 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstructing Natural Language Explanations via Saliency Map Verbalization
Oct 13, 2022

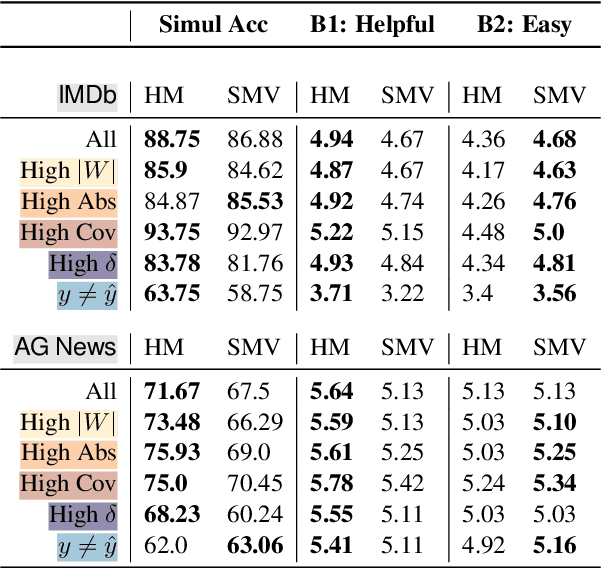
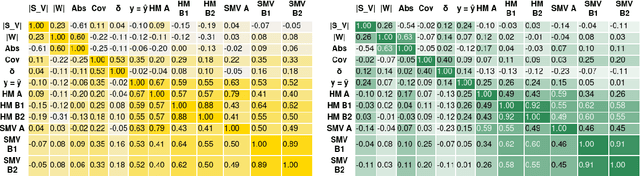
Saliency maps can explain a neural model's prediction by identifying important input features. While they excel in being faithful to the explained model, saliency maps in their entirety are difficult to interpret for humans, especially for instances with many input features. In contrast, natural language explanations (NLEs) are flexible and can be tuned to a recipient's expectations, but are costly to generate: Rationalization models are usually trained on specific tasks and require high-quality and diverse datasets of human annotations. We combine the advantages from both explainability methods by verbalizing saliency maps. We formalize this underexplored task and propose a novel methodology that addresses two key challenges of this approach -- what and how to verbalize. Our approach utilizes efficient search methods that are task- and model-agnostic and do not require another black-box model, and hand-crafted templates to preserve faithfulness. We conduct a human evaluation of explanation representations across two natural language processing (NLP) tasks: news topic classification and sentiment analysis. Our results suggest that saliency map verbalization makes explanations more understandable and less cognitively challenging to humans than conventional heatmap visualization.
Thermostat: A Large Collection of NLP Model Explanations and Analysis Tools
Aug 31, 2021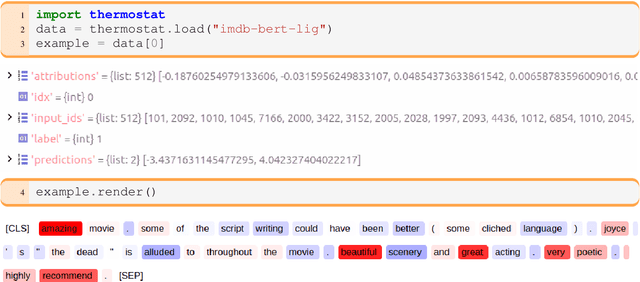
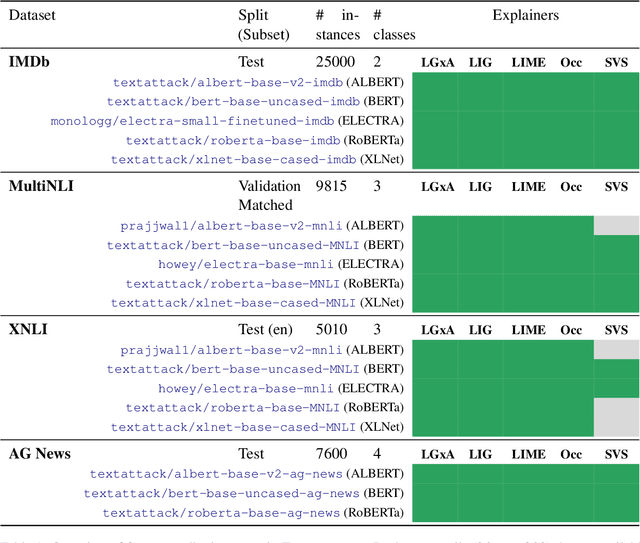
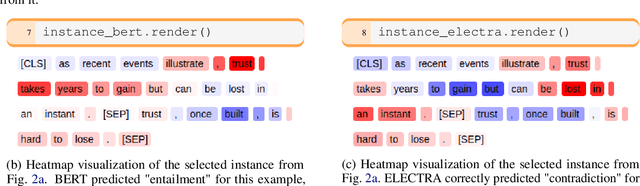

In the language domain, as in other domains, neural explainability takes an ever more important role, with feature attribution methods on the forefront. Many such methods require considerable computational resources and expert knowledge about implementation details and parameter choices. To facilitate research, we present Thermostat which consists of a large collection of model explanations and accompanying analysis tools. Thermostat allows easy access to over 200k explanations for the decisions of prominent state-of-the-art models spanning across different NLP tasks, generated with multiple explainers. The dataset took over 10k GPU hours (> one year) to compile; compute time that the community now saves. The accompanying software tools allow to analyse explanations instance-wise but also accumulatively on corpus level. Users can investigate and compare models, datasets and explainers without the need to orchestrate implementation details. Thermostat is fully open source, democratizes explainability research in the language domain, circumvents redundant computations and increases comparability and replicability.
Defx at SemEval-2020 Task 6: Joint Extraction of Concepts and Relations for Definition Extraction
Mar 31, 2021

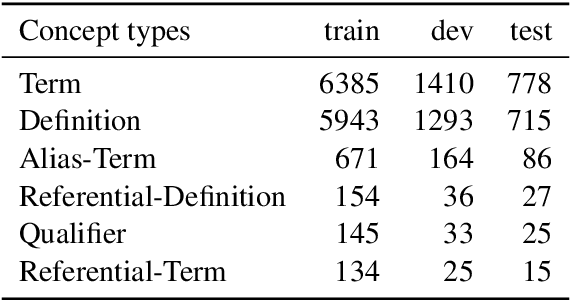

Definition Extraction systems are a valuable knowledge source for both humans and algorithms. In this paper we describe our submissions to the DeftEval shared task (SemEval-2020 Task 6), which is evaluated on an English textbook corpus. We provide a detailed explanation of our system for the joint extraction of definition concepts and the relations among them. Furthermore we provide an ablation study of our model variations and describe the results of an error analysis.
Efficient Explanations from Empirical Explainers
Mar 29, 2021
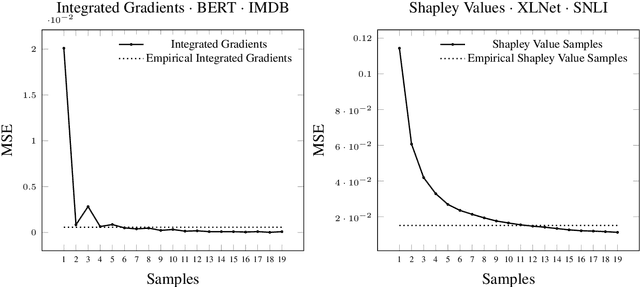
Amid a discussion about Green AI in which we see explainability neglected, we explore the possibility to efficiently approximate computationally expensive explainers. To this end, we propose the task of feature attribution modelling that we address with Empirical Explainers. Empirical Explainers learn from data to predict the attribution maps of expensive explainers. We train and test Empirical Explainers in the language domain and find that they model their expensive counterparts well, at a fraction of the cost. They could thus mitigate the computational burden of neural explanations significantly, in applications that tolerate an approximation error.
Pattern-Guided Integrated Gradients
Sep 01, 2020
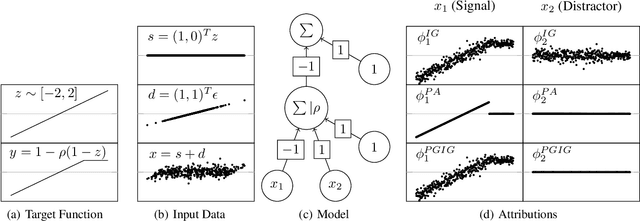

Integrated Gradients (IG) and PatternAttribution (PA) are two established explainability methods for neural networks. Both methods are theoretically well-founded. However, they were designed to overcome different challenges. In this work, we combine the two methods into a new method, Pattern-Guided Integrated Gradients (PGIG). PGIG inherits important properties from both parent methods and passes stress tests that the originals fail. In addition, we benchmark PGIG against nine alternative explainability approaches (including its parent methods) in a large-scale image degradation experiment and find that it outperforms all of them.
Evaluating German Transformer Language Models with Syntactic Agreement Tests
Jul 07, 2020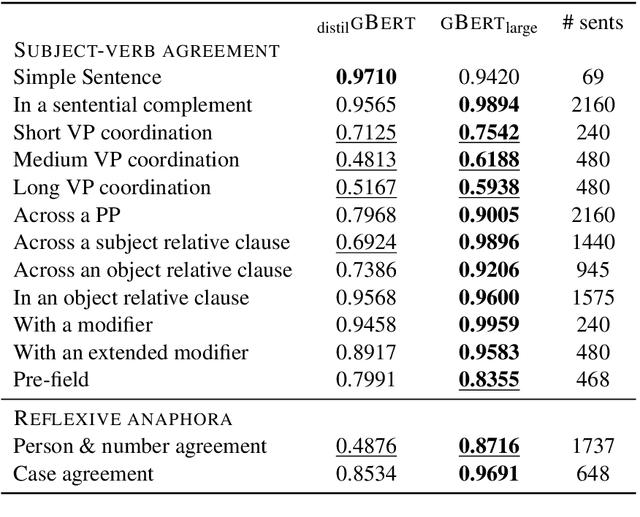
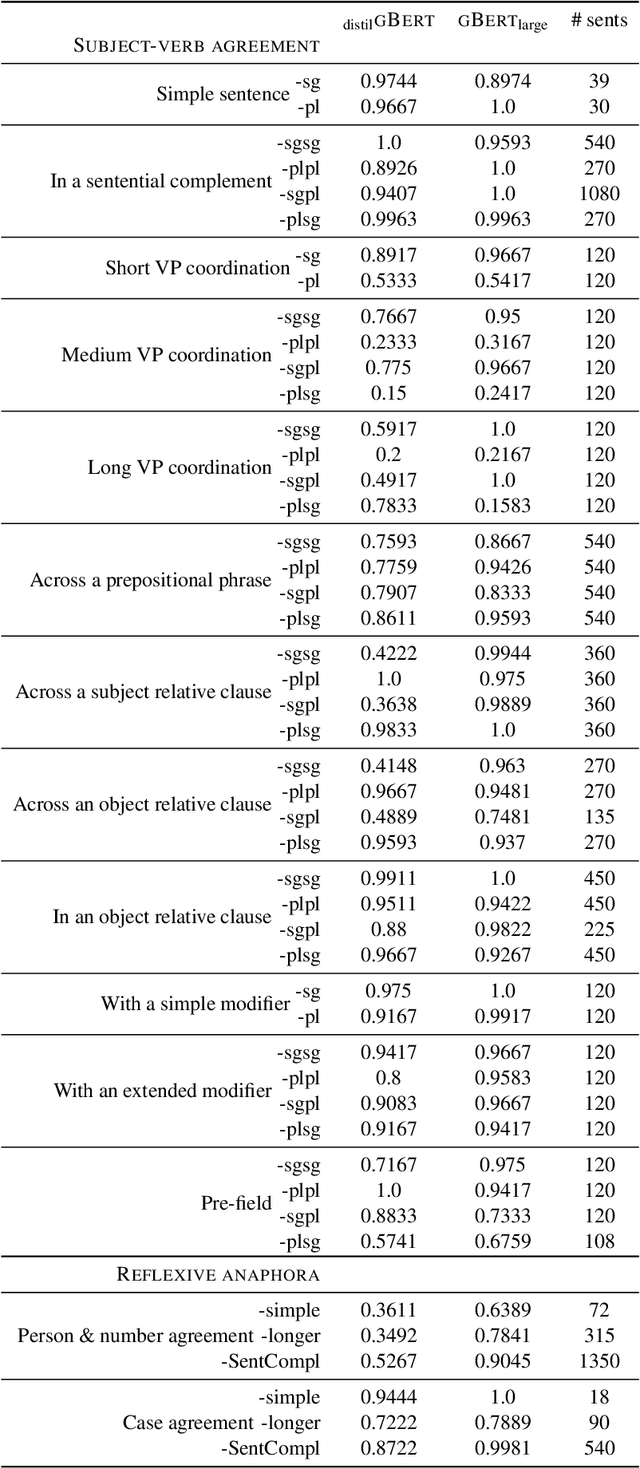
Pre-trained transformer language models (TLMs) have recently refashioned natural language processing (NLP): Most state-of-the-art NLP models now operate on top of TLMs to benefit from contextualization and knowledge induction. To explain their success, the scientific community conducted numerous analyses. Besides other methods, syntactic agreement tests were utilized to analyse TLMs. Most of the studies were conducted for the English language, however. In this work, we analyse German TLMs. To this end, we design numerous agreement tasks, some of which consider peculiarities of the German language. Our experimental results show that state-of-the-art German TLMs generally perform well on agreement tasks, but we also identify and discuss syntactic structures that push them to their limits.
* SwissText + KONVENS 2020
Abstractive Text Summarization based on Language Model Conditioning and Locality Modeling
Mar 29, 2020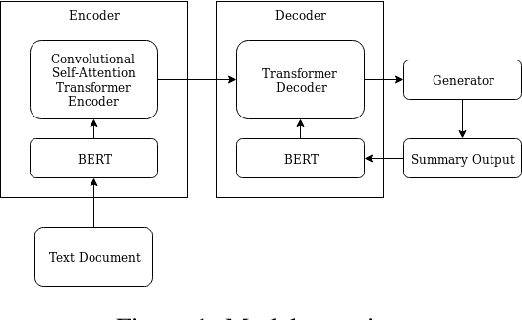
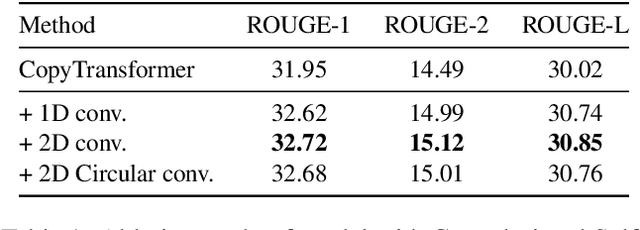


We explore to what extent knowledge about the pre-trained language model that is used is beneficial for the task of abstractive summarization. To this end, we experiment with conditioning the encoder and decoder of a Transformer-based neural model on the BERT language model. In addition, we propose a new method of BERT-windowing, which allows chunk-wise processing of texts longer than the BERT window size. We also explore how locality modelling, i.e., the explicit restriction of calculations to the local context, can affect the summarization ability of the Transformer. This is done by introducing 2-dimensional convolutional self-attention into the first layers of the encoder. The results of our models are compared to a baseline and the state-of-the-art models on the CNN/Daily Mail dataset. We additionally train our model on the SwissText dataset to demonstrate usability on German. Both models outperform the baseline in ROUGE scores on two datasets and show its superiority in a manual qualitative analysis.
Layerwise Relevance Visualization in Convolutional Text Graph Classifiers
Sep 24, 2019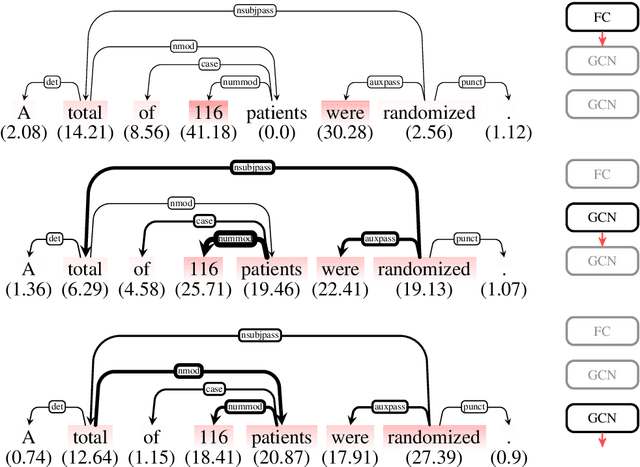
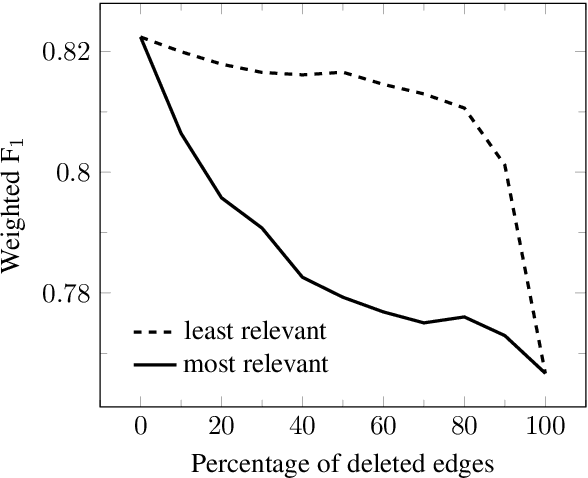
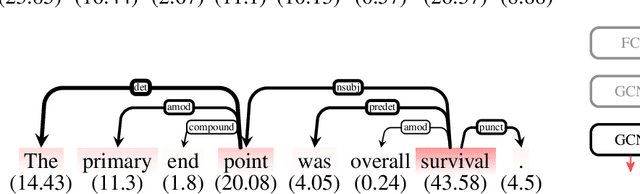
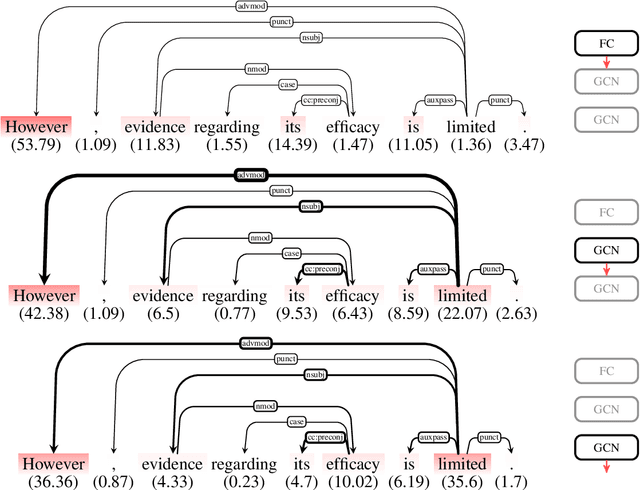
Representations in the hidden layers of Deep Neural Networks (DNN) are often hard to interpret since it is difficult to project them into an interpretable domain. Graph Convolutional Networks (GCN) allow this projection, but existing explainability methods do not exploit this fact, i.e. do not focus their explanations on intermediate states. In this work, we present a novel method that traces and visualizes features that contribute to a classification decision in the visible and hidden layers of a GCN. Our method exposes hidden cross-layer dynamics in the input graph structure. We experimentally demonstrate that it yields meaningful layerwise explanations for a GCN sentence classifier.
Neural Vector Conceptualization for Word Vector Space Interpretation
Apr 02, 2019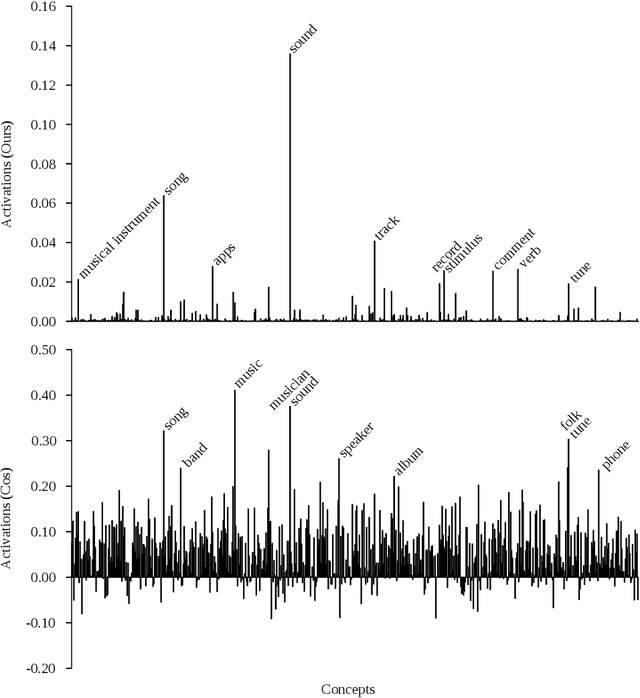
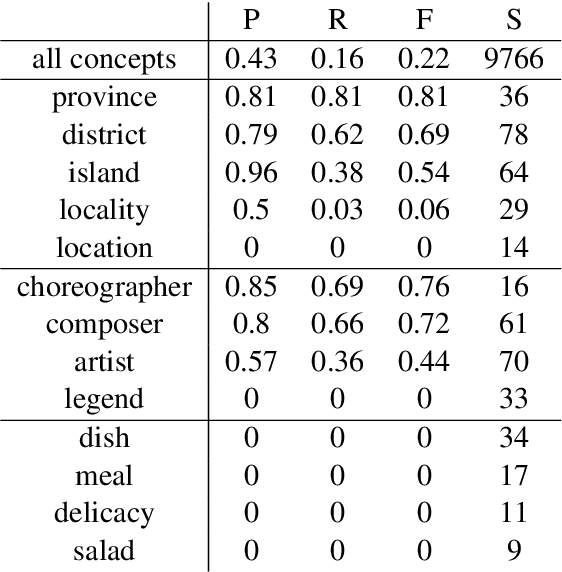
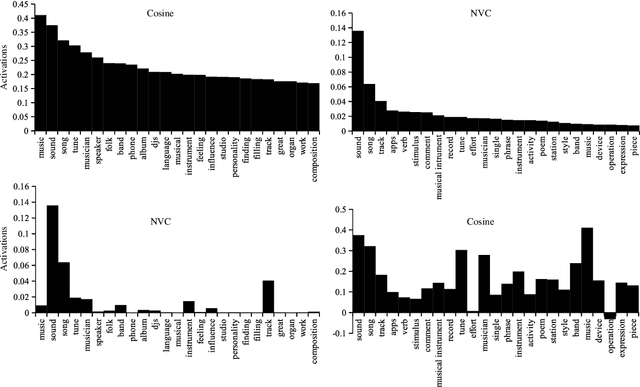
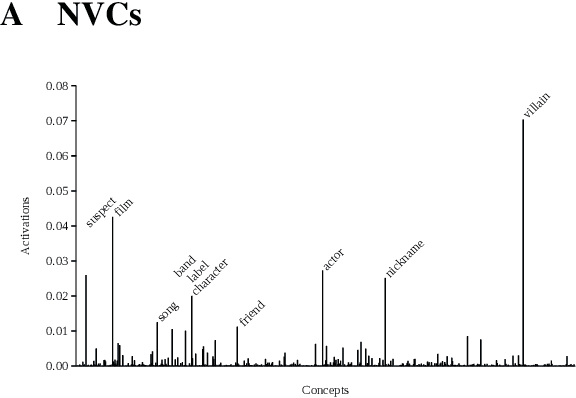
Distributed word vector spaces are considered hard to interpret which hinders the understanding of natural language processing (NLP) models. In this work, we introduce a new method to interpret arbitrary samples from a word vector space. To this end, we train a neural model to conceptualize word vectors, which means that it activates higher order concepts it recognizes in a given vector. Contrary to prior approaches, our model operates in the original vector space and is capable of learning non-linear relations between word vectors and concepts. Furthermore, we show that it produces considerably less entropic concept activation profiles than the popular cosine similarity.
Train, Sort, Explain: Learning to Diagnose Translation Models
Mar 28, 2019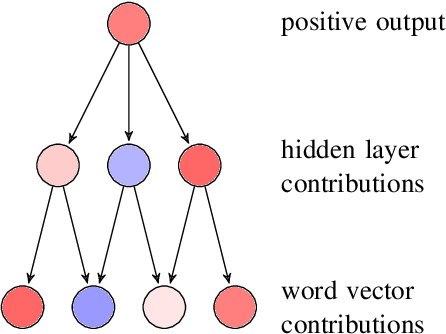

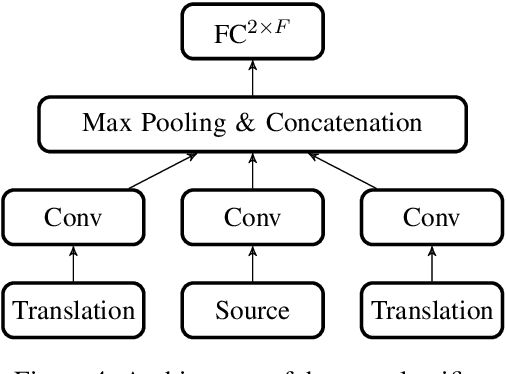
Evaluating translation models is a trade-off between effort and detail. On the one end of the spectrum there are automatic count-based methods such as BLEU, on the other end linguistic evaluations by humans, which arguably are more informative but also require a disproportionately high effort. To narrow the spectrum, we propose a general approach on how to automatically expose systematic differences between human and machine translations to human experts. Inspired by adversarial settings, we train a neural text classifier to distinguish human from machine translations. A classifier that performs and generalizes well after training should recognize systematic differences between the two classes, which we uncover with neural explainability methods. Our proof-of-concept implementation, DiaMaT, is open source. Applied to a dataset translated by a state-of-the-art neural Transformer model, DiaMaT achieves a classification accuracy of 75% and exposes meaningful differences between humans and the Transformer, amidst the current discussion about human parity.