 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Spatiotemporal Exploration for Reinforcement Learning in Video Question Answering
Apr 02, 2026We introduce STRIVE (SpatioTemporal Reinforcement with Importance-aware Variant Exploration), a structured reinforcement learning framework for video question answering. While group-based policy optimization methods have shown promise in large multimodal models, they often suffer from low reward variance when responses exhibit similar correctness, leading to weak or unstable advantage estimates. STRIVE addresses this limitation by constructing multiple spatiotemporal variants of each input video and performing joint normalization across both textual generations and visual variants. By expanding group comparisons beyond linguistic diversity to structured visual perturbations, STRIVE enriches reward signals and promotes more stable and informative policy updates. To ensure exploration remains semantically grounded, we introduce an importance-aware sampling mechanism that prioritizes frames most relevant to the input question while preserving temporal coverage. This design encourages robust reasoning across complementary visual perspectives rather than overfitting to a single spatiotemporal configuration. Experiments on six challenging video reasoning benchmarks including VideoMME, TempCompass, VideoMMMU, MMVU, VSI-Bench, and PerceptionTest demonstrate consistent improvements over strong reinforcement learning baselines across multiple large multimodal models. Our results highlight the role of structured spatiotemporal exploration as a principled mechanism for stabilizing multimodal reinforcement learning and improving video reasoning performance.
Benchmarking at the Edge of Comprehension
Feb 15, 2026As frontier Large Language Models (LLMs) increasingly saturate new benchmarks shortly after they are published, benchmarking itself is at a juncture: if frontier models keep improving, it will become increasingly hard for humans to generate discriminative tasks, provide accurate ground-truth answers, or evaluate complex solutions. If benchmarking becomes infeasible, our ability to measure any progress in AI is at stake. We refer to this scenario as the post-comprehension regime. In this work, we propose Critique-Resilient Benchmarking, an adversarial framework designed to compare models even when full human understanding is infeasible. Our technique relies on the notion of critique-resilient correctness: an answer is deemed correct if no adversary has convincingly proved otherwise. Unlike standard benchmarking, humans serve as bounded verifiers and focus on localized claims, which preserves evaluation integrity beyond full comprehension of the task. Using an itemized bipartite Bradley-Terry model, we jointly rank LLMs by their ability to solve challenging tasks and to generate difficult yet solvable questions. We showcase the effectiveness of our method in the mathematical domain across eight frontier LLMs, showing that the resulting scores are stable and correlate with external capability measures. Our framework reformulates benchmarking as an adversarial generation-evaluation game in which humans serve as final adjudicators.
DocSLM: A Small Vision-Language Model for Long Multimodal Document Understanding
Nov 17, 2025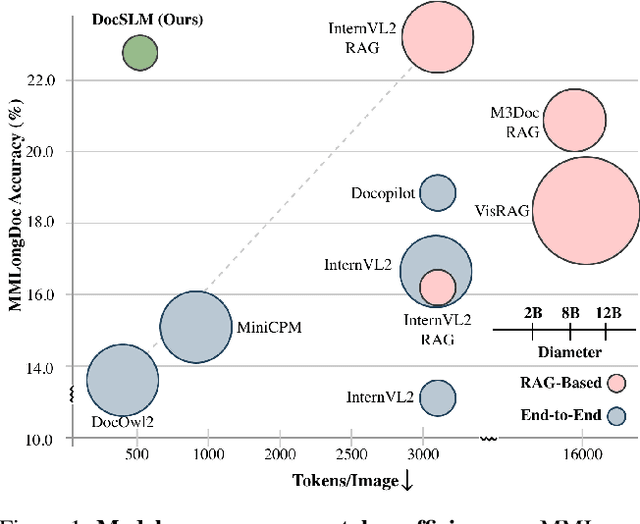

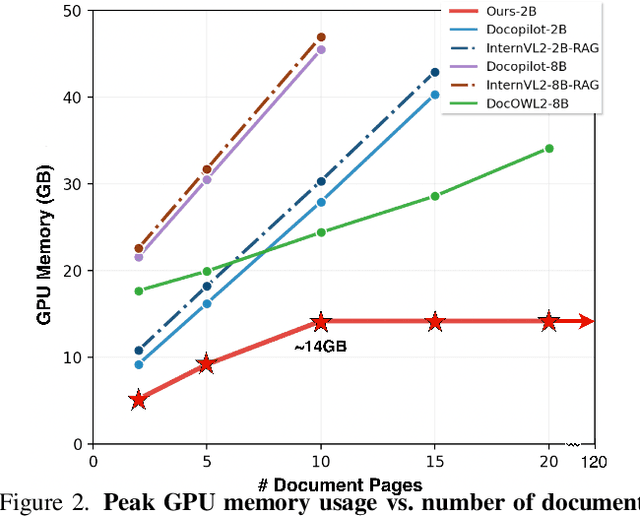
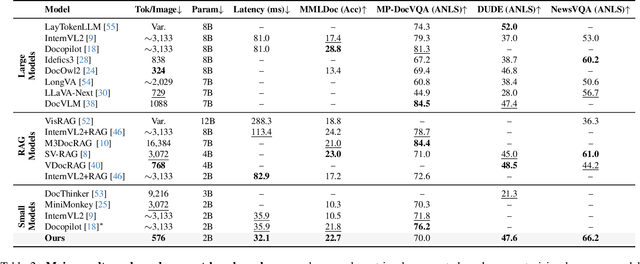
Large Vision-Language Models (LVLMs) have demonstrated strong multimodal reasoning capabilities on long and complex documents. However, their high memory footprint makes them impractical for deployment on resource-constrained edge devices. We present DocSLM, an efficient Small Vision-Language Model designed for long-document understanding under constrained memory resources. DocSLM incorporates a Hierarchical Multimodal Compressor that jointly encodes visual, textual, and layout information from each page into a fixed-length sequence, greatly reducing memory consumption while preserving both local and global semantics. To enable scalable processing over arbitrarily long inputs, we introduce a Streaming Abstention mechanism that operates on document segments sequentially and filters low-confidence responses using an entropy-based uncertainty calibrator. Across multiple long multimodal document benchmarks, DocSLM matches or surpasses state-of-the-art methods while using 82\% fewer visual tokens, 75\% fewer parameters, and 71\% lower latency, delivering reliable multimodal document understanding on lightweight edge devices. Code is available in the supplementary material.
Latent Directions: A Simple Pathway to Bias Mitigation in Generative AI
Jun 10, 2024



Mitigating biases in generative AI and, particularly in text-to-image models, is of high importance given their growing implications in society. The biased datasets used for training pose challenges in ensuring the responsible development of these models, and mitigation through hard prompting or embedding alteration, are the most common present solutions. Our work introduces a novel approach to achieve diverse and inclusive synthetic images by learning a direction in the latent space and solely modifying the initial Gaussian noise provided for the diffusion process. Maintaining a neutral prompt and untouched embeddings, this approach successfully adapts to diverse debiasing scenarios, such as geographical biases. Moreover, our work proves it is possible to linearly combine these learned latent directions to introduce new mitigations, and if desired, integrate it with text embedding adjustments. Furthermore, text-to-image models lack transparency for assessing bias in outputs, unless visually inspected. Thus, we provide a tool to empower developers to select their desired concepts to mitigate. The project page with code is available online.
Cross-modal Spectrum Transformation Network For Acoustic Scene classification
Aug 13, 2021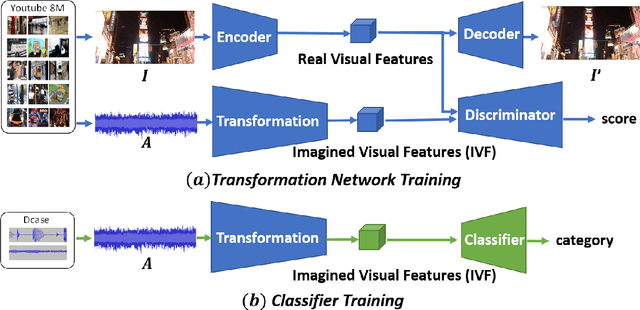
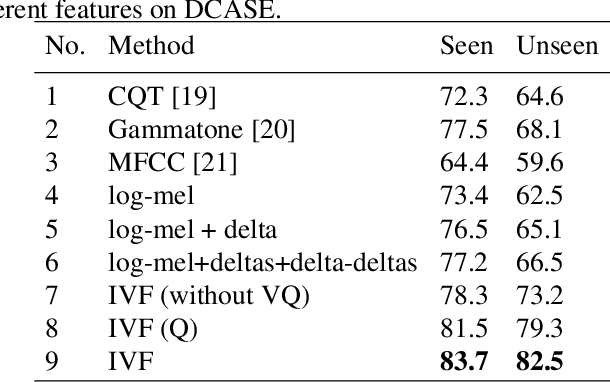
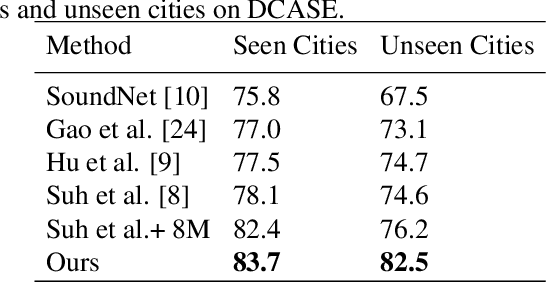
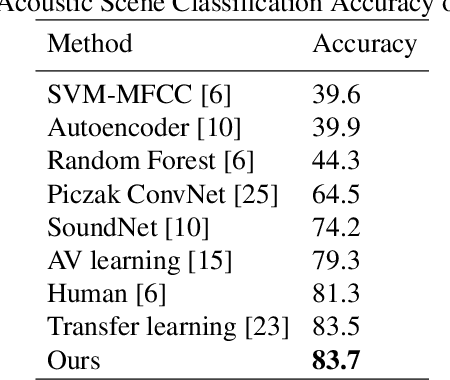
Convolutional neural networks (CNNs) with log-mel spectrum features have shown promising results for acoustic scene classification tasks. However, the performance of these CNN based classifiers is still lacking as they do not generalise well for unknown environments. To address this issue, we introduce an acoustic spectrum transformation network where traditional log-mel spectrums are transformed into imagined visual features (IVF). The imagined visual features are learned by exploiting the relationship between audio and visual features present in video recordings. An auto-encoder is used to encode images as visual features and a transformation network learns how to generate imagined visual features from log-mel. Our model is trained on a large dataset of Youtube videos. We test our proposed method on the scene classification task of DCASE and ESC-50, where our method outperforms other spectrum features, especially for unseen environments.
Relighting Images in the Wild with a Self-Supervised Siamese Auto-Encoder
Dec 11, 2020
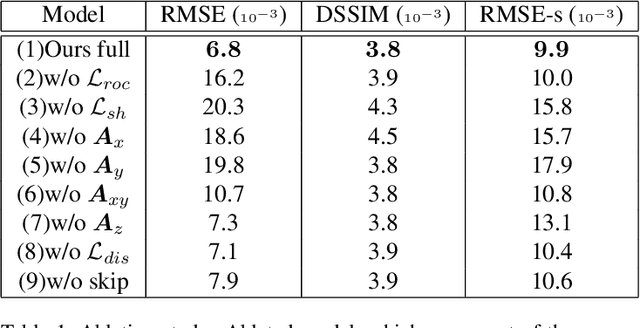
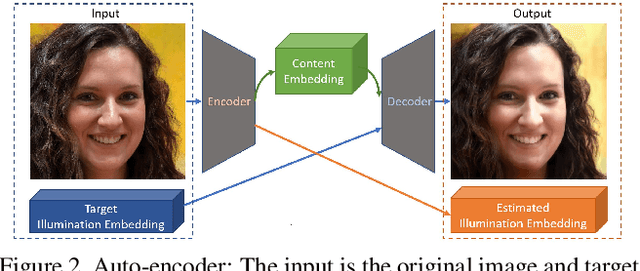
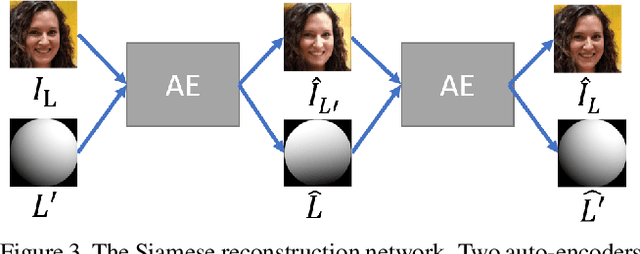
We propose a self-supervised method for image relighting of single view images in the wild. The method is based on an auto-encoder which deconstructs an image into two separate encodings, relating to the scene illumination and content, respectively. In order to disentangle this embedding information without supervision, we exploit the assumption that some augmentation operations do not affect the image content and only affect the direction of the light. A novel loss function, called spherical harmonic loss, is introduced that forces the illumination embedding to convert to a spherical harmonic vector. We train our model on large-scale datasets such as Youtube 8M and CelebA. Our experiments show that our method can correctly estimate scene illumination and realistically re-light input images, without any supervision or a prior shape model. Compared to supervised methods, our approach has similar performance and avoids common lighting artifacts.