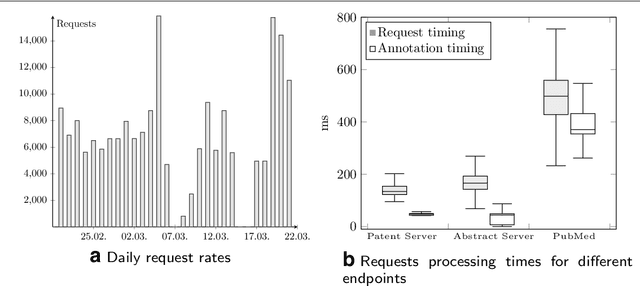
Recent years showed a strong increase in biomedical sciences and an inherent increase in publication volume. Extraction of specific information from these sources requires highly sophisticated text mining and information extraction tools. However, the integration of freely available tools into customized workflows is often cumbersome and difficult. We describe SIA (Scalable Interoperable Annotation Server), our contribution to the BeCalm-Technical interoperability and performance of annotation servers (BeCalm-TIPS) task, a scalable, extensible, and robust annotation service. The system currently covers six named entity types (i.e., Chemicals, Diseases, Genes, miRNA, Mutations, and Organisms) and is freely available under Apache 2.0 license at https://github.com/Erechtheus/sia.
* 11 pages, 2 figures, published in Journal of Cheminformatics
A German Corpus for Fine-Grained Named Entity Recognition and Relation Extraction of Traffic and Industry Events
Apr 07, 2020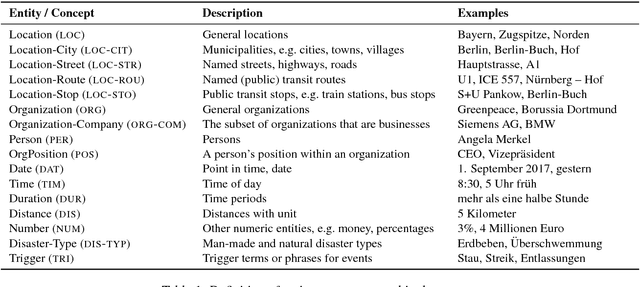


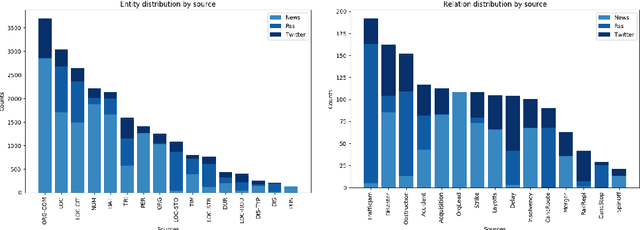
Monitoring mobility- and industry-relevant events is important in areas such as personal travel planning and supply chain management, but extracting events pertaining to specific companies, transit routes and locations from heterogeneous, high-volume text streams remains a significant challenge. This work describes a corpus of German-language documents which has been annotated with fine-grained geo-entities, such as streets, stops and routes, as well as standard named entity types. It has also been annotated with a set of 15 traffic- and industry-related n-ary relations and events, such as accidents, traffic jams, acquisitions, and strikes. The corpus consists of newswire texts, Twitter messages, and traffic reports from radio stations, police and railway companies. It allows for training and evaluating both named entity recognition algorithms that aim for fine-grained typing of geo-entities, as well as n-ary relation extraction systems.
Using a Classifier Ensemble for Proactive Quality Monitoring and Control: the impact of the choice of classifiers types, selection criterion, and fusion process
Apr 05, 2018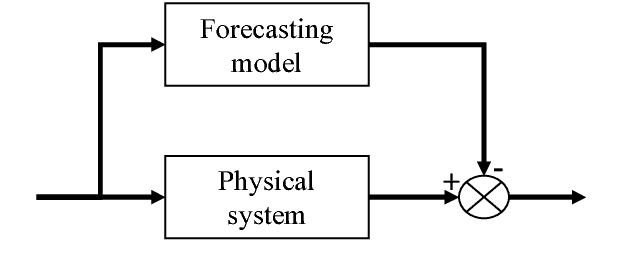

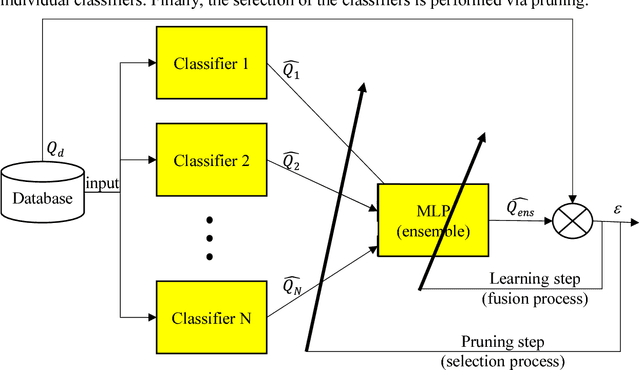
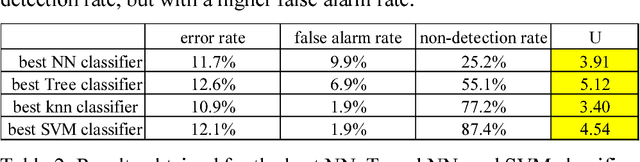
In recent times, the manufacturing processes are faced with many external or internal (the increase of customized product rescheduling , process reliability,..) changes. Therefore, monitoring and quality management activities for these manufacturing processes are difficult. Thus, the managers need more proactive approaches to deal with this variability. In this study, a proactive quality monitoring and control approach based on classifiers to predict defect occurrences and provide optimal values for factors critical to the quality processes is proposed. In a previous work (Noyel et al. 2013), the classification approach had been used in order to improve the quality of a lacquering process at a company plant; the results obtained are promising, but the accuracy of the classification model used needs to be improved. One way to achieve this is to construct a committee of classifiers (referred to as an ensemble) to obtain a better predictive model than its constituent models. However, the selection of the best classification methods and the construction of the final ensemble still poses a challenging issue. In this study, we focus and analyze the impact of the choice of classifier types on the accuracy of the classifier ensemble; in addition, we explore the effects of the selection criterion and fusion process on the ensemble accuracy as well. Several fusion scenarios were tested and compared based on a real-world case. Our results show that using an ensemble classification leads to an increase in the accuracy of the classifier models. Consequently, the monitoring and control of the considered real-world case can be improved.
Clickbait Identification using Neural Networks
Oct 24, 2017
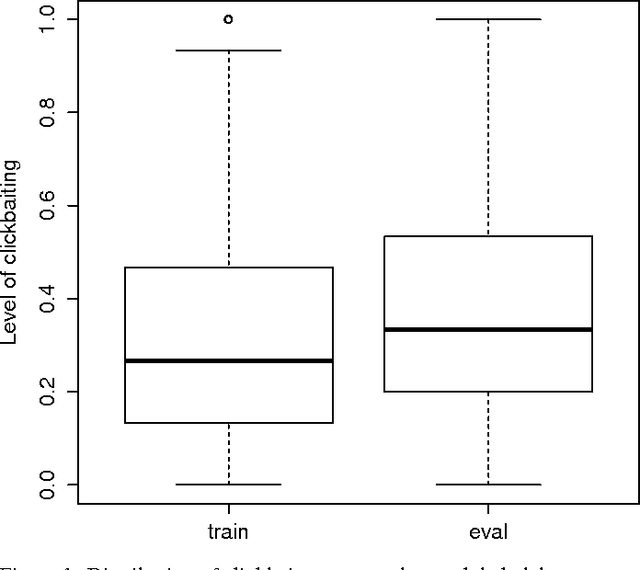
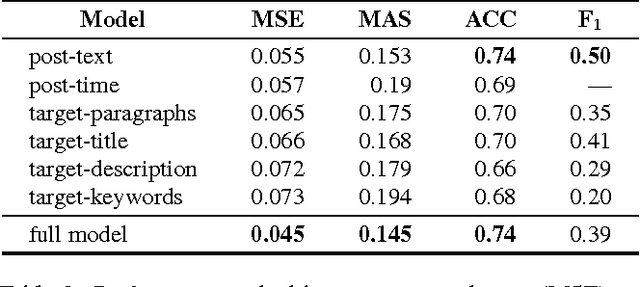
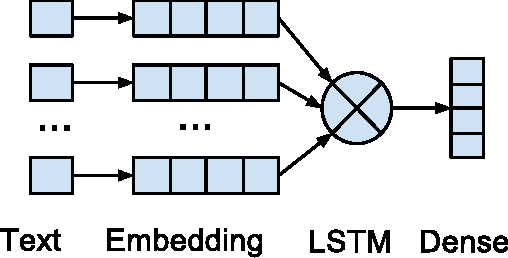
This paper presents the results of our participation in the Clickbait Detection Challenge 2017. The system relies on a fusion of neural networks, incorporating different types of available informations. It does not require any linguistic preprocessing, and hence generalizes more easily to new domains and languages. The final combined model achieves a mean squared error of 0.0428, an accuracy of 0.826, and a F1 score of 0.564. According to the official evaluation metric the system ranked 6th of the 13 participating teams.
An iterative closest point method for measuring the level of similarity of 3d log scans in wood industry
Oct 23, 2017
In the Canadian's lumber industry, simulators are used to predict the lumbers resulting from the sawing of a log at a given sawmill. Giving a log or several logs' 3D scans as input, simulators perform a real-time job to predict the lumbers. These simulators, however, tend to be slow at processing large volume of wood. We thus explore an alternative approximation techniques based on the Iterative Closest Point (ICP) algorithm to identify the already processed log to which an unseen log resembles the most. The main benefit of the ICP approach is that it can easily handle 3D scans with a variable number of points. We compare this ICP-based nearest neighbor predictor, to predictors built using machine learning algorithms such as the K-nearest-neighbor (kNN) and Random Forest (RF). The implemented ICP-based predictor enabled us to identify key points in using the 3D scans directly for distance calculation. The long-term goal of this ongoing research is to integrated ICP distance calculations and machine learning.
A batching and scheduling optimisation for a cutting work-center: Acta-Mobilier case study
Oct 11, 2017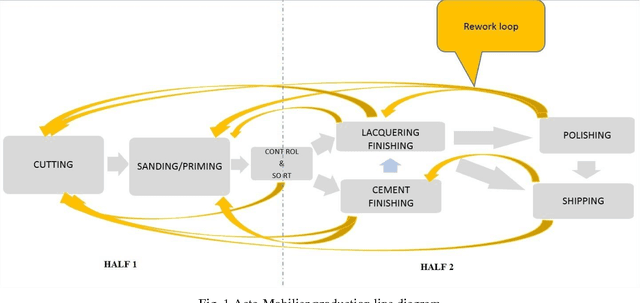
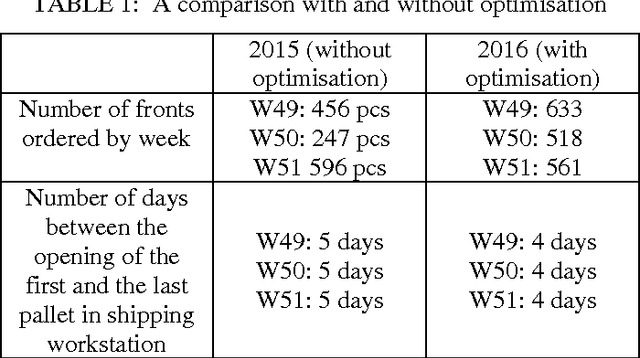
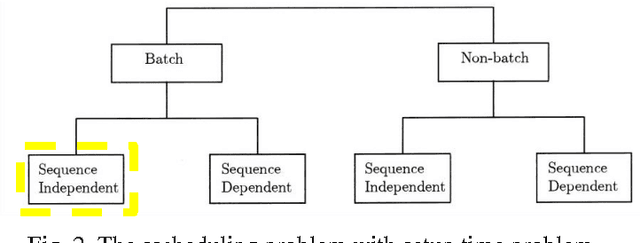
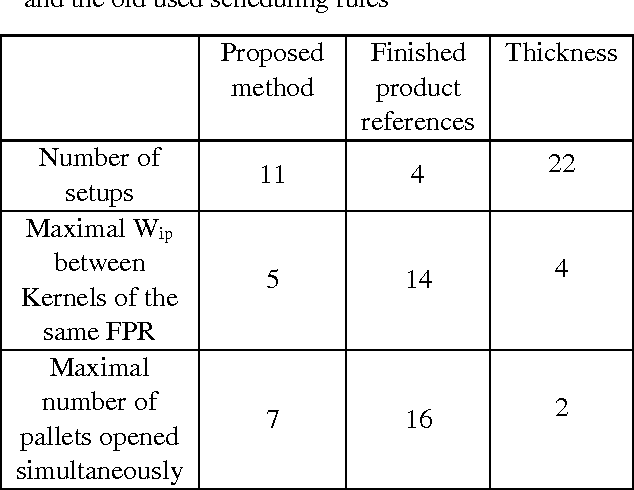
The purpose of this study is to investigate an approach to group lots in batches and to schedule these batches on Acta-Mobilier cutting work-center while taking into account numerous constraints and objectives. The specific batching method was proposed to handle the Acta-Mobilier problem and a mathematical formalisation and genetic algorithm were proposed to deal with the scheduling problem. The proposed algorithm has been embedded in software to optimise production costs and emphasis the visual management on the production line. The application is currently being used in Acta-Mobilier plant and shows significant results
How deals with discrete data for the reduction of simulation models using neural network
Jun 10, 2009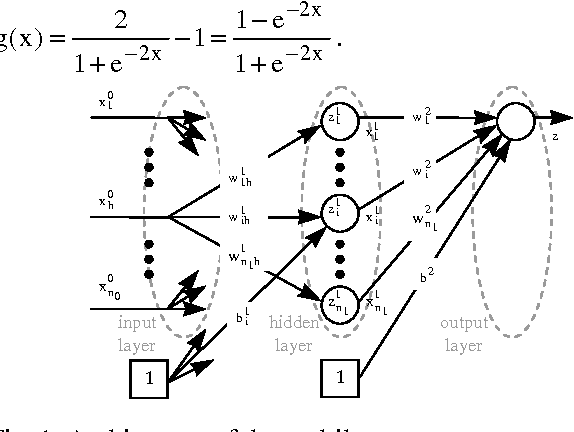
Simulation is useful for the evaluation of a Master Production/distribution Schedule (MPS). Also, the goal of this paper is the study of the design of a simulation model by reducing its complexity. According to theory of constraints, we want to build reduced models composed exclusively by bottlenecks and a neural network. Particularly a multilayer perceptron, is used. The structure of the network is determined by using a pruning procedure. This work focuses on the impact of discrete data on the results and compares different approaches to deal with these data. This approach is applied to sawmill internal supply chain