 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Medical Information Extraction Workbench to Process German Clinical Text
Jul 08, 2022
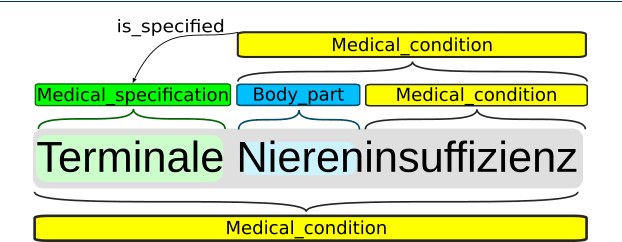

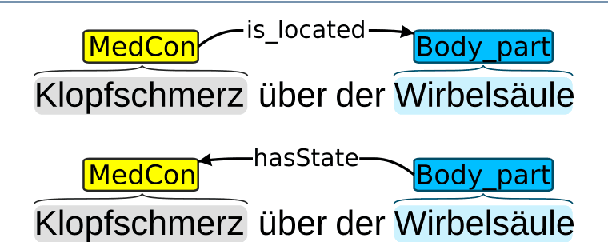
Background: In the information extraction and natural language processing domain, accessible datasets are crucial to reproduce and compare results. Publicly available implementations and tools can serve as benchmark and facilitate the development of more complex applications. However, in the context of clinical text processing the number of accessible datasets is scarce -- and so is the number of existing tools. One of the main reasons is the sensitivity of the data. This problem is even more evident for non-English languages. Approach: In order to address this situation, we introduce a workbench: a collection of German clinical text processing models. The models are trained on a de-identified corpus of German nephrology reports. Result: The presented models provide promising results on in-domain data. Moreover, we show that our models can be also successfully applied to other biomedical text in German. Our workbench is made publicly available so it can be used out of the box, as a benchmark or transferred to related problems.