 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogPII: A multilingual dataset of synthetic dialog transcripts to detect personal information
Jun 29, 2026Conversational data collected in domains such as healthcare or social sciences is a valuable resource for research and automated analysis. However, responsible data sharing requires the detection and removal of personally identifiable and sensitive information to protect individual privacy. To support the development and evaluation of automatic de-identification systems, we present DialogPII, a multilingual dataset of synthetic dialogs and speech-derived transcripts for personal information detection. DialogPII covers eight interaction scenarios (emergency calls, medical anamnesis interviews, therapy sessions, insurance communication, customer support, clinical interviews regarding an AI-supported dashboard, police reports, and group therapy discussions), 19 entity types, and 11 languages (English, Arabic, Finnish, French, German, Hindi, Italian, Polish, Portuguese, Spanish, and Turkish). Dialogs were generated semi-automatically using large language models, manually curated for plausibility and diversity, and localized to country- and city-specific contexts. All dialogs were additionally converted to speech via text-to-speech synthesis, transcribed with Whisper, and annotated through automatic projection and manual correction, yielding aligned written and speech-derived resources across all languages. We further release baseline multilingual named entity recognition models and provide technical validation through inter-annotator agreement analysis, translation quality evaluation, annotation projection assessment, and benchmark experiments with transformer-based sequence labeling models.
MultiGraSCCo: A Multilingual Anonymization Benchmark with Annotations of Personal Identifiers
Mar 11, 2026Accessing sensitive patient data for machine learning is challenging due to privacy concerns. Datasets with annotations of personally identifiable information are crucial for developing and testing anonymization systems to enable safe data sharing that complies with privacy regulations. Since accessing real patient data is a bottleneck, synthetic data offers an efficient solution for data scarcity, bypassing privacy regulations that apply to real data. Moreover, neural machine translation can help to create high-quality data for low-resource languages by translating validated real or synthetic data from a high-resource language. In this work, we create a multilingual anonymization benchmark in ten languages, using a machine translation methodology that preserves the original annotations and renders names of cities and people in a culturally and contextually appropriate form in each target language. Our evaluation study with medical professionals confirms the quality of the translations, both in general and with respect to the translation and adaptation of personal information. Our benchmark with over 2,500 annotations of personal information can be used in many applications, including training annotators, validating annotations across institutions without legal complications, and helping improve the performance of automatic personal information detection. We make our benchmark and annotation guidelines available for further research.
Temporal Fusion Nexus: A task-agnostic multi-modal embedding model for clinical narratives and irregular time series in post-kidney transplant care
Jan 13, 2026We introduce Temporal Fusion Nexus (TFN), a multi-modal and task-agnostic embedding model to integrate irregular time series and unstructured clinical narratives. We analysed TFN in post-kidney transplant (KTx) care, with a retrospective cohort of 3382 patients, on three key outcomes: graft loss, graft rejection, and mortality. Compared to state-of-the-art model in post KTx care, TFN achieved higher performance for graft loss (AUC 0.96 vs. 0.94) and graft rejection (AUC 0.84 vs. 0.74). In mortality prediction, TFN yielded an AUC of 0.86. TFN outperformed unimodal baselines (approx 10% AUC improvement over time series only baseline, approx 5% AUC improvement over time series with static patient data). Integrating clinical text improved performance across all tasks. Disentanglement metrics confirmed robust and interpretable latent factors in the embedding space, and SHAP-based attributions confirmed alignment with clinical reasoning. TFN has potential application in clinical tasks beyond KTx, where heterogeneous data sources, irregular longitudinal data, and rich narrative documentation are available.
Detecting Pipeline Failures through Fine-Grained Analysis of Web Agents
Sep 17, 2025Web agents powered by large language models (LLMs) can autonomously perform complex, multistep tasks in dynamic web environments. However, current evaluations mostly focus on the overall success while overlooking intermediate errors. This limits insight into failure modes and hinders systematic improvement. This work analyzes existing benchmarks and highlights the lack of fine-grained diagnostic tools. To address this gap, we propose a modular evaluation framework that decomposes agent pipelines into interpretable stages for detailed error analysis. Using the SeeAct framework and the Mind2Web dataset as a case study, we show how this approach reveals actionable weaknesses missed by standard metrics - paving the way for more robust and generalizable web agents.
Infherno: End-to-end Agent-based FHIR Resource Synthesis from Free-form Clinical Notes
Jul 16, 2025



For clinical data integration and healthcare services, the HL7 FHIR standard has established itself as a desirable format for interoperability between complex health data. Previous attempts at automating the translation from free-form clinical notes into structured FHIR resources rely on modular, rule-based systems or LLMs with instruction tuning and constrained decoding. Since they frequently suffer from limited generalizability and structural inconformity, we propose an end-to-end framework powered by LLM agents, code execution, and healthcare terminology database tools to address these issues. Our solution, called Infherno, is designed to adhere to the FHIR document schema and competes well with a human baseline in predicting FHIR resources from unstructured text. The implementation features a front end for custom and synthetic data and both local and proprietary models, supporting clinical data integration processes and interoperability across institutions.
One Size Fits None: Rethinking Fairness in Medical AI
Jun 17, 2025Machine learning (ML) models are increasingly used to support clinical decision-making. However, real-world medical datasets are often noisy, incomplete, and imbalanced, leading to performance disparities across patient subgroups. These differences raise fairness concerns, particularly when they reinforce existing disadvantages for marginalized groups. In this work, we analyze several medical prediction tasks and demonstrate how model performance varies with patient characteristics. While ML models may demonstrate good overall performance, we argue that subgroup-level evaluation is essential before integrating them into clinical workflows. By conducting a performance analysis at the subgroup level, differences can be clearly identified-allowing, on the one hand, for performance disparities to be considered in clinical practice, and on the other hand, for these insights to inform the responsible development of more effective models. Thereby, our work contributes to a practical discussion around the subgroup-sensitive development and deployment of medical ML models and the interconnectedness of fairness and transparency.
Beyond De-Identification: A Structured Approach for Defining and Detecting Indirect Identifiers in Medical Texts
Feb 18, 2025
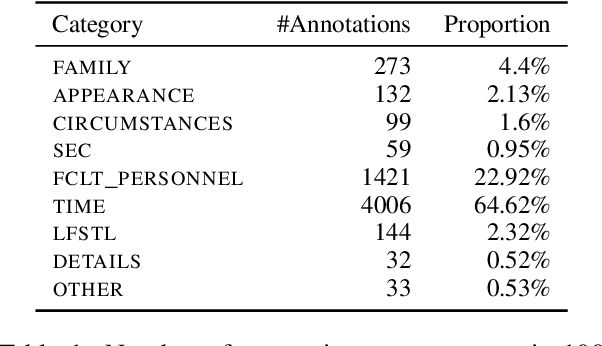
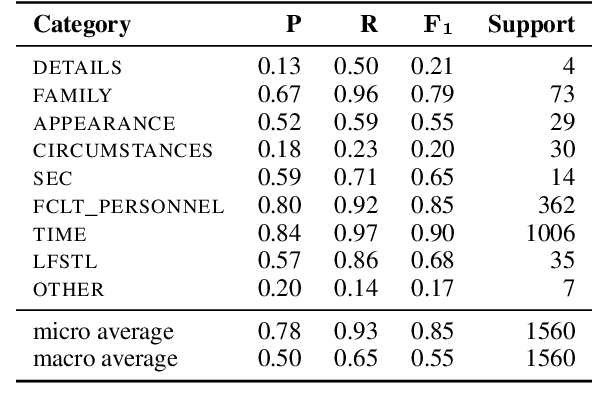

Sharing sensitive texts for scientific purposes requires appropriate techniques to protect the privacy of patients and healthcare personnel. Anonymizing textual data is particularly challenging due to the presence of diverse unstructured direct and indirect identifiers. To mitigate the risk of re-identification, this work introduces a schema of nine categories of indirect identifiers designed to account for different potential adversaries, including acquaintances, family members and medical staff. Using this schema, we annotate 100 MIMIC-III discharge summaries and propose baseline models for identifying indirect identifiers. We will release the annotation guidelines, annotation spans (6,199 annotations in total) and the corresponding MIMIC-III document IDs to support further research in this area.
A Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024



User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
xMEN: A Modular Toolkit for Cross-Lingual Medical Entity Normalization
Oct 17, 2023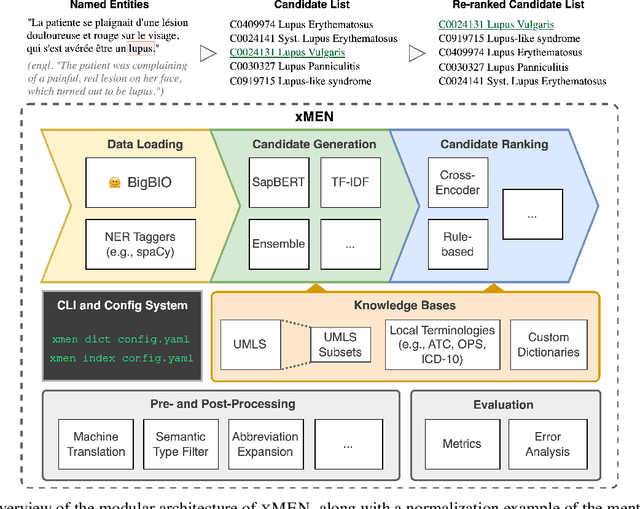
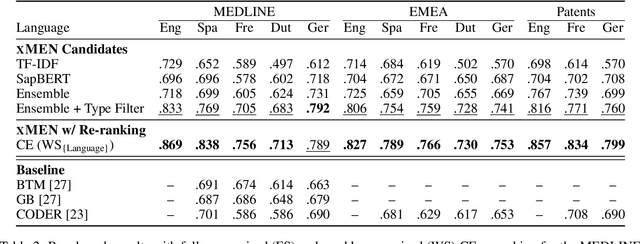
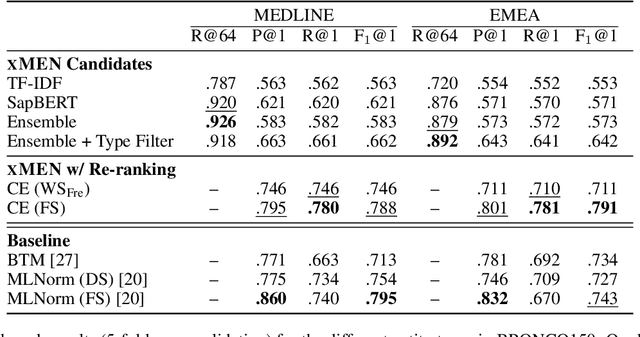
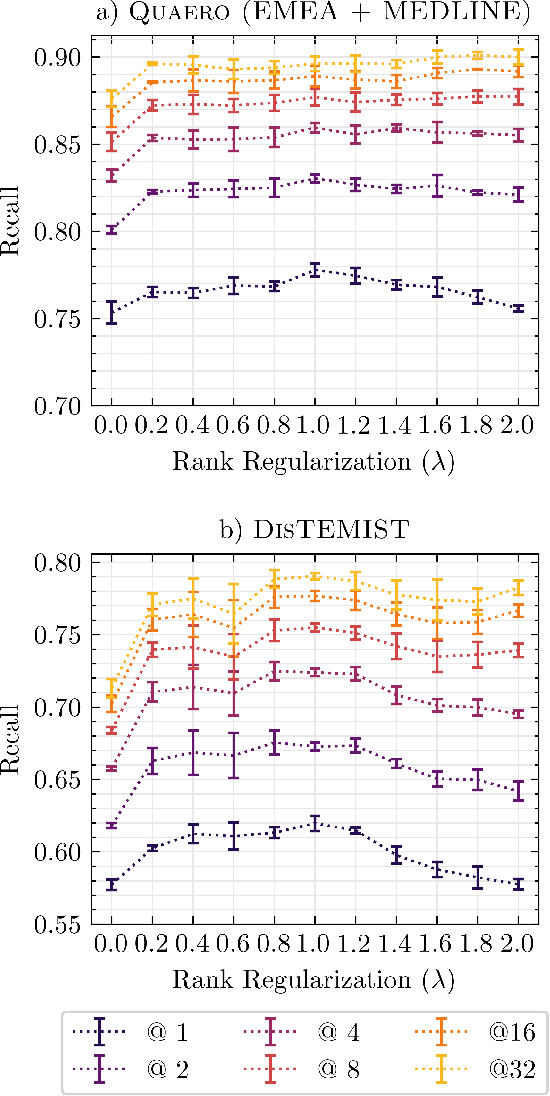
Objective: To improve performance of medical entity normalization across many languages, especially when fewer language resources are available compared to English. Materials and Methods: We introduce xMEN, a modular system for cross-lingual medical entity normalization, which performs well in both low- and high-resource scenarios. When synonyms in the target language are scarce for a given terminology, we leverage English aliases via cross-lingual candidate generation. For candidate ranking, we incorporate a trainable cross-encoder model if annotations for the target task are available. We also evaluate cross-encoders trained in a weakly supervised manner based on machine-translated datasets from a high resource domain. Our system is publicly available as an extensible Python toolkit. Results: xMEN improves the state-of-the-art performance across a wide range of multilingual benchmark datasets. Weakly supervised cross-encoders are effective when no training data is available for the target task. Through the compatibility of xMEN with the BigBIO framework, it can be easily used with existing and prospective datasets. Discussion: Our experiments show the importance of balancing the output of general-purpose candidate generators with subsequent trainable re-rankers, which we achieve through a rank regularization term in the loss function of the cross-encoder. However, error analysis reveals that multi-word expressions and other complex entities are still challenging. Conclusion: xMEN exhibits strong performance for medical entity normalization in multiple languages, even when no labeled data and few terminology aliases for the target language are available. Its configuration system and evaluation modules enable reproducible benchmarks. Models and code are available online at the following URL: https://github.com/hpi-dhc/xmen
Factuality Detection using Machine Translation -- a Use Case for German Clinical Text
Aug 17, 2023
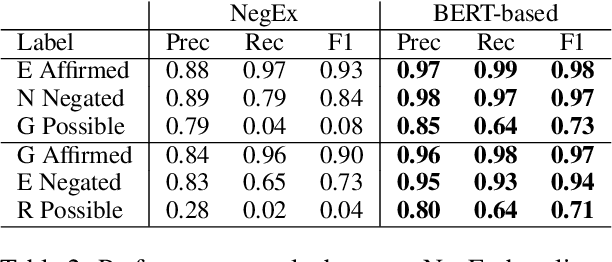
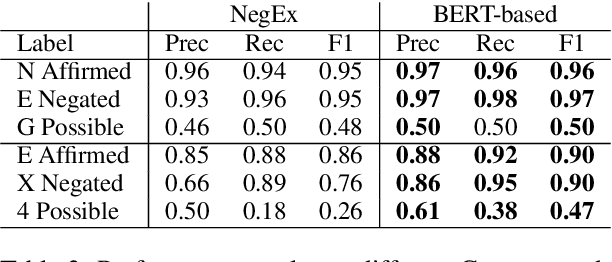
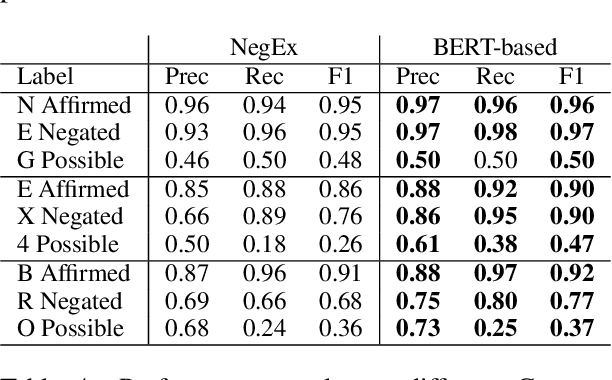
Factuality can play an important role when automatically processing clinical text, as it makes a difference if particular symptoms are explicitly not present, possibly present, not mentioned, or affirmed. In most cases, a sufficient number of examples is necessary to handle such phenomena in a supervised machine learning setting. However, as clinical text might contain sensitive information, data cannot be easily shared. In the context of factuality detection, this work presents a simple solution using machine translation to translate English data to German to train a transformer-based factuality detection model.