 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Directions: A Simple Pathway to Bias Mitigation in Generative AI
Jun 10, 2024



Mitigating biases in generative AI and, particularly in text-to-image models, is of high importance given their growing implications in society. The biased datasets used for training pose challenges in ensuring the responsible development of these models, and mitigation through hard prompting or embedding alteration, are the most common present solutions. Our work introduces a novel approach to achieve diverse and inclusive synthetic images by learning a direction in the latent space and solely modifying the initial Gaussian noise provided for the diffusion process. Maintaining a neutral prompt and untouched embeddings, this approach successfully adapts to diverse debiasing scenarios, such as geographical biases. Moreover, our work proves it is possible to linearly combine these learned latent directions to introduce new mitigations, and if desired, integrate it with text embedding adjustments. Furthermore, text-to-image models lack transparency for assessing bias in outputs, unless visually inspected. Thus, we provide a tool to empower developers to select their desired concepts to mitigate. The project page with code is available online.
NP-Match: When Neural Processes meet Semi-Supervised Learning
Jul 03, 2022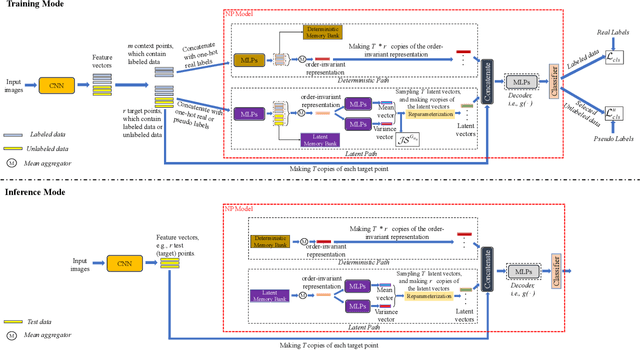
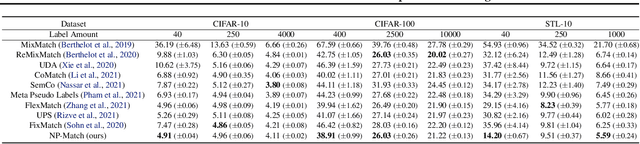
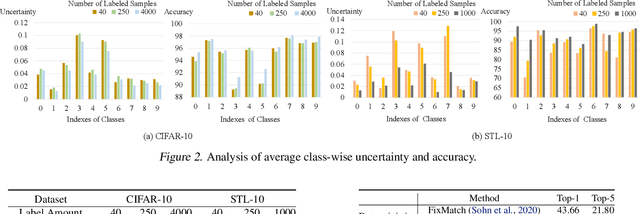
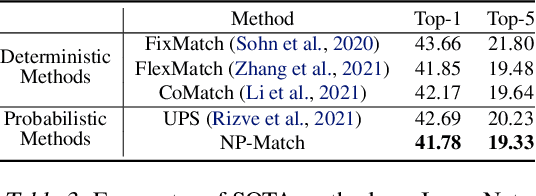
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on four public datasets, and NP-Match outperforms state-of-the-art (SOTA) results or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL.
Cross-modal Spectrum Transformation Network For Acoustic Scene classification
Aug 13, 2021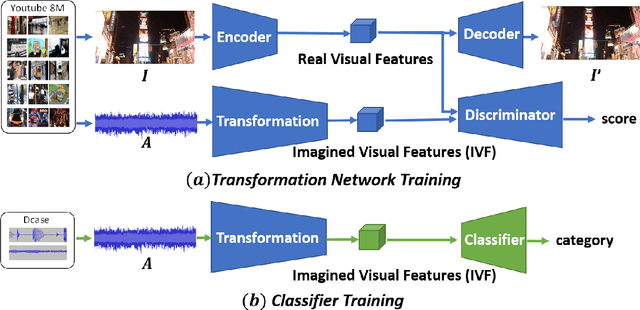
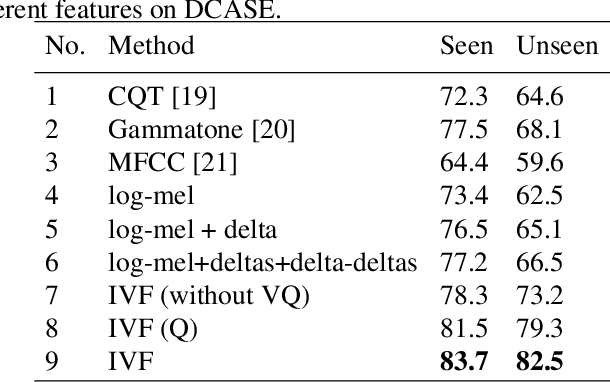
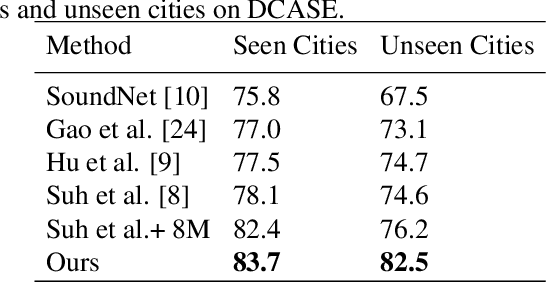
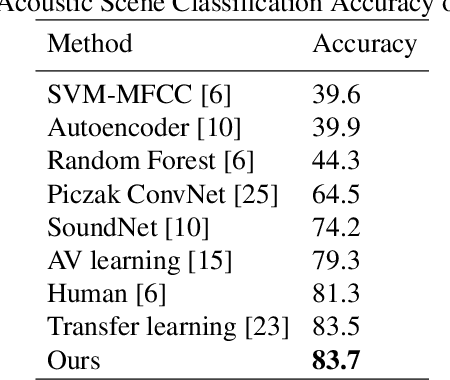
Convolutional neural networks (CNNs) with log-mel spectrum features have shown promising results for acoustic scene classification tasks. However, the performance of these CNN based classifiers is still lacking as they do not generalise well for unknown environments. To address this issue, we introduce an acoustic spectrum transformation network where traditional log-mel spectrums are transformed into imagined visual features (IVF). The imagined visual features are learned by exploiting the relationship between audio and visual features present in video recordings. An auto-encoder is used to encode images as visual features and a transformation network learns how to generate imagined visual features from log-mel. Our model is trained on a large dataset of Youtube videos. We test our proposed method on the scene classification task of DCASE and ESC-50, where our method outperforms other spectrum features, especially for unseen environments.
Relighting Images in the Wild with a Self-Supervised Siamese Auto-Encoder
Dec 11, 2020
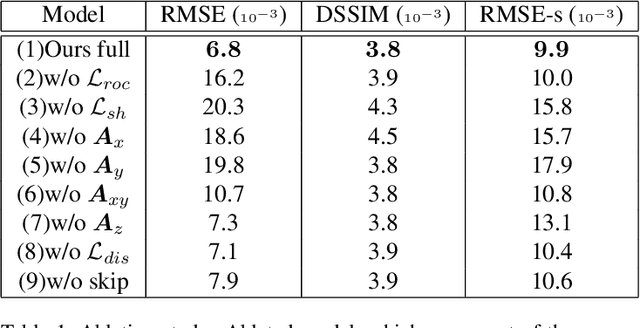
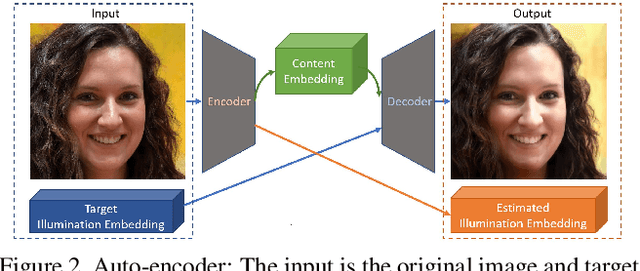
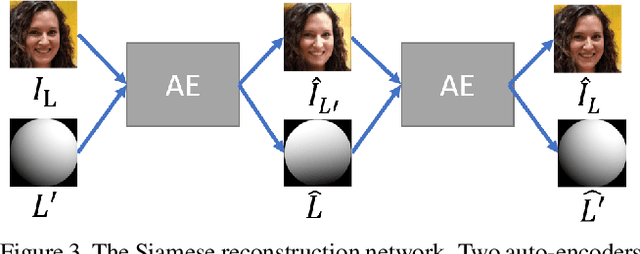
We propose a self-supervised method for image relighting of single view images in the wild. The method is based on an auto-encoder which deconstructs an image into two separate encodings, relating to the scene illumination and content, respectively. In order to disentangle this embedding information without supervision, we exploit the assumption that some augmentation operations do not affect the image content and only affect the direction of the light. A novel loss function, called spherical harmonic loss, is introduced that forces the illumination embedding to convert to a spherical harmonic vector. We train our model on large-scale datasets such as Youtube 8M and CelebA. Our experiments show that our method can correctly estimate scene illumination and realistically re-light input images, without any supervision or a prior shape model. Compared to supervised methods, our approach has similar performance and avoids common lighting artifacts.