 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelighting Images in the Wild with a Self-Supervised Siamese Auto-Encoder
Paper and Code

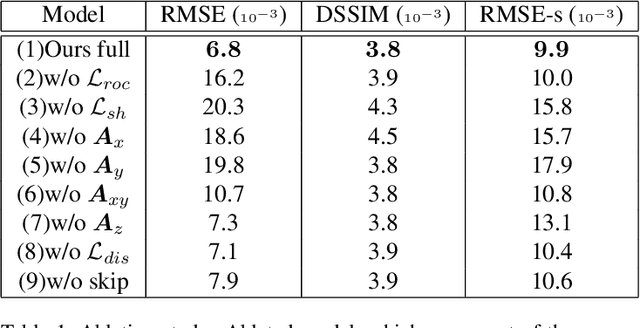
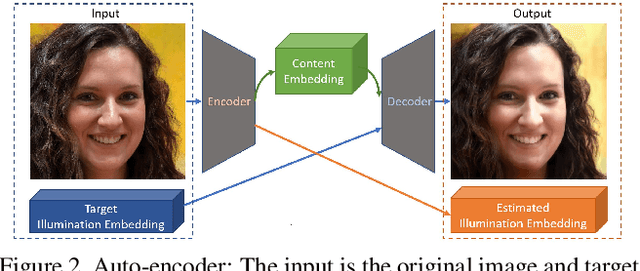
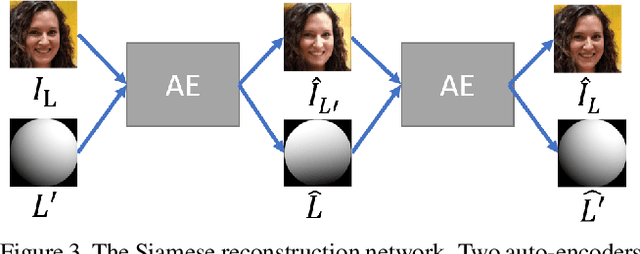
We propose a self-supervised method for image relighting of single view images in the wild. The method is based on an auto-encoder which deconstructs an image into two separate encodings, relating to the scene illumination and content, respectively. In order to disentangle this embedding information without supervision, we exploit the assumption that some augmentation operations do not affect the image content and only affect the direction of the light. A novel loss function, called spherical harmonic loss, is introduced that forces the illumination embedding to convert to a spherical harmonic vector. We train our model on large-scale datasets such as Youtube 8M and CelebA. Our experiments show that our method can correctly estimate scene illumination and realistically re-light input images, without any supervision or a prior shape model. Compared to supervised methods, our approach has similar performance and avoids common lighting artifacts.