 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
Decorate the Examples: A Simple Method of Prompt Design for Biomedical Relation Extraction
Apr 21, 2022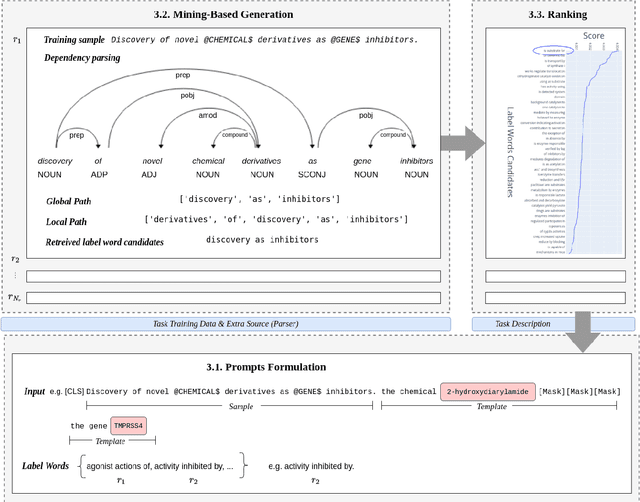
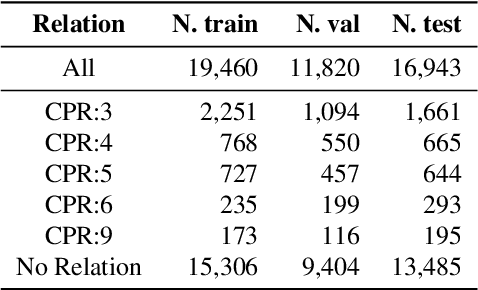
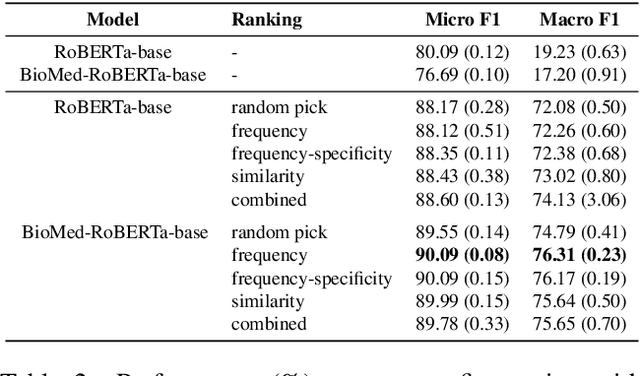
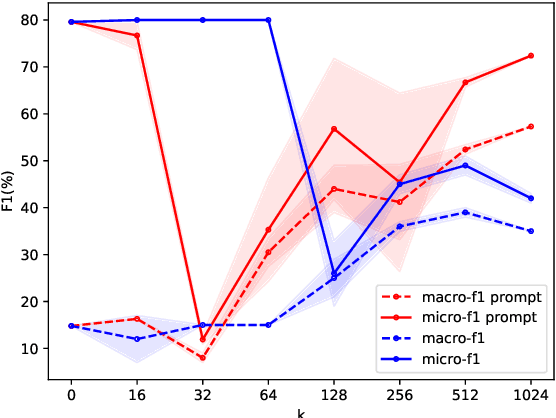
Relation extraction is a core problem for natural language processing in the biomedical domain. Recent research on relation extraction showed that prompt-based learning improves the performance on both fine-tuning on full training set and few-shot training. However, less effort has been made on domain-specific tasks where good prompt design can be even harder. In this paper, we investigate prompting for biomedical relation extraction, with experiments on the ChemProt dataset. We present a simple yet effective method to systematically generate comprehensive prompts that reformulate the relation extraction task as a cloze-test task under a simple prompt formulation. In particular, we experiment with different ranking scores for prompt selection. With BioMed-RoBERTa-base, our results show that prompting-based fine-tuning obtains gains by 14.21 F1 over its regular fine-tuning baseline, and 1.14 F1 over SciFive-Large, the current state-of-the-art on ChemProt. Besides, we find prompt-based learning requires fewer training examples to make reasonable predictions. The results demonstrate the potential of our methods in such a domain-specific relation extraction task.
Time-Aware Ancient Chinese Text Translation and Inference
Jul 07, 2021



In this paper, we aim to address the challenges surrounding the translation of ancient Chinese text: (1) The linguistic gap due to the difference in eras results in translations that are poor in quality, and (2) most translations are missing the contextual information that is often very crucial to understanding the text. To this end, we improve upon past translation techniques by proposing the following: We reframe the task as a multi-label prediction task where the model predicts both the translation and its particular era. We observe that this helps to bridge the linguistic gap as chronological context is also used as auxiliary information. % As a natural step of generalization, we pivot on the modern Chinese translations to generate multilingual outputs. %We show experimentally the efficacy of our framework in producing quality translation outputs and also validate our framework on a collected task-specific parallel corpus. We validate our framework on a parallel corpus annotated with chronology information and show experimentally its efficacy in producing quality translation outputs. We release both the code and the data https://github.com/orina1123/time-aware-ancient-text-translation for future research.
On Training Instance Selection for Few-Shot Neural Text Generation
Jul 07, 2021



Large-scale pretrained language models have led to dramatic improvements in text generation. Impressive performance can be achieved by finetuning only on a small number of instances (few-shot setting). Nonetheless, almost all previous work simply applies random sampling to select the few-shot training instances. Little to no attention has been paid to the selection strategies and how they would affect model performance. In this work, we present a study on training instance selection in few-shot neural text generation. The selection decision is made based only on the unlabeled data so as to identify the most worthwhile data points that should be annotated under some budget of labeling cost. Based on the intuition that the few-shot training instances should be diverse and representative of the entire data distribution, we propose a simple selection strategy with K-means clustering. We show that even with the naive clustering-based approach, the generation models consistently outperform random sampling on three text generation tasks: data-to-text generation, document summarization and question generation. We hope that this work will call for more attention on this largely unexplored area.
Does the Order of Training Samples Matter? Improving Neural Data-to-Text Generation with Curriculum Learning
Feb 06, 2021



Recent advancements in data-to-text generation largely take on the form of neural end-to-end systems. Efforts have been dedicated to improving text generation systems by changing the order of training samples in a process known as curriculum learning. Past research on sequence-to-sequence learning showed that curriculum learning helps to improve both the performance and convergence speed. In this work, we delve into the same idea surrounding the training samples consisting of structured data and text pairs, where at each update, the curriculum framework selects training samples based on the model's competence. Specifically, we experiment with various difficulty metrics and put forward a soft edit distance metric for ranking training samples. Our benchmarks show faster convergence speed where training time is reduced by 38.7% and performance is boosted by 4.84 BLEU.