 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATS: Adaptive Token Sampling For Efficient Vision Transformers
Nov 30, 2021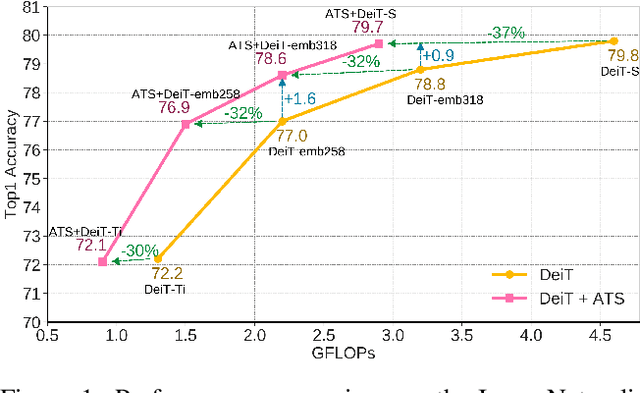
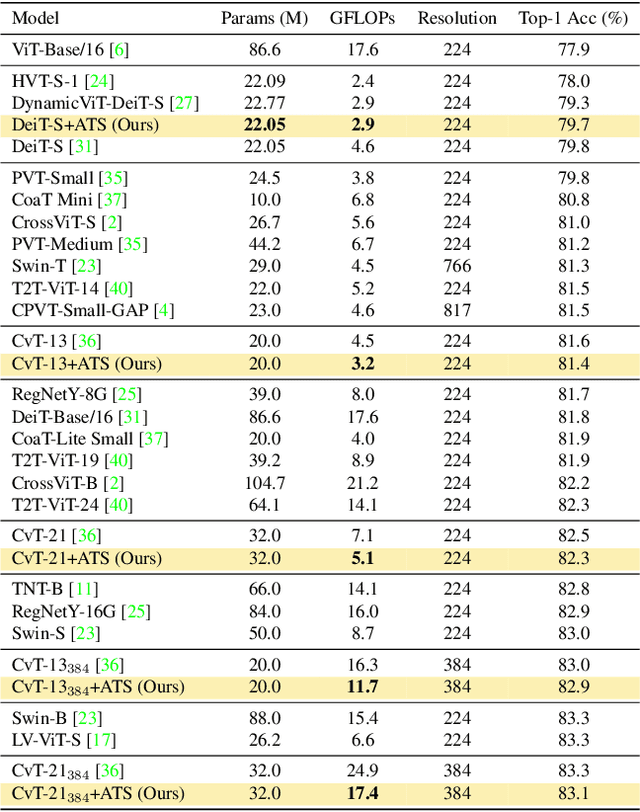
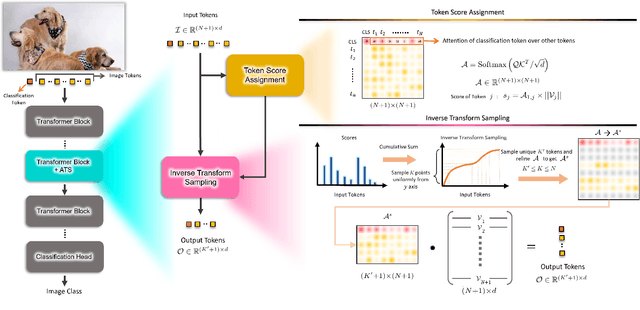

While state-of-the-art vision transformer models achieve promising results for image classification, they are computationally very expensive and require many GFLOPs. Although the GFLOPs of a vision transformer can be decreased by reducing the number of tokens in the network, there is no setting that is optimal for all input images. In this work, we, therefore, introduce a differentiable parameter-free Adaptive Token Sampling (ATS) module, which can be plugged into any existing vision transformer architecture. ATS empowers vision transformers by scoring and adaptively sampling significant tokens. As a result, the number of tokens is not anymore static but it varies for each input image. By integrating ATS as an additional layer within current transformer blocks, we can convert them into much more efficient vision transformers with an adaptive number of tokens. Since ATS is a parameter-free module, it can be added to off-the-shelf pretrained vision transformers as a plug-and-play module, thus reducing their GFLOPs without any additional training. However, due to its differentiable design, one can also train a vision transformer equipped with ATS. We evaluate our module on the ImageNet dataset by adding it to multiple state-of-the-art vision transformers. Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs) by 37% while preserving the accuracy.
Network Architecture Search for Face Enhancement
May 13, 2021
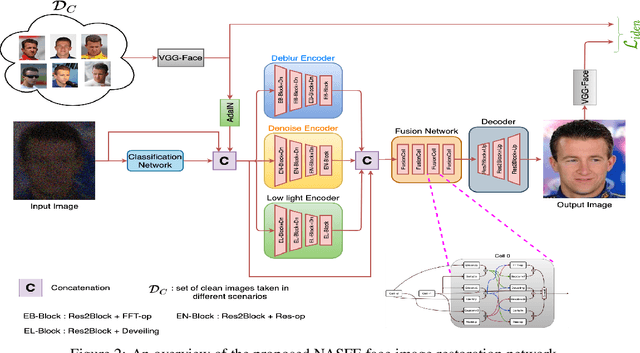
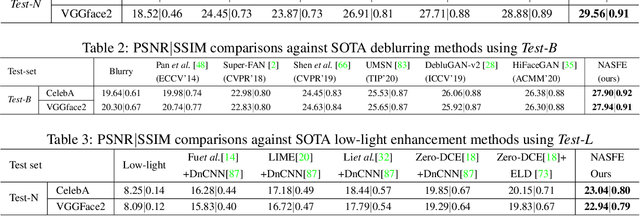
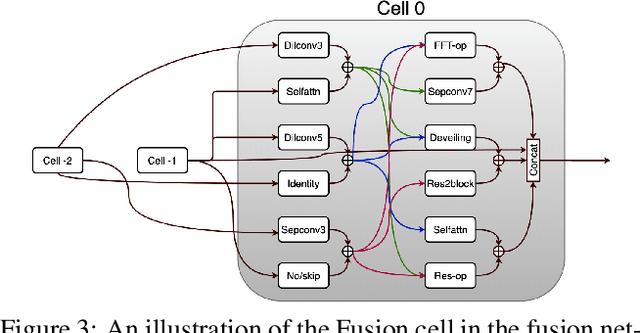
Various factors such as ambient lighting conditions, noise, motion blur, etc. affect the quality of captured face images. Poor quality face images often reduce the performance of face analysis and recognition systems. Hence, it is important to enhance the quality of face images collected in such conditions. We present a multi-task face restoration network, called Network Architecture Search for Face Enhancement (NASFE), which can enhance poor quality face images containing a single degradation (i.e. noise or blur) or multiple degradations (noise+blur+low-light). During training, NASFE uses clean face images of a person present in the degraded image to extract the identity information in terms of features for restoring the image. Furthermore, the network is guided by an identity-loss so that the identity in-formation is maintained in the restored image. Additionally, we propose a network architecture search-based fusion network in NASFE which fuses the task-specific features that are extracted using the task-specific encoders. We introduce FFT-op and deveiling operators in the fusion network to efficiently fuse the task-specific features. Comprehensive experiments on synthetic and real images demonstrate that the proposed method outperforms many recent state-of-the-art face restoration and enhancement methods in terms of quantitative and visual performance.
ImagePairs: Realistic Super Resolution Dataset via Beam Splitter Camera Rig
Apr 18, 2020
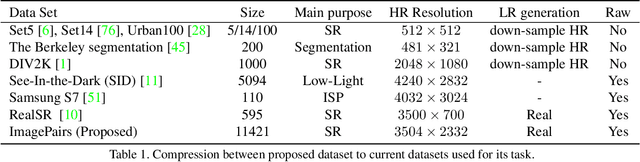
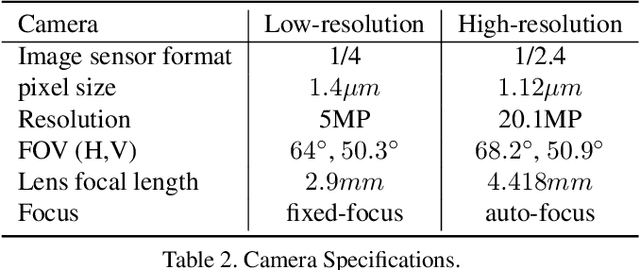
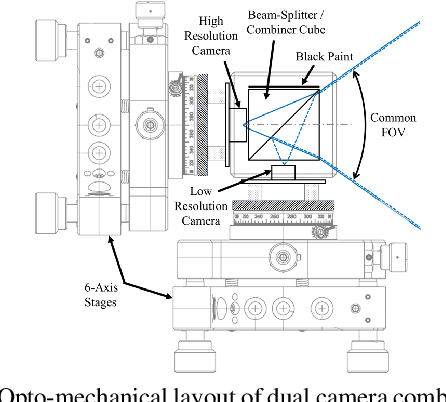
Super Resolution is the problem of recovering a high-resolution image from a single or multiple low-resolution images of the same scene. It is an ill-posed problem since high frequency visual details of the scene are completely lost in low-resolution images. To overcome this, many machine learning approaches have been proposed aiming at training a model to recover the lost details in the new scenes. Such approaches include the recent successful effort in utilizing deep learning techniques to solve super resolution problem. As proven, data itself plays a significant role in the machine learning process especially deep learning approaches which are data hungry. Therefore, to solve the problem, the process of gathering data and its formation could be equally as vital as the machine learning technique used. Herein, we are proposing a new data acquisition technique for gathering real image data set which could be used as an input for super resolution, noise cancellation and quality enhancement techniques. We use a beam-splitter to capture the same scene by a low resolution camera and a high resolution camera. Since we also release the raw images, this large-scale dataset could be used for other tasks such as ISP generation. Unlike current small-scale dataset used for these tasks, our proposed dataset includes 11,421 pairs of low-resolution high-resolution images of diverse scenes. To our knowledge this is the most complete dataset for super resolution, ISP and image quality enhancement. The benchmarking result shows how the new dataset can be successfully used to significantly improve the quality of real-world image super resolution.
MMTM: Multimodal Transfer Module for CNN Fusion
Nov 20, 2019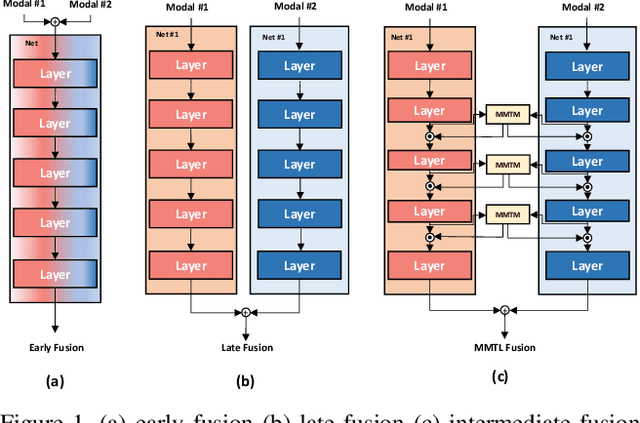

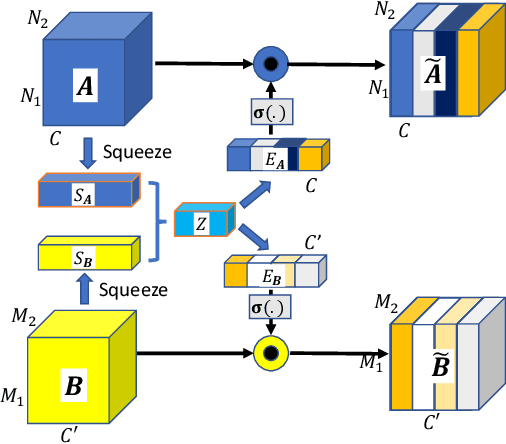
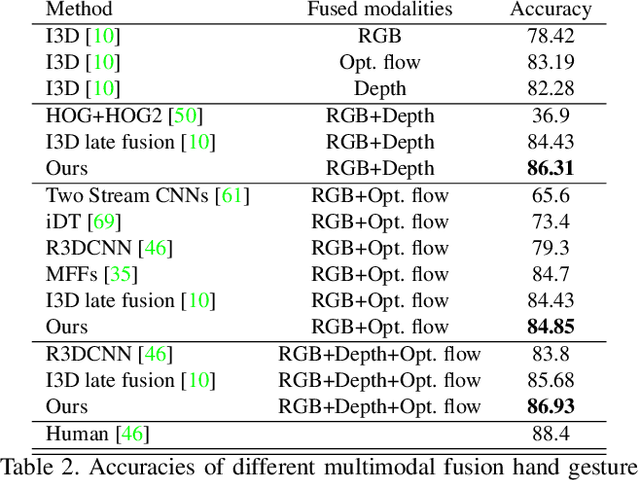
In late fusion, each modality is processed in a separate unimodal Convolutional Neural Network (CNN) stream and the scores of each modality are fused at the end. Due to its simplicity late fusion is still the predominant approach in many state-of-the-art multimodal applications. In this paper, we present a simple neural network module for leveraging the knowledge from multiple modalities in convolutional neural networks. The propose unit, named Multimodal Transfer Module (MMTM), can be added at different levels of the feature hierarchy, enabling slow modality fusion. Using squeeze and excitation operations, MMTM utilizes the knowledge of multiple modalities to recalibrate the channel-wise features in each CNN stream. Despite other intermediate fusion methods, the proposed module could be used for feature modality fusion in convolution layers with different spatial dimensions. Another advantage of the proposed method is that it could be added among unimodal branches with minimum changes in the their network architectures, allowing each branch to be initialized with existing pretrained weights. Experimental results show that our framework improves the recognition accuracy of well-known multimodal networks. We demonstrate state-of-the-art or competitive performance on four datasets that span the task domains of dynamic hand gesture recognition, speech enhancement, and action recognition with RGB and body joints.
Improving the Performance of Unimodal Dynamic Hand-Gesture Recognition with Multimodal Training
Dec 14, 2018
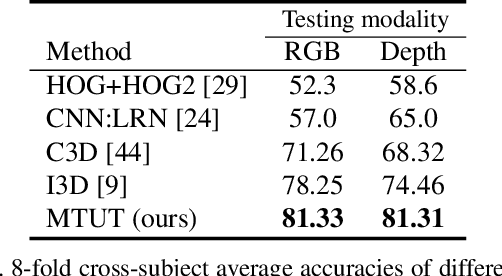


We present an efficient approach for leveraging the knowledge from multiple modalities in training unimodal 3D convolutional neural networks (3D-CNNs) for the task of dynamic hand gesture recognition. Instead of explicitly combining multimodal information, which is commonplace in many state-of-the-art methods, we propose a different framework in which we embed the knowledge of multiple modalities in individual networks so that each unimodal network can achieve an improved performance. In particular, we dedicate separate networks per available modality and enforce them to collaborate and learn to develop networks with common semantics and better representations. We introduce a "spatiotemporal semantic alignment" loss (SSA) to align the content of the features from different networks. In addition, we regularize this loss with our proposed "focal regularization parameter" to avoid negative knowledge transfer. Experimental results show that our framework improves the test time recognition accuracy of unimodal networks, and provides the state-of-the-art performance on various dynamic hand gesture recognition datasets.
MS-ASL: A Large-Scale Data Set and Benchmark for Understanding American Sign Language
Dec 03, 2018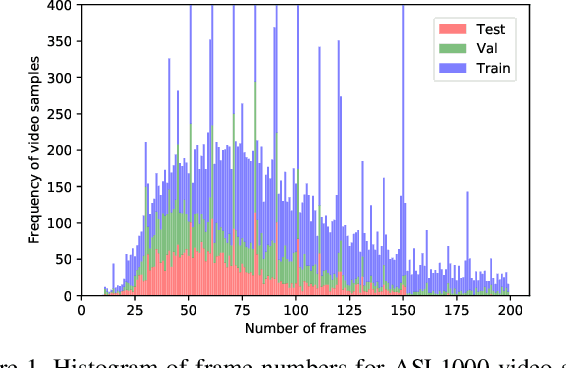

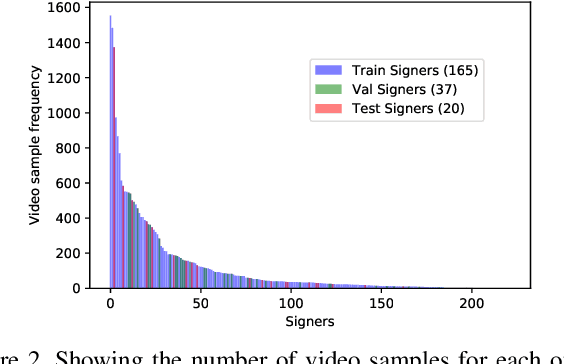
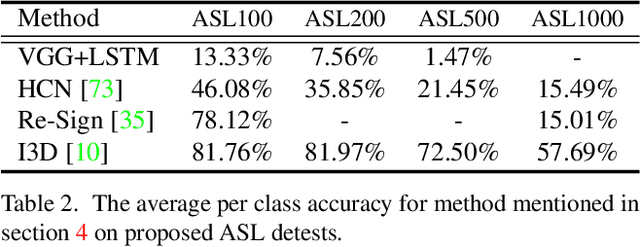
Computer Vision has been improved significantly in the past few decades. It has enabled machine to do many human tasks. However, the real challenge is in enabling machine to carry out tasks that an average human does not have the skills for. One such challenge that we have tackled in this paper is providing accessibility for deaf individual by providing means of communication with others with the aid of computer vision. Unlike other frequent works focusing on multiple camera, depth camera, electrical glove or visual gloves, we focused on the sole use of RGB which allows everybody to communicate with a deaf individual through their personal devices. This is not a new approach but the lack of realistic large-scale data set prevented recent computer vision trends on video classification in this filed. In this paper, we propose the first large scale ASL data set that covers over 200 signers, signer independent sets, challenging and unconstrained recording conditions and a large class count of 1000 signs. We evaluate baselines from action recognition techniques on the data set. We propose I3D, known from video classifications, as a powerful and suitable architecture for sign language recognition. We also propose new pre-trained model more appropriate for sign language recognition. Finally, We estimate the effect of number of classes and number of training samples on the recognition accuracy.
DIY Human Action Data Set Generation
Mar 29, 2018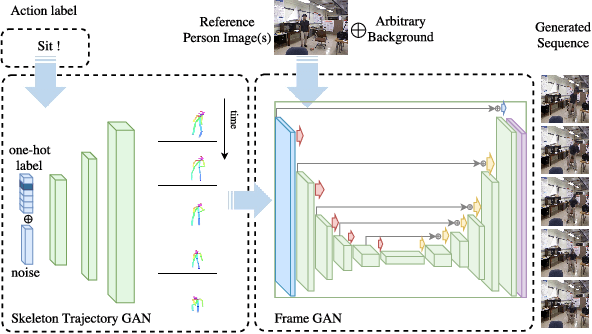
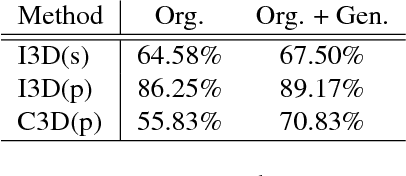
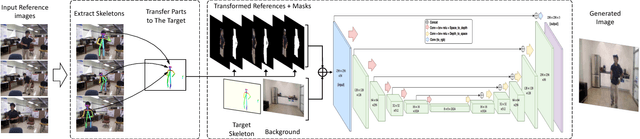
The recent successes in applying deep learning techniques to solve standard computer vision problems has aspired researchers to propose new computer vision problems in different domains. As previously established in the field, training data itself plays a significant role in the machine learning process, especially deep learning approaches which are data hungry. In order to solve each new problem and get a decent performance, a large amount of data needs to be captured which may in many cases pose logistical difficulties. Therefore, the ability to generate de novo data or expand an existing data set, however small, in order to satisfy data requirement of current networks may be invaluable. Herein, we introduce a novel way to partition an action video clip into action, subject and context. Each part is manipulated separately and reassembled with our proposed video generation technique. Furthermore, our novel human skeleton trajectory generation along with our proposed video generation technique, enables us to generate unlimited action recognition training data. These techniques enables us to generate video action clips from an small set without costly and time-consuming data acquisition. Lastly, we prove through extensive set of experiments on two small human action recognition data sets, that this new data generation technique can improve the performance of current action recognition neural nets.
Camera Calibration for Daylight Specular-Point Locus
Dec 12, 2017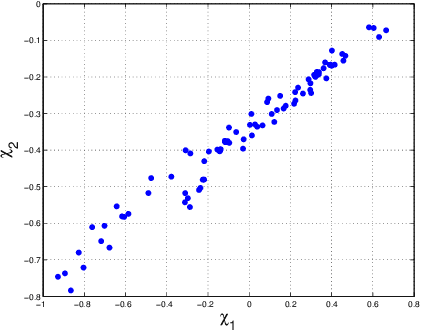
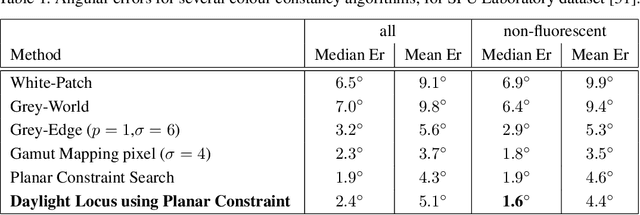
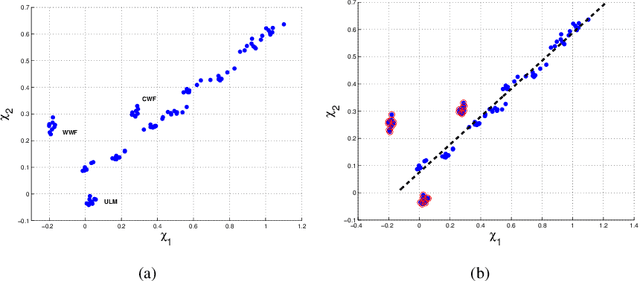

In this paper we present a new camera calibration method aimed at finding a straight-line locus, in a special colour feature space, that is traversed by daylights and as well also approximately followed by specular points. The aim of the calibration is to enable recovering the colour of the illuminant in a scene, using the calibrated camera. First we prove theoretically that any candidate specular points, for an image that is generated by a specific camera and taken under a daylight, must lie on a straight line in log-chromaticity space, for a chromaticity that is generated using a geometric-mean denominator. Use is made of the assumptions that daylight illuminants can be approximated using Planckians and that camera sensors are narrowband or can be made so by spectral sharpening. Then we show how a particular camera can be calibrated so as to discover this locus. As applications we use this curve for illuminant detection, and also for re-lighting of images to show they would appear under lighting having a different colour temperature.