 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Word and the Way: Strategies for Domain-Specific BERT Pre-Training in German Medical NLP
Jun 02, 2026Digital healthcare generates vast amounts of clinical text that can support AI-assisted applications, yet German biomedical language models remain limited by older architectures or restricted training data. We present ChristBERT (Clinical- and Healthcare-Related Issues and Subjects Tuned BERT), a family of domain-specific German RoBERTa-based language models trained on a 13.5GB corpus of scientific publications, clinical texts, health-related web content, and translated clinical resources. To investigate the impact of domain adaptation strategies in German clinical NLP, we compare continued pre-training, training from scratch, and domain-specific vocabulary adaptation. The resulting models are evaluated on three medical named entity recognition tasks and two text classification tasks. ChristBERT consistently outperforms existing general-purpose and medical German language models on four of five benchmarks and establishes a new state of the art for German clinical language modeling. Our results show that the optimal adaptation strategy is task-dependent: in our evaluation, training from scratch is particularly effective for highly specialized clinical texts, whereas continued pre-training performs well on more commonly written medical texts. All models are publicly released to support future research and applications in German medical NLP.
Infherno: End-to-end Agent-based FHIR Resource Synthesis from Free-form Clinical Notes
Jul 16, 2025



For clinical data integration and healthcare services, the HL7 FHIR standard has established itself as a desirable format for interoperability between complex health data. Previous attempts at automating the translation from free-form clinical notes into structured FHIR resources rely on modular, rule-based systems or LLMs with instruction tuning and constrained decoding. Since they frequently suffer from limited generalizability and structural inconformity, we propose an end-to-end framework powered by LLM agents, code execution, and healthcare terminology database tools to address these issues. Our solution, called Infherno, is designed to adhere to the FHIR document schema and competes well with a human baseline in predicting FHIR resources from unstructured text. The implementation features a front end for custom and synthetic data and both local and proprietary models, supporting clinical data integration processes and interoperability across institutions.
GeistBERT: Breathing Life into German NLP
Jun 13, 2025Advances in transformer-based language models have highlighted the benefits of language-specific pre-training on high-quality corpora. In this context, German NLP stands to gain from updated architectures and modern datasets tailored to the linguistic characteristics of the German language. GeistBERT seeks to improve German language processing by incrementally training on a diverse corpus and optimizing model performance across various NLP tasks. It was pre-trained using fairseq with standard hyperparameters, initialized from GottBERT weights, and trained on a large-scale German corpus using Whole Word Masking (WWM). Based on the pre-trained model, we derived extended-input variants using Nystr\"omformer and Longformer architectures with support for sequences up to 8k tokens. While these long-context models were not evaluated on dedicated long-context benchmarks, they are included in our release. We assessed all models on NER (CoNLL 2003, GermEval 2014) and text classification (GermEval 2018 fine/coarse, 10kGNAD) using $F_1$ score and accuracy. The GeistBERT models achieved strong performance, leading all tasks among the base models and setting a new state-of-the-art (SOTA). Notably, the base models outperformed larger models in several tasks. To support the German NLP research community, we are releasing GeistBERT under the MIT license.
Annotated Dataset Creation through General Purpose Language Models for non-English Medical NLP
Aug 30, 2022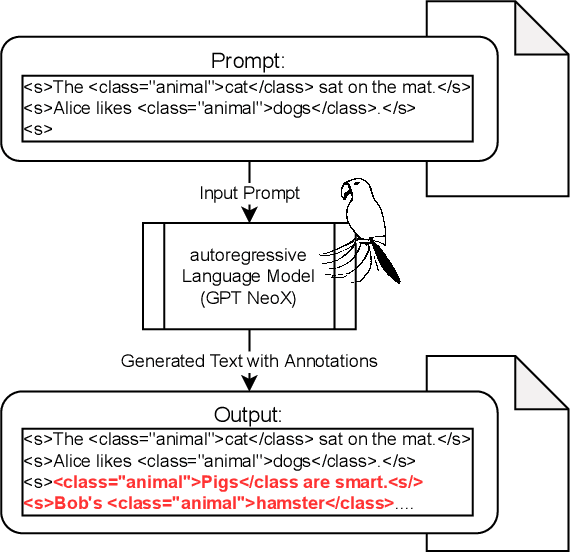
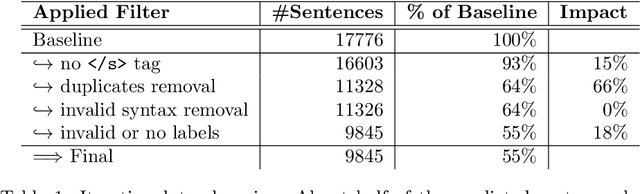

Obtaining text datasets with semantic annotations is an effortful process, yet crucial for supervised training in natural language processsing (NLP). In general, developing and applying new NLP pipelines in domain-specific contexts for tasks often requires custom designed datasets to address NLP tasks in supervised machine learning fashion. When operating in non-English languages for medical data processing, this exposes several minor and major, interconnected problems such as lack of task-matching datasets as well as task-specific pre-trained models. In our work we suggest to leverage pretrained language models for training data acquisition in order to retrieve sufficiently large datasets for training smaller and more efficient models for use-case specific tasks. To demonstrate the effectiveness of your approach, we create a custom dataset which we use to train a medical NER model for German texts, GPTNERMED, yet our method remains language-independent in principle. Our obtained dataset as well as our pre-trained models are publicly available at: https://github.com/frankkramer-lab/GPTNERMED
GERNERMED++: Transfer Learning in German Medical NLP
Jun 29, 2022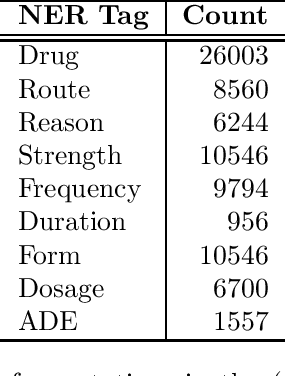
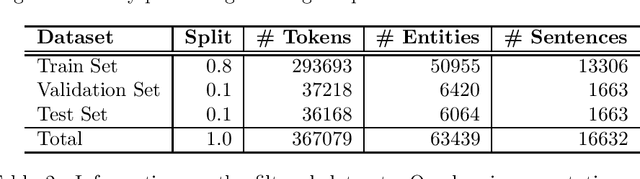
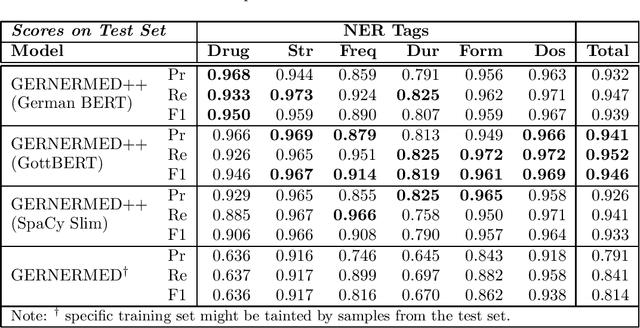
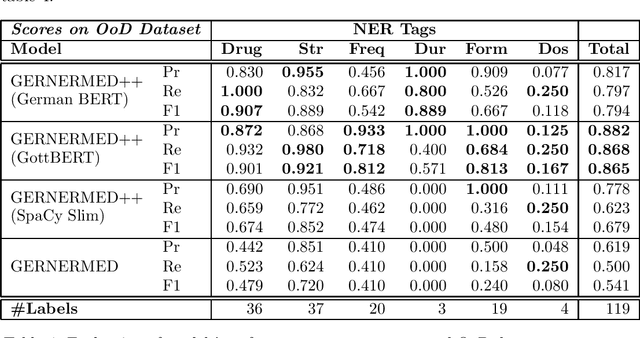
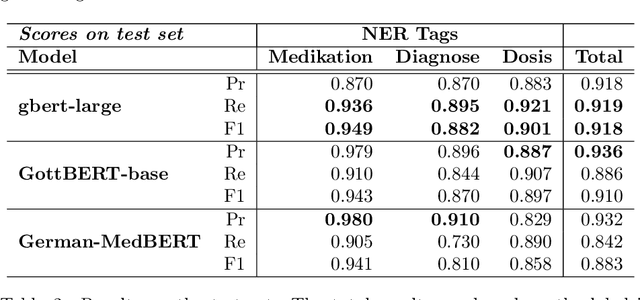
We present a statistical model for German medical natural language processing trained for named entity recognition (NER) as an open, publicly available model. The work serves as a refined successor to our first GERNERMED model which is substantially outperformed by our work. We demonstrate the effectiveness of combining multiple techniques in order to achieve strong results in entity recognition performance by the means of transfer-learning on pretrained deep language models (LM), word-alignment and neural machine translation. Due to the sparse situation on open, public medical entity recognition models for German texts, this work offers benefits to the German research community on medical NLP as a baseline model. Since our model is based on public English data, its weights are provided without legal restrictions on usage and distribution. The sample code and the statistical model is available at: https://github.com/frankkramer-lab/GERNERMED-pp
GERNERMED -- An Open German Medical NER Model
Sep 24, 2021
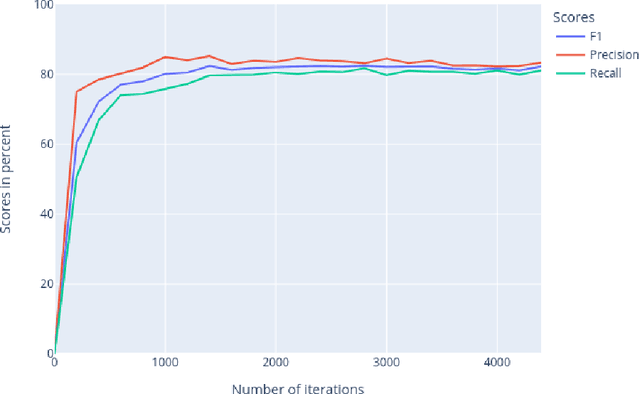
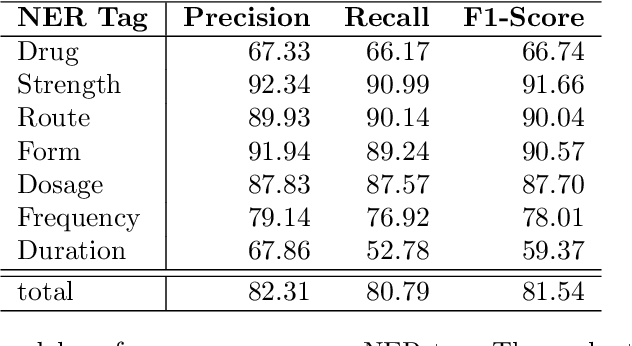
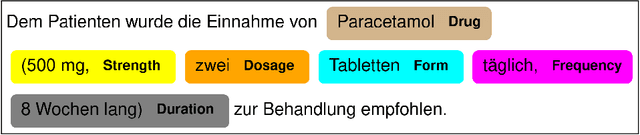
The current state of adoption of well-structured electronic health records and integration of digital methods for storing medical patient data in structured formats can often considered as inferior compared to the use of traditional, unstructured text based patient data documentation. Data mining in the field of medical data analysis often needs to rely solely on processing of unstructured data to retrieve relevant data. In natural language processing (NLP), statistical models have been shown successful in various tasks like part-of-speech tagging, relation extraction (RE) and named entity recognition (NER). In this work, we present GERNERMED, the first open, neural NLP model for NER tasks dedicated to detect medical entity types in German text data. Here, we avoid the conflicting goals of protection of sensitive patient data from training data extraction and the publication of the statistical model weights by training our model on a custom dataset that was translated from publicly available datasets in foreign language by a pretrained neural machine translation model. The sample code and the statistical model is available at: https://github.com/frankkramer-lab/GERNERMED
TOMAAT: volumetric medical image analysis as a cloud service
Apr 25, 2018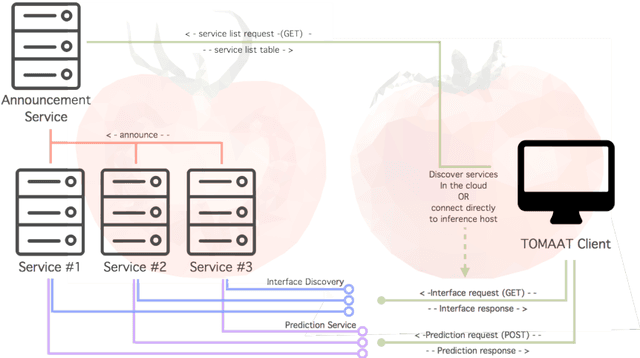

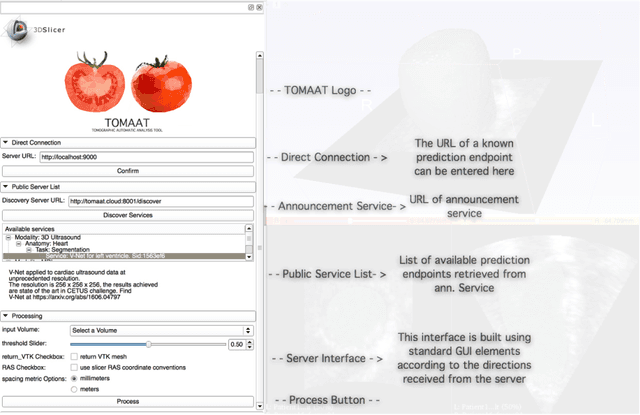
Deep learning has been recently applied to a multitude of computer vision and medical image analysis problems. Although recent research efforts have improved the state of the art, most of the methods cannot be easily accessed, compared or used by either researchers or the general public. Researchers often publish their code and trained models on the internet, but this does not always enable these approaches to be easily used or integrated in stand-alone applications and existing workflows. In this paper we propose a framework which allows easy deployment and access of deep learning methods for segmentation through a cloud-based architecture. Our approach comprises three parts: a server, which wraps trained deep learning models and their pre- and post-processing data pipelines and makes them available on the cloud; a client which interfaces with the server to obtain predictions on user data; a service registry that informs clients about available prediction endpoints that are available in the cloud. These three parts constitute the open-source TOMAAT framework.