 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATS: Adaptive Token Sampling For Efficient Vision Transformers
Nov 30, 2021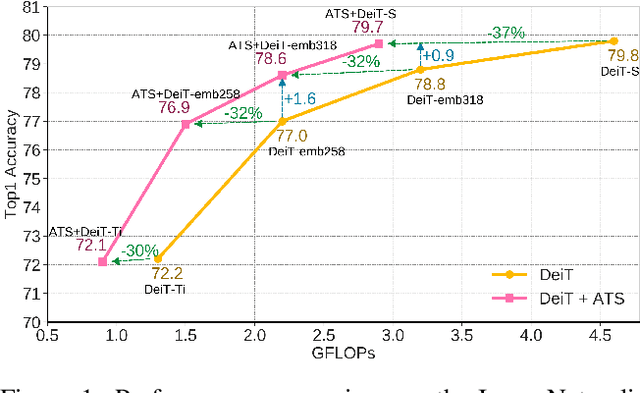
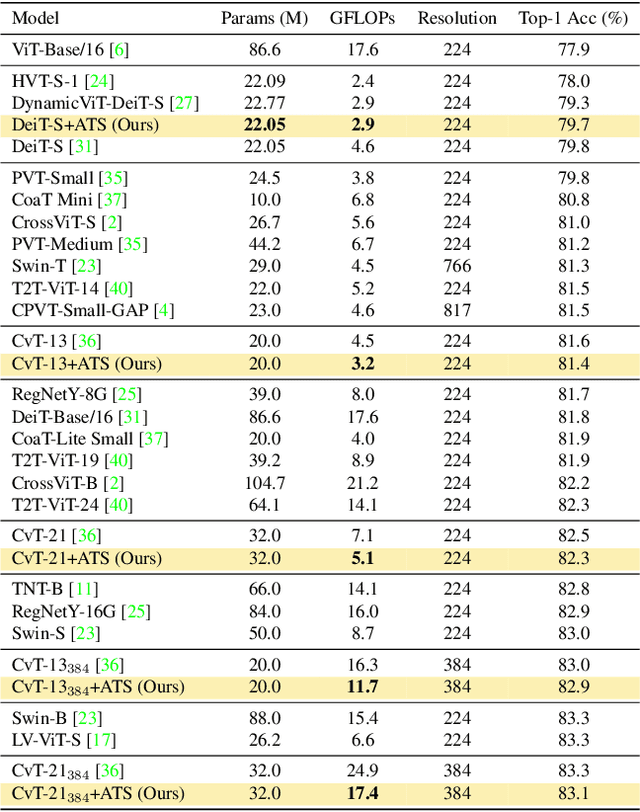
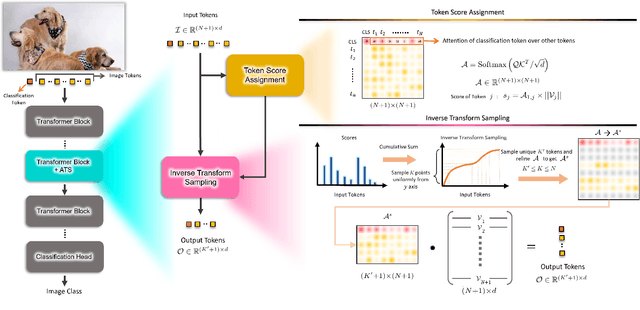

While state-of-the-art vision transformer models achieve promising results for image classification, they are computationally very expensive and require many GFLOPs. Although the GFLOPs of a vision transformer can be decreased by reducing the number of tokens in the network, there is no setting that is optimal for all input images. In this work, we, therefore, introduce a differentiable parameter-free Adaptive Token Sampling (ATS) module, which can be plugged into any existing vision transformer architecture. ATS empowers vision transformers by scoring and adaptively sampling significant tokens. As a result, the number of tokens is not anymore static but it varies for each input image. By integrating ATS as an additional layer within current transformer blocks, we can convert them into much more efficient vision transformers with an adaptive number of tokens. Since ATS is a parameter-free module, it can be added to off-the-shelf pretrained vision transformers as a plug-and-play module, thus reducing their GFLOPs without any additional training. However, due to its differentiable design, one can also train a vision transformer equipped with ATS. We evaluate our module on the ImageNet dataset by adding it to multiple state-of-the-art vision transformers. Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs) by 37% while preserving the accuracy.