 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Atomic Propositions help weak extractors: Evaluation of a Propositioner for triplet extraction
Apr 03, 2026Knowledge Graph construction from natural language requires extracting structured triplets from complex, information-dense sentences. In this paper, we investigate if the decomposition of text into atomic propositions (minimal, semantically autonomous units of information) can improve the triplet extraction. We introduce MPropositionneur-V2, a small multilingual model covering six European languages trained by knowledge distillation from Qwen3-32B into a Qwen3-0.6B architecture, and we evaluate its integration into two extraction paradigms: entity-centric (GLiREL) and generative (Qwen3). Experiments on SMiLER, FewRel, DocRED and CaRB show that atomic propositions benefit weaker extractors (GLiREL, CoreNLP, 0.6B models), improving relation recall and, in the multilingual setting, overall accuracy. For stronger LLMs, a fallback combination strategy recovers entity recall losses while preserving the gains in relation extraction. These results show that atomic propositions are an interpretable intermediate data structure that complements extractors without replacing them.
Evaluation of Clinical Trials Reporting Quality using Large Language Models
Oct 05, 2025Reporting quality is an important topic in clinical trial research articles, as it can impact clinical decisions. In this article, we test the ability of large language models to assess the reporting quality of this type of article using the Consolidated Standards of Reporting Trials (CONSORT). We create CONSORT-QA, an evaluation corpus from two studies on abstract reporting quality with CONSORT-abstract standards. We then evaluate the ability of different large generative language models (from the general domain or adapted to the biomedical domain) to correctly assess CONSORT criteria with different known prompting methods, including Chain-of-thought. Our best combination of model and prompting method achieves 85% accuracy. Using Chain-of-thought adds valuable information on the model's reasoning for completing the task.
Pre-training data selection for biomedical domain adaptation using journal impact metrics
Sep 04, 2024
Domain adaptation is a widely used method in natural language processing (NLP) to improve the performance of a language model within a specific domain. This method is particularly common in the biomedical domain, which sees regular publication of numerous scientific articles. PubMed, a significant corpus of text, is frequently used in the biomedical domain. The primary objective of this study is to explore whether refining a pre-training dataset using specific quality metrics for scientific papers can enhance the performance of the resulting model. To accomplish this, we employ two straightforward journal impact metrics and conduct experiments by continually pre-training BERT on various subsets of the complete PubMed training set, we then evaluate the resulting models on biomedical language understanding tasks from the BLURB benchmark. Our results show that pruning using journal impact metrics is not efficient. But we also show that pre-training using fewer abstracts (but with the same number of training steps) does not necessarily decrease the resulting model's performance.
A Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
Chitchat as Interference: Adding User Backstories to Task-Oriented Dialogues
Feb 23, 2024

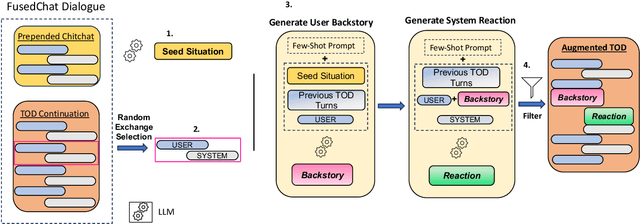

During task-oriented dialogues (TODs), human users naturally introduce chitchat that is beyond the immediate scope of the task, interfering with the flow of the conversation. To address this issue without the need for expensive manual data creation, we use few-shot prompting with Llama-2-70B to enhance the MultiWOZ dataset with user backstories, a typical example of chitchat interference in TODs. We assess the impact of this addition by testing two models: one trained solely on TODs and another trained on TODs with a preliminary chitchat interaction. Our analysis reveals that our enriched dataset poses a significant challenge to these systems. Moreover, we demonstrate that our dataset can be effectively used for training purposes, enabling a system to consistently acknowledge the user's backstory while also successfully moving the task forward in the same turn, as confirmed by human evaluation. These findings highlight the benefits of generating novel chitchat-TOD scenarios to test TOD systems more thoroughly and improve their resilience to natural user interferences.
A Unified Approach to Emotion Detection and Task-Oriented Dialogue Modeling
Jan 24, 2024In current text-based task-oriented dialogue (TOD) systems, user emotion detection (ED) is often overlooked or is typically treated as a separate and independent task, requiring additional training. In contrast, our work demonstrates that seamlessly unifying ED and TOD modeling brings about mutual benefits, and is therefore an alternative to be considered. Our method consists in augmenting SimpleToD, an end-to-end TOD system, by extending belief state tracking to include ED, relying on a single language model. We evaluate our approach using GPT-2 and Llama-2 on the EmoWOZ benchmark, a version of MultiWOZ annotated with emotions. Our results reveal a general increase in performance for ED and task results. Our findings also indicate that user emotions provide useful contextual conditioning for system responses, and can be leveraged to further refine responses in terms of empathy.
Enhancing Task-Oriented Dialogues with Chitchat: a Comparative Study Based on Lexical Diversity and Divergence
Nov 23, 2023



As a recent development, task-oriented dialogues (TODs) have been enriched with chitchat in an effort to make dialogues more diverse and engaging. This enhancement is particularly valuable as TODs are often confined to narrow domains, making the mitigation of repetitive and predictable responses a significant challenge. This paper presents a comparative analysis of three chitchat enhancements, aiming to identify the most effective approach in terms of diversity. Additionally, we quantify the divergence between the added chitchat, the original task-oriented language, and chitchat typically found in chitchat datasets, highlighting the top 20 divergent keywords for each comparison. Our findings drive a discussion on future enhancements for augmenting TODs, emphasizing the importance of grounding dialogues beyond the task to achieve more diverse and natural exchanges.
Searching for Snippets of Open-Domain Dialogue in Task-Oriented Dialogue Datasets
Nov 23, 2023
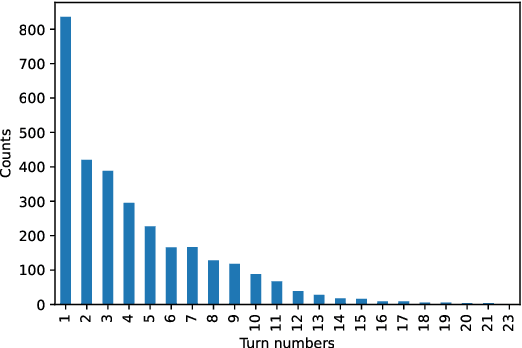
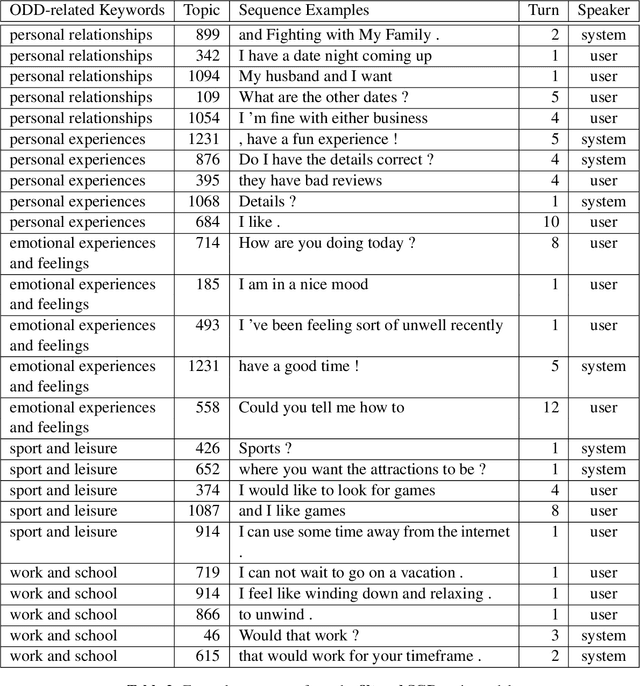
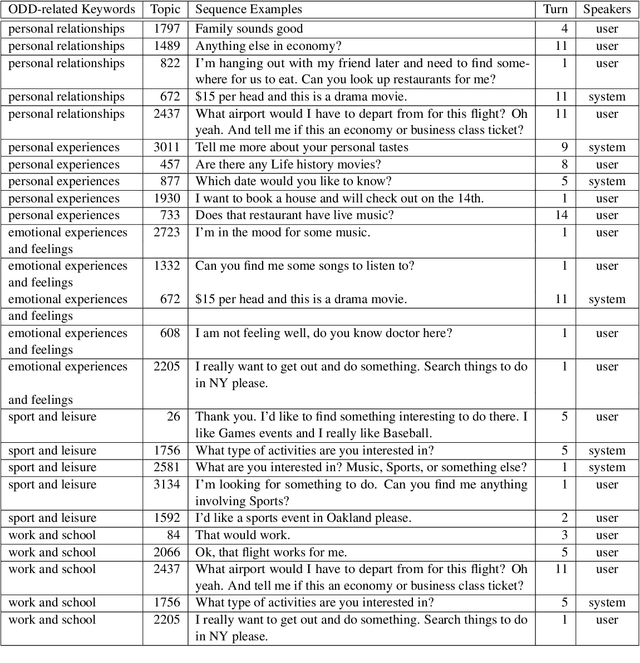
Most existing dialogue corpora and models have been designed to fit into 2 predominant categories : task-oriented dialogues portray functional goals, such as making a restaurant reservation or booking a plane ticket, while chit-chat/open-domain dialogues focus on holding a socially engaging talk with a user. However, humans tend to seamlessly switch between modes and even use chitchat to enhance task-oriented conversations. To bridge this gap, new datasets have recently been created, blending both communication modes into conversation examples. The approaches used tend to rely on adding chit-chat snippets to pre-existing, human-generated task-oriented datasets. Given the tendencies observed in humans, we wonder however if the latter do not \textit{already} hold chit-chat sequences. By using topic modeling and searching for topics which are most similar to a set of keywords related to social talk, we explore the training sets of Schema-Guided Dialogues and MultiWOZ. Our study shows that sequences related to social talk are indeed naturally present, motivating further research on ways chitchat is combined into task-oriented dialogues.
Emotion Recognition based on Psychological Components in Guided Narratives for Emotion Regulation
May 15, 2023


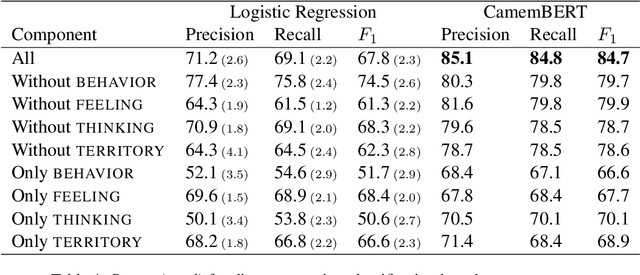
Emotion regulation is a crucial element in dealing with emotional events and has positive effects on mental health. This paper aims to provide a more comprehensive understanding of emotional events by introducing a new French corpus of emotional narratives collected using a questionnaire for emotion regulation. We follow the theoretical framework of the Component Process Model which considers emotions as dynamic processes composed of four interrelated components (behavior, feeling, thinking and territory). Each narrative is related to a discrete emotion and is structured based on all emotion components by the writers. We study the interaction of components and their impact on emotion classification with machine learning methods and pre-trained language models. Our results show that each component improves prediction performance, and that the best results are achieved by jointly considering all components. Our results also show the effectiveness of pre-trained language models in predicting discrete emotion from certain components, which reveal differences in how emotion components are expressed.
Natural Language Processing for Cognitive Analysis of Emotions
Oct 11, 2022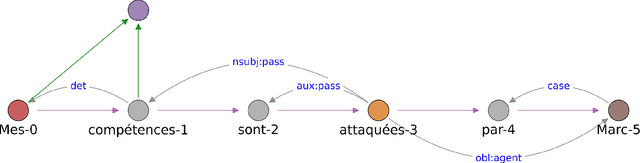
Emotion analysis in texts suffers from two major limitations: annotated gold-standard corpora are mostly small and homogeneous, and emotion identification is often simplified as a sentence-level classification problem. To address these issues, we introduce a new annotation scheme for exploring emotions and their causes, along with a new French dataset composed of autobiographical accounts of an emotional scene. The texts were collected by applying the Cognitive Analysis of Emotions developed by A. Finkel to help people improve on their emotion management. The method requires the manual analysis of an emotional event by a coach trained in Cognitive Analysis. We present a rule-based approach to automatically annotate emotions and their semantic roles (e.g. emotion causes) to facilitate the identification of relevant aspects by the coach. We investigate future directions for emotion analysis using graph structures.