 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfherno: End-to-end Agent-based FHIR Resource Synthesis from Free-form Clinical Notes
Jul 16, 2025For clinical data integration and healthcare services, the HL7 FHIR standard has established itself as a desirable format for interoperability between complex health data. Previous attempts at automating the translation from free-form clinical notes into structured FHIR resources rely on modular, rule-based systems or LLMs with instruction tuning and constrained decoding. Since they frequently suffer from limited generalizability and structural inconformity, we propose an end-to-end framework powered by LLM agents, code execution, and healthcare terminology database tools to address these issues. Our solution, called Infherno, is designed to adhere to the FHIR document schema and competes well with a human baseline in predicting FHIR resources from unstructured text. The implementation features a front end for custom and synthetic data and both local and proprietary models, supporting clinical data integration processes and interoperability across institutions.
Beyond De-Identification: A Structured Approach for Defining and Detecting Indirect Identifiers in Medical Texts
Feb 18, 2025
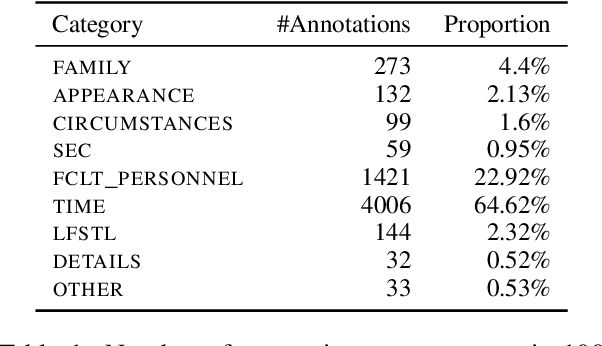
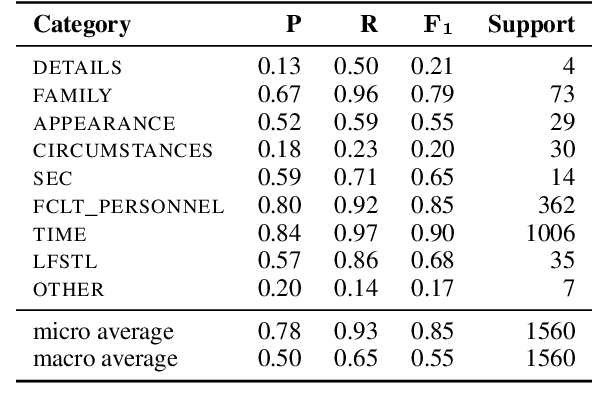

Sharing sensitive texts for scientific purposes requires appropriate techniques to protect the privacy of patients and healthcare personnel. Anonymizing textual data is particularly challenging due to the presence of diverse unstructured direct and indirect identifiers. To mitigate the risk of re-identification, this work introduces a schema of nine categories of indirect identifiers designed to account for different potential adversaries, including acquaintances, family members and medical staff. Using this schema, we annotate 100 MIMIC-III discharge summaries and propose baseline models for identifying indirect identifiers. We will release the annotation guidelines, annotation spans (6,199 annotations in total) and the corresponding MIMIC-III document IDs to support further research in this area.
Evaluating the Robustness of Adverse Drug Event Classification Models Using Templates
Jul 02, 2024



An adverse drug effect (ADE) is any harmful event resulting from medical drug treatment. Despite their importance, ADEs are often under-reported in official channels. Some research has therefore turned to detecting discussions of ADEs in social media. Impressive results have been achieved in various attempts to detect ADEs. In a high-stakes domain such as medicine, however, an in-depth evaluation of a model's abilities is crucial. We address the issue of thorough performance evaluation in English-language ADE detection with hand-crafted templates for four capabilities: Temporal order, negation, sentiment, and beneficial effect. We find that models with similar performance on held-out test sets have varying results on these capabilities.
DFKI-NLP at SemEval-2024 Task 2: Towards Robust LLMs Using Data Perturbations and MinMax Training
May 01, 2024
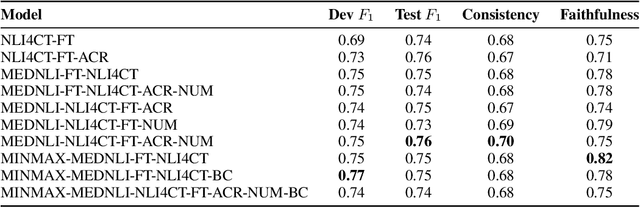

The NLI4CT task at SemEval-2024 emphasizes the development of robust models for Natural Language Inference on Clinical Trial Reports (CTRs) using large language models (LLMs). This edition introduces interventions specifically targeting the numerical, vocabulary, and semantic aspects of CTRs. Our proposed system harnesses the capabilities of the state-of-the-art Mistral model, complemented by an auxiliary model, to focus on the intricate input space of the NLI4CT dataset. Through the incorporation of numerical and acronym-based perturbations to the data, we train a robust system capable of handling both semantic-altering and numerical contradiction interventions. Our analysis on the dataset sheds light on the challenging sections of the CTRs for reasoning.
A Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
Cross-lingual Approaches for the Detection of Adverse Drug Reactions in German from a Patient's Perspective
Aug 03, 2022
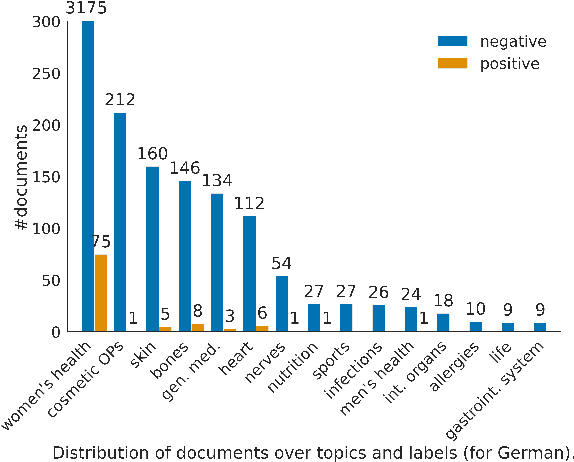

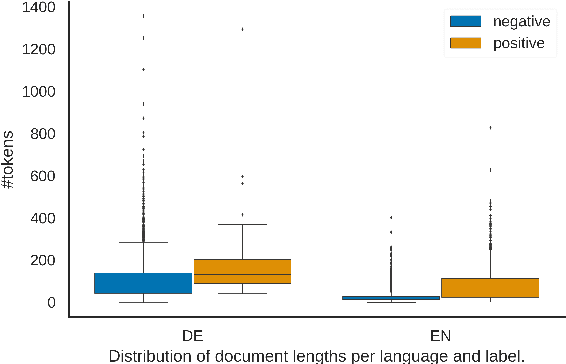
In this work, we present the first corpus for German Adverse Drug Reaction (ADR) detection in patient-generated content. The data consists of 4,169 binary annotated documents from a German patient forum, where users talk about health issues and get advice from medical doctors. As is common in social media data in this domain, the class labels of the corpus are very imbalanced. This and a high topic imbalance make it a very challenging dataset, since often, the same symptom can have several causes and is not always related to a medication intake. We aim to encourage further multi-lingual efforts in the domain of ADR detection and provide preliminary experiments for binary classification using different methods of zero- and few-shot learning based on a multi-lingual model. When fine-tuning XLM-RoBERTa first on English patient forum data and then on the new German data, we achieve an F1-score of 37.52 for the positive class. We make the dataset and models publicly available for the community.
Neural Vector Conceptualization for Word Vector Space Interpretation
Apr 02, 2019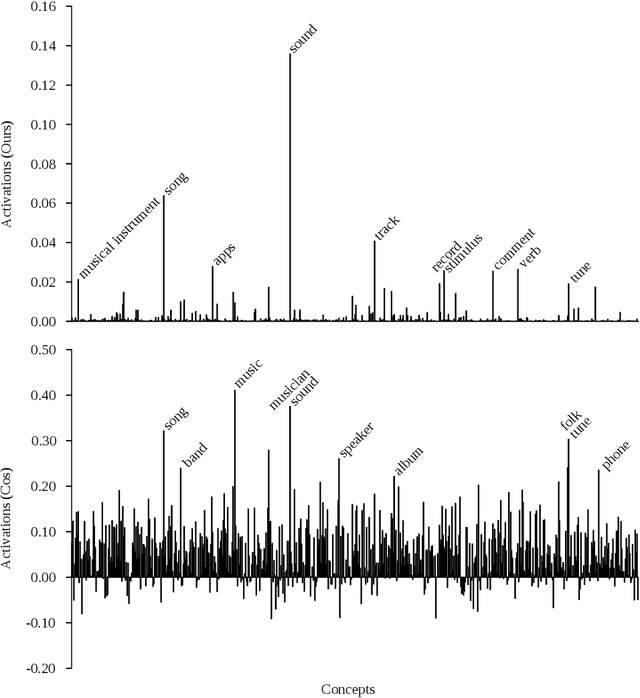
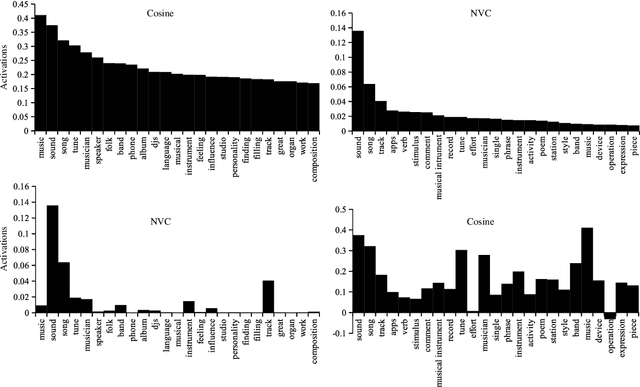
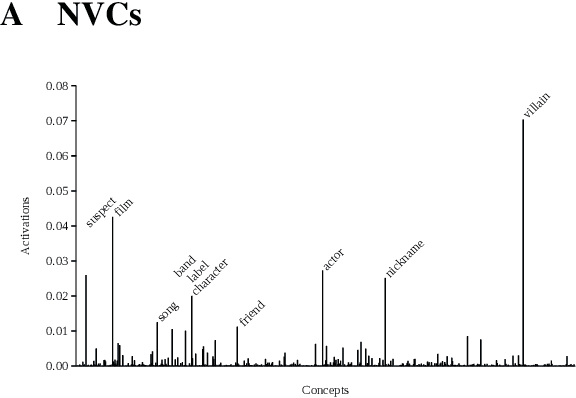
Distributed word vector spaces are considered hard to interpret which hinders the understanding of natural language processing (NLP) models. In this work, we introduce a new method to interpret arbitrary samples from a word vector space. To this end, we train a neural model to conceptualize word vectors, which means that it activates higher order concepts it recognizes in a given vector. Contrary to prior approaches, our model operates in the original vector space and is capable of learning non-linear relations between word vectors and concepts. Furthermore, we show that it produces considerably less entropic concept activation profiles than the popular cosine similarity.