 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFKI-NLP at SemEval-2024 Task 2: Towards Robust LLMs Using Data Perturbations and MinMax Training
Paper and Code

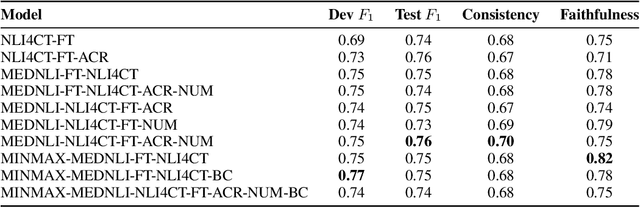

The NLI4CT task at SemEval-2024 emphasizes the development of robust models for Natural Language Inference on Clinical Trial Reports (CTRs) using large language models (LLMs). This edition introduces interventions specifically targeting the numerical, vocabulary, and semantic aspects of CTRs. Our proposed system harnesses the capabilities of the state-of-the-art Mistral model, complemented by an auxiliary model, to focus on the intricate input space of the NLI4CT dataset. Through the incorporation of numerical and acronym-based perturbations to the data, we train a robust system capable of handling both semantic-altering and numerical contradiction interventions. Our analysis on the dataset sheds light on the challenging sections of the CTRs for reasoning.