 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Attention Heatmaps: How to Get Better Explanations for Multiple Instance Learning Models in Histopathology
Mar 09, 2026Multiple instance learning (MIL) has enabled substantial progress in computational histopathology, where a large amount of patches from gigapixel whole slide images are aggregated into slide-level predictions. Heatmaps are widely used to validate MIL models and to discover tissue biomarkers. Yet, the validity of these heatmaps has barely been investigated. In this work, we introduce a general framework for evaluating the quality of MIL heatmaps without requiring additional labels. We conduct a large-scale benchmark experiment to assess six explanation methods across histopathology task types (classification, regression, survival), MIL model architectures (Attention-, Transformer-, Mamba-based), and patch encoder backbones (UNI2, Virchow2). Our results show that explanation quality mostly depends on MIL model architecture and task type, with perturbation ("Single"), layer-wise relevance propagation (LRP), and integrated gradients (IG) consistently outperforming attention-based and gradient-based saliency heatmaps, which often fail to reflect model decision mechanisms. We further demonstrate the advanced capabilities of the best-performing explanation methods: (i) We provide a proof-of-concept that MIL heatmaps of a bulk gene expression prediction model can be correlated with spatial transcriptomics for biological validation, and (ii) showcase the discovery of distinct model strategies for predicting human papillomavirus (HPV) infection from head and neck cancer slides. Our work highlights the importance of validating MIL heatmaps and establishes that improved explainability can enable more reliable model validation and yield biological insights, making a case for a broader adoption of explainable AI in digital pathology. Our code is provided in a public GitHub repository: https://github.com/bifold-pathomics/xMIL/tree/xmil-journal
MambaLRP: Explaining Selective State Space Sequence Models
Jun 11, 2024



Recent sequence modeling approaches using Selective State Space Sequence Models, referred to as Mamba models, have seen a surge of interest. These models allow efficient processing of long sequences in linear time and are rapidly being adopted in a wide range of applications such as language modeling, demonstrating promising performance. To foster their reliable use in real-world scenarios, it is crucial to augment their transparency. Our work bridges this critical gap by bringing explainability, particularly Layer-wise Relevance Propagation (LRP), to the Mamba architecture. Guided by the axiom of relevance conservation, we identify specific components in the Mamba architecture, which cause unfaithful explanations. To remedy this issue, we propose MambaLRP, a novel algorithm within the LRP framework, which ensures a more stable and reliable relevance propagation through these components. Our proposed method is theoretically sound and excels in achieving state-of-the-art explanation performance across a diverse range of models and datasets. Moreover, MambaLRP facilitates a deeper inspection of Mamba architectures, uncovering various biases and evaluating their significance. It also enables the analysis of previous speculations regarding the long-range capabilities of Mamba models.
ATS: Adaptive Token Sampling For Efficient Vision Transformers
Nov 30, 2021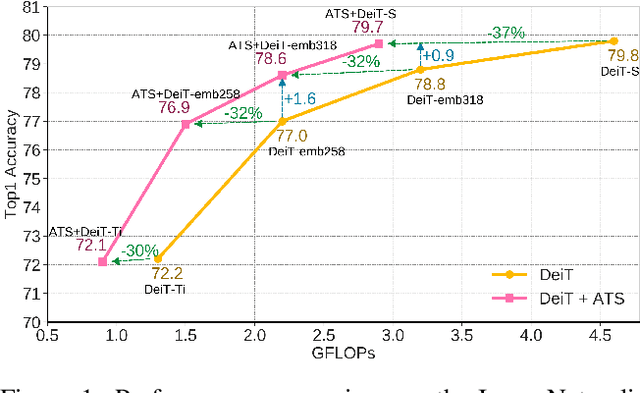
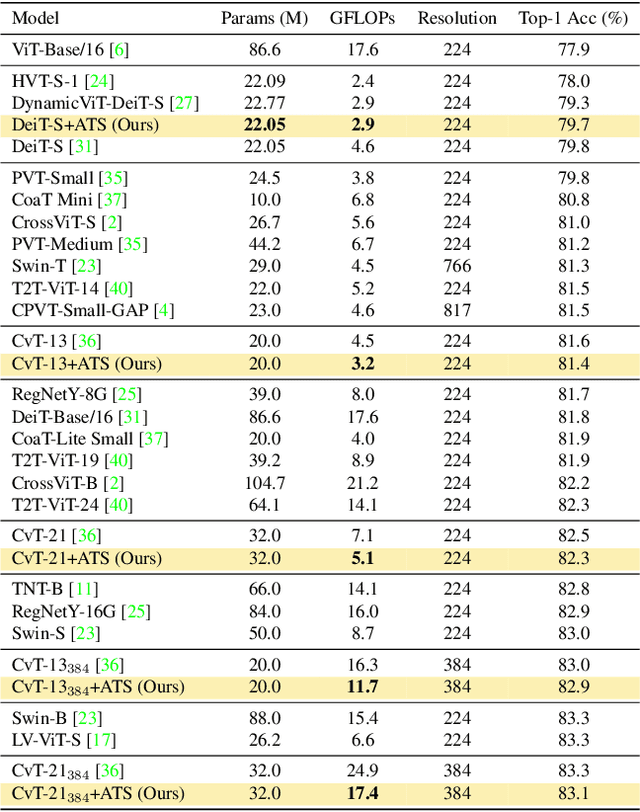
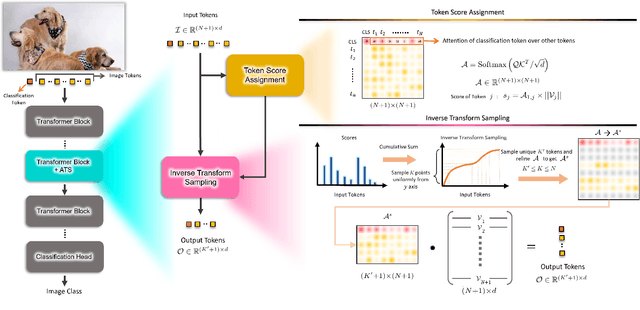

While state-of-the-art vision transformer models achieve promising results for image classification, they are computationally very expensive and require many GFLOPs. Although the GFLOPs of a vision transformer can be decreased by reducing the number of tokens in the network, there is no setting that is optimal for all input images. In this work, we, therefore, introduce a differentiable parameter-free Adaptive Token Sampling (ATS) module, which can be plugged into any existing vision transformer architecture. ATS empowers vision transformers by scoring and adaptively sampling significant tokens. As a result, the number of tokens is not anymore static but it varies for each input image. By integrating ATS as an additional layer within current transformer blocks, we can convert them into much more efficient vision transformers with an adaptive number of tokens. Since ATS is a parameter-free module, it can be added to off-the-shelf pretrained vision transformers as a plug-and-play module, thus reducing their GFLOPs without any additional training. However, due to its differentiable design, one can also train a vision transformer equipped with ATS. We evaluate our module on the ImageNet dataset by adding it to multiple state-of-the-art vision transformers. Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs) by 37% while preserving the accuracy.