 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefx at SemEval-2020 Task 6: Joint Extraction of Concepts and Relations for Definition Extraction
Mar 31, 2021

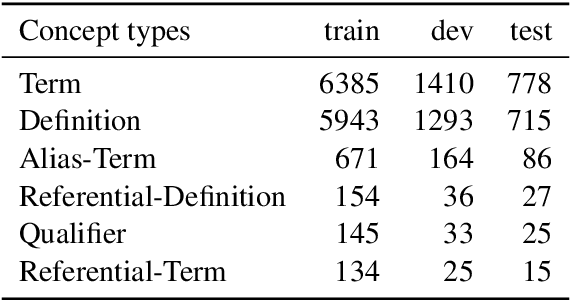

Definition Extraction systems are a valuable knowledge source for both humans and algorithms. In this paper we describe our submissions to the DeftEval shared task (SemEval-2020 Task 6), which is evaluated on an English textbook corpus. We provide a detailed explanation of our system for the joint extraction of definition concepts and the relations among them. Furthermore we provide an ablation study of our model variations and describe the results of an error analysis.
Layerwise Relevance Visualization in Convolutional Text Graph Classifiers
Sep 24, 2019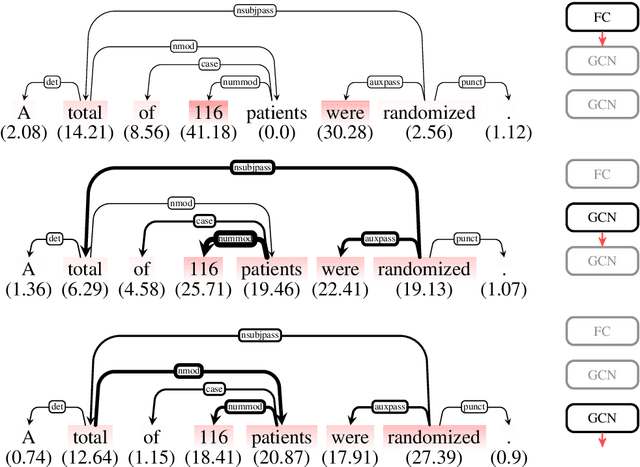
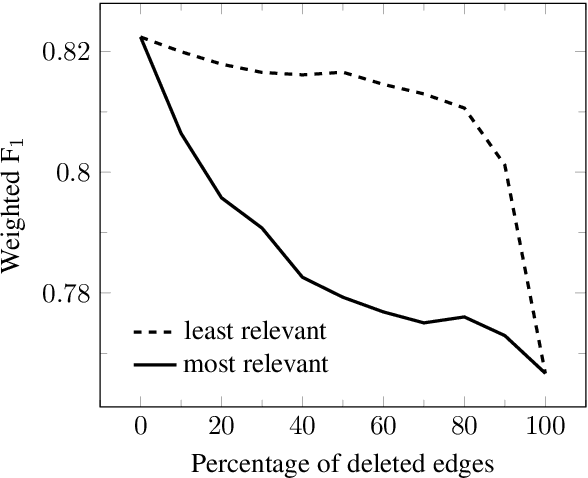
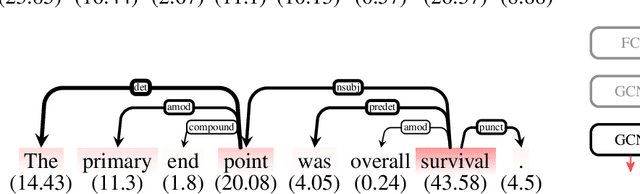
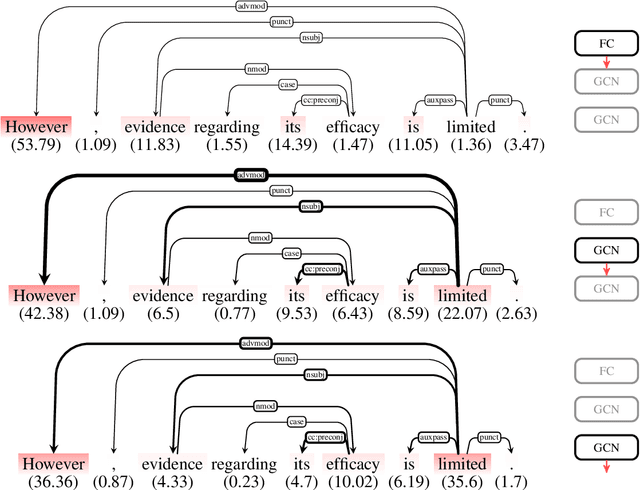
Representations in the hidden layers of Deep Neural Networks (DNN) are often hard to interpret since it is difficult to project them into an interpretable domain. Graph Convolutional Networks (GCN) allow this projection, but existing explainability methods do not exploit this fact, i.e. do not focus their explanations on intermediate states. In this work, we present a novel method that traces and visualizes features that contribute to a classification decision in the visible and hidden layers of a GCN. Our method exposes hidden cross-layer dynamics in the input graph structure. We experimentally demonstrate that it yields meaningful layerwise explanations for a GCN sentence classifier.
Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction
Jun 19, 2019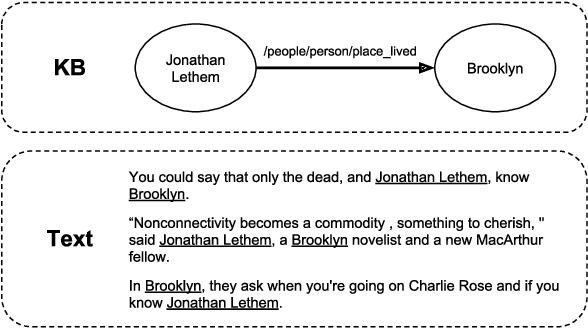
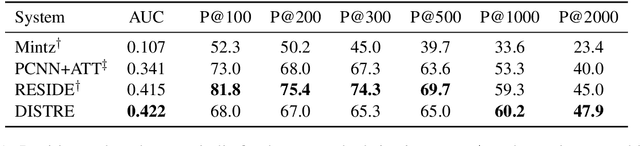


Distantly supervised relation extraction is widely used to extract relational facts from text, but suffers from noisy labels. Current relation extraction methods try to alleviate the noise by multi-instance learning and by providing supporting linguistic and contextual information to more efficiently guide the relation classification. While achieving state-of-the-art results, we observed these models to be biased towards recognizing a limited set of relations with high precision, while ignoring those in the long tail. To address this gap, we utilize a pre-trained language model, the OpenAI Generative Pre-trained Transformer (GPT) [Radford et al., 2018]. The GPT and similar models have been shown to capture semantic and syntactic features, and also a notable amount of "common-sense" knowledge, which we hypothesize are important features for recognizing a more diverse set of relations. By extending the GPT to the distantly supervised setting, and fine-tuning it on the NYT10 dataset, we show that it predicts a larger set of distinct relation types with high confidence. Manual and automated evaluation of our model shows that it achieves a state-of-the-art AUC score of 0.422 on the NYT10 dataset, and performs especially well at higher recall levels.
Improving Relation Extraction by Pre-trained Language Representations
Jun 07, 2019



Current state-of-the-art relation extraction methods typically rely on a set of lexical, syntactic, and semantic features, explicitly computed in a pre-processing step. Training feature extraction models requires additional annotated language resources, which severely restricts the applicability and portability of relation extraction to novel languages. Similarly, pre-processing introduces an additional source of error. To address these limitations, we introduce TRE, a Transformer for Relation Extraction, extending the OpenAI Generative Pre-trained Transformer [Radford et al., 2018]. Unlike previous relation extraction models, TRE uses pre-trained deep language representations instead of explicit linguistic features to inform the relation classification and combines it with the self-attentive Transformer architecture to effectively model long-range dependencies between entity mentions. TRE allows us to learn implicit linguistic features solely from plain text corpora by unsupervised pre-training, before fine-tuning the learned language representations on the relation extraction task. TRE obtains a new state-of-the-art result on the TACRED and SemEval 2010 Task 8 datasets, achieving a test F1 of 67.4 and 87.1, respectively. Furthermore, we observe a significant increase in sample efficiency. With only 20% of the training examples, TRE matches the performance of our baselines and our model trained from scratch on 100% of the TACRED dataset. We open-source our trained models, experiments, and source code.
* Code and models available at: https://github.com/DFKI-NLP/TRE