Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Vector Conceptualization for Word Vector Space Interpretation
Paper and Code
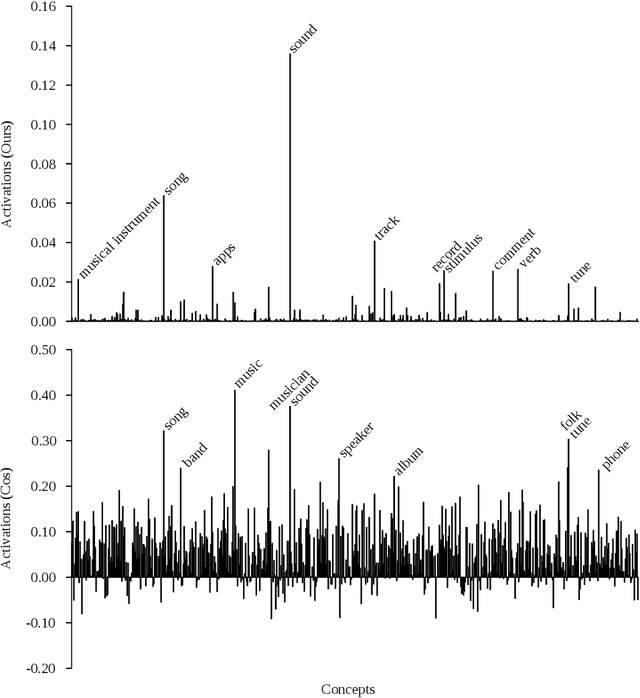
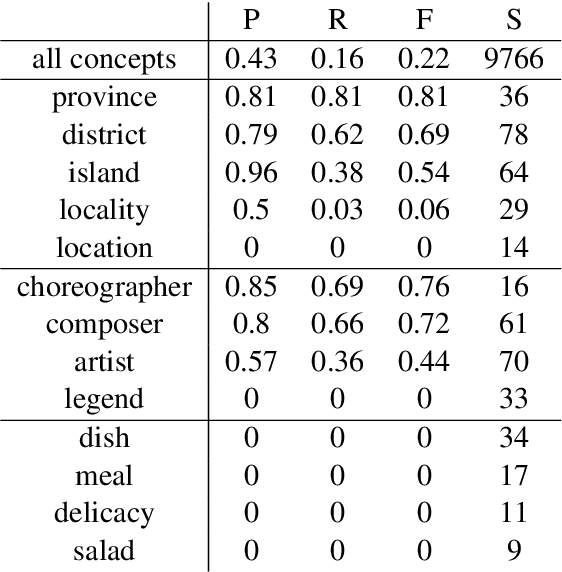
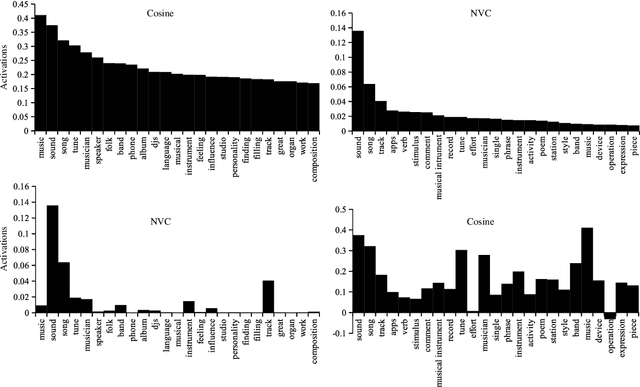
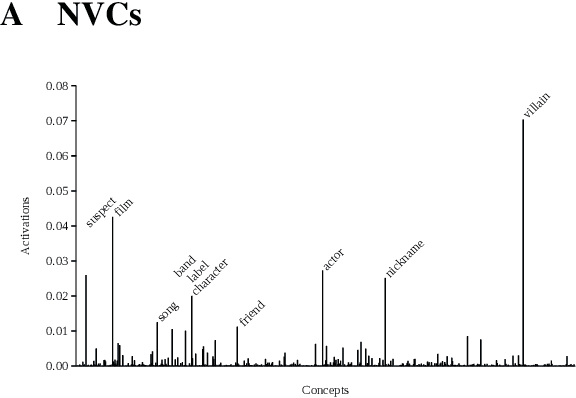
Distributed word vector spaces are considered hard to interpret which hinders the understanding of natural language processing (NLP) models. In this work, we introduce a new method to interpret arbitrary samples from a word vector space. To this end, we train a neural model to conceptualize word vectors, which means that it activates higher order concepts it recognizes in a given vector. Contrary to prior approaches, our model operates in the original vector space and is capable of learning non-linear relations between word vectors and concepts. Furthermore, we show that it produces considerably less entropic concept activation profiles than the popular cosine similarity.
* NAACL-HLT 2019 Workshop on Evaluating Vector Space Representations
for NLP (RepEval)
View paper on