 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking at the Edge of Comprehension
Feb 15, 2026As frontier Large Language Models (LLMs) increasingly saturate new benchmarks shortly after they are published, benchmarking itself is at a juncture: if frontier models keep improving, it will become increasingly hard for humans to generate discriminative tasks, provide accurate ground-truth answers, or evaluate complex solutions. If benchmarking becomes infeasible, our ability to measure any progress in AI is at stake. We refer to this scenario as the post-comprehension regime. In this work, we propose Critique-Resilient Benchmarking, an adversarial framework designed to compare models even when full human understanding is infeasible. Our technique relies on the notion of critique-resilient correctness: an answer is deemed correct if no adversary has convincingly proved otherwise. Unlike standard benchmarking, humans serve as bounded verifiers and focus on localized claims, which preserves evaluation integrity beyond full comprehension of the task. Using an itemized bipartite Bradley-Terry model, we jointly rank LLMs by their ability to solve challenging tasks and to generate difficult yet solvable questions. We showcase the effectiveness of our method in the mathematical domain across eight frontier LLMs, showing that the resulting scores are stable and correlate with external capability measures. Our framework reformulates benchmarking as an adversarial generation-evaluation game in which humans serve as final adjudicators.
A Fragile Guardrail: Diffusion LLM's Safety Blessing and Its Failure Mode
Jan 30, 2026Diffusion large language models (D-LLMs) offer an alternative to autoregressive LLMs (AR-LLMs) and have demonstrated advantages in generation efficiency. Beyond the utility benefits, we argue that D-LLMs exhibit a previously underexplored safety blessing: their diffusion-style generation confers intrinsic robustness against jailbreak attacks originally designed for AR-LLMs. In this work, we provide an initial analysis of the underlying mechanism, showing that the diffusion trajectory induces a stepwise reduction effect that progressively suppresses unsafe generations. This robustness, however, is not absolute. We identify a simple yet effective failure mode, termed context nesting, where harmful requests are embedded within structured benign contexts, effectively bypassing the stepwise reduction mechanism. Empirically, we show that this simple strategy is sufficient to bypass D-LLMs' safety blessing, achieving state-of-the-art attack success rates across models and benchmarks. Most notably, it enables the first successful jailbreak of Gemini Diffusion, to our knowledge, exposing a critical vulnerability in commercial D-LLMs. Together, our results characterize both the origins and the limits of D-LLMs' safety blessing, constituting an early-stage red-teaming of D-LLMs.
ATS: Adaptive Token Sampling For Efficient Vision Transformers
Nov 30, 2021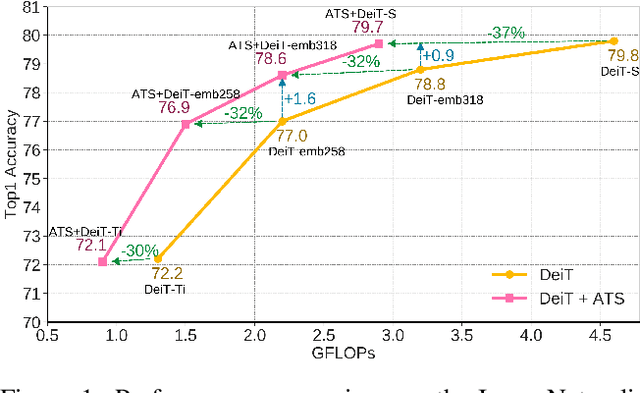
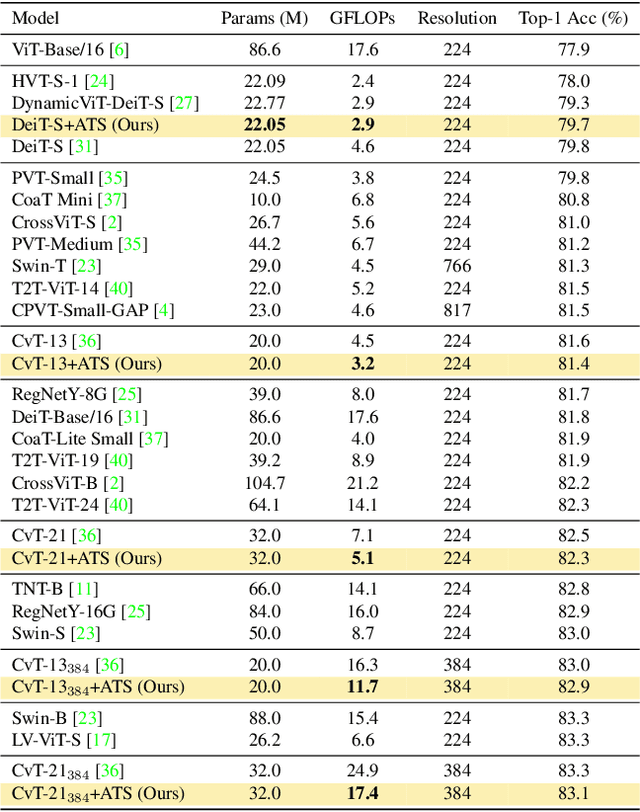
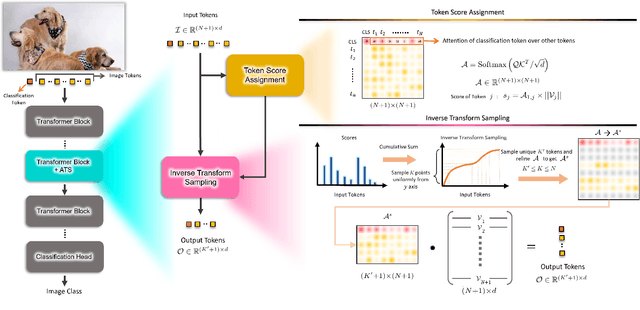

While state-of-the-art vision transformer models achieve promising results for image classification, they are computationally very expensive and require many GFLOPs. Although the GFLOPs of a vision transformer can be decreased by reducing the number of tokens in the network, there is no setting that is optimal for all input images. In this work, we, therefore, introduce a differentiable parameter-free Adaptive Token Sampling (ATS) module, which can be plugged into any existing vision transformer architecture. ATS empowers vision transformers by scoring and adaptively sampling significant tokens. As a result, the number of tokens is not anymore static but it varies for each input image. By integrating ATS as an additional layer within current transformer blocks, we can convert them into much more efficient vision transformers with an adaptive number of tokens. Since ATS is a parameter-free module, it can be added to off-the-shelf pretrained vision transformers as a plug-and-play module, thus reducing their GFLOPs without any additional training. However, due to its differentiable design, one can also train a vision transformer equipped with ATS. We evaluate our module on the ImageNet dataset by adding it to multiple state-of-the-art vision transformers. Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs) by 37% while preserving the accuracy.
Cross-modal Spectrum Transformation Network For Acoustic Scene classification
Aug 13, 2021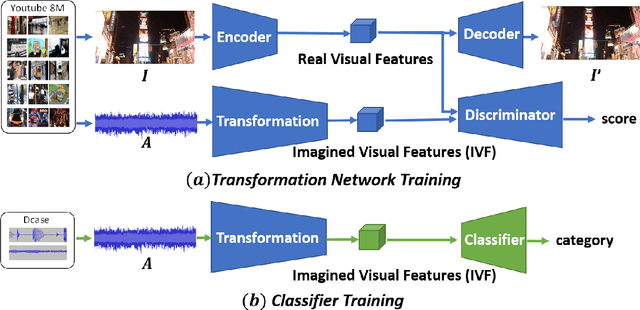
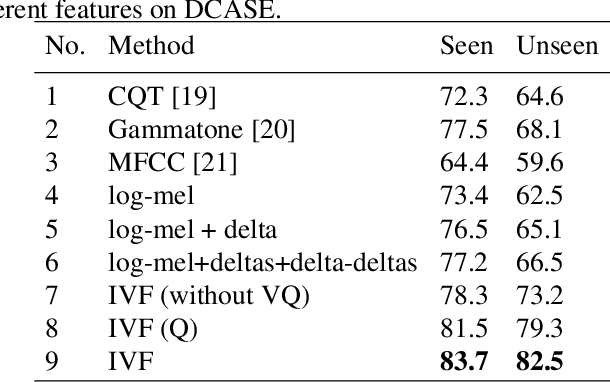
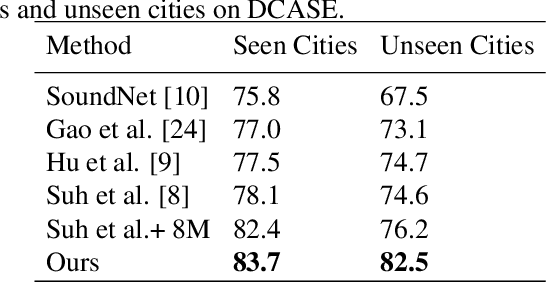
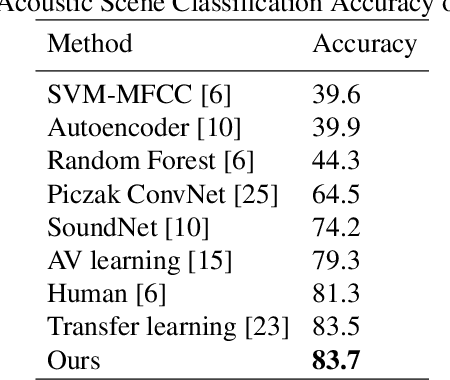
Convolutional neural networks (CNNs) with log-mel spectrum features have shown promising results for acoustic scene classification tasks. However, the performance of these CNN based classifiers is still lacking as they do not generalise well for unknown environments. To address this issue, we introduce an acoustic spectrum transformation network where traditional log-mel spectrums are transformed into imagined visual features (IVF). The imagined visual features are learned by exploiting the relationship between audio and visual features present in video recordings. An auto-encoder is used to encode images as visual features and a transformation network learns how to generate imagined visual features from log-mel. Our model is trained on a large dataset of Youtube videos. We test our proposed method on the scene classification task of DCASE and ESC-50, where our method outperforms other spectrum features, especially for unseen environments.
Relighting Images in the Wild with a Self-Supervised Siamese Auto-Encoder
Dec 11, 2020
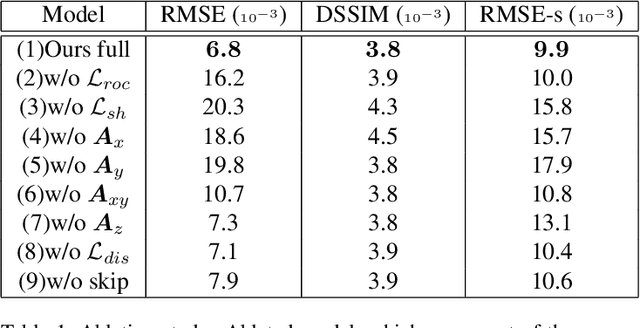
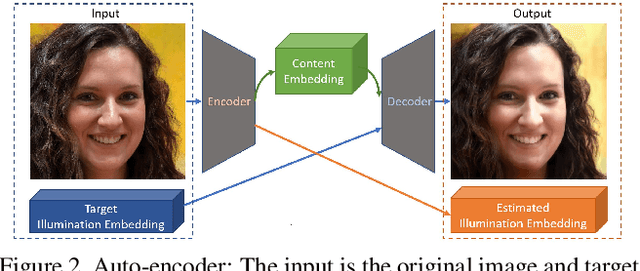
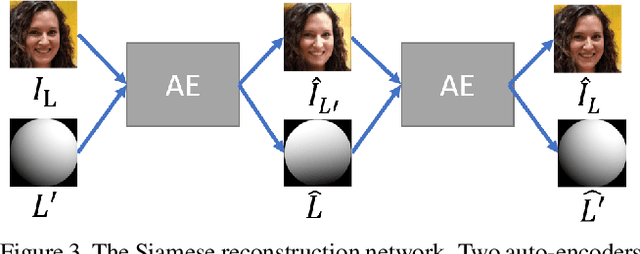
We propose a self-supervised method for image relighting of single view images in the wild. The method is based on an auto-encoder which deconstructs an image into two separate encodings, relating to the scene illumination and content, respectively. In order to disentangle this embedding information without supervision, we exploit the assumption that some augmentation operations do not affect the image content and only affect the direction of the light. A novel loss function, called spherical harmonic loss, is introduced that forces the illumination embedding to convert to a spherical harmonic vector. We train our model on large-scale datasets such as Youtube 8M and CelebA. Our experiments show that our method can correctly estimate scene illumination and realistically re-light input images, without any supervision or a prior shape model. Compared to supervised methods, our approach has similar performance and avoids common lighting artifacts.