 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfigurable Reward Model for Balanced Safety Alignment
May 28, 2026Aligning large language models (LLMs) to heterogeneous and rapidly evolving safety requirements remains a critical challenge. Existing instruction-tuned LLMs and standalone safety classifiers often fail to generalize to new safety configurations, motivating the need for Reward Models (RMs) that are explicitly configurable to changing specifications. We introduce the Configurable Safety Reward Model (CSRM), which is jointly optimized for calibrated safety compliance and reward modeling. Our approach is supported by configuration-targeted data augmentation that enforces instruction adherence while preserving relative severity structure. The resulting RM is sensitive to fine-grained safety configurations and conversational nuances, substantially improving generalization to previously unseen safety configurations. CSRM achieves state-of-the-art performance on recent configurable safety benchmarks, including CoSApien (94.6% F1) and DynaBench (75.8% F1), without requiring additional human annotation. When used for downstream safety alignment, CSRM yields LLMs with a significantly improved helpfulness-safety tradeoff compared to existing baselines.
A Robust Learning Approach to Domain Adaptive Object Detection
Apr 04, 2019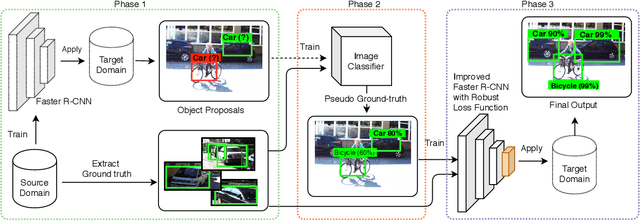

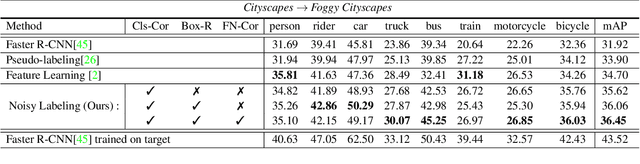

Domain shift is unavoidable in real-world applications of object detection. For example, in self-driving cars, the target domain consists of unconstrained road environments which cannot all possibly be observed in training data. Similarly, in surveillance applications sufficiently representative training data may be lacking due to privacy regulations. In this paper, we address the domain adaptation problem from the perspective of robust learning and show that the problem may be formulated as training with noisy labels. We propose a robust object detection framework that is resilient to noise in bounding box class labels, locations and size annotations. To adapt to the domain shift, the model is trained on the target domain using a set of noisy object bounding boxes that are obtained by a detection model trained only in the source domain. We evaluate the accuracy of our approach in various source/target domain pairs and demonstrate that the model significantly improves the state-of-the-art on multiple domain adaptation scenarios on the SIM10K, Cityscapes and KITTI datasets.
Distribution Aware Active Learning
May 23, 2018
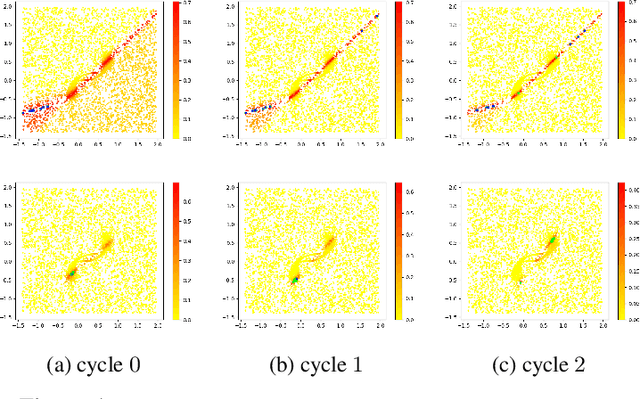
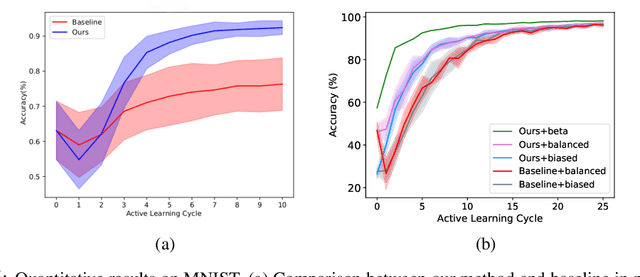
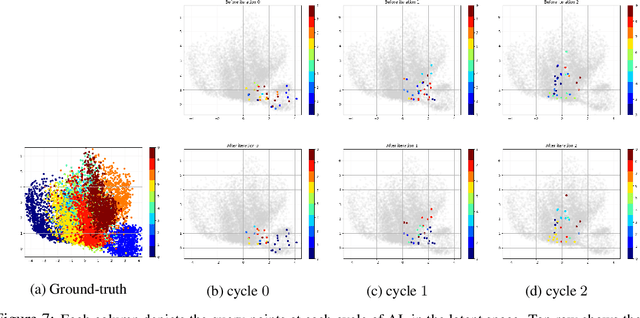
Discriminative learning machines often need a large set of labeled samples for training. Active learning (AL) settings assume that the learner has the freedom to ask an oracle to label its desired samples. Traditional AL algorithms heuristically choose query samples about which the current learner is uncertain. This strategy does not make good use of the structure of the dataset at hand and is prone to be misguided by outliers. To alleviate this problem, we propose to distill the structural information into a probabilistic generative model which acts as a \emph{teacher} in our model. The active \emph{learner} uses this information effectively at each cycle of active learning. The proposed method is generic and does not depend on the type of learner and teacher. We then suggest a query criterion for active learning that is aware of distribution of data and is more robust against outliers. Our method can be combined readily with several other query criteria for active learning. We provide the formulation and empirically show our idea via toy and real examples.
DIY Human Action Data Set Generation
Mar 29, 2018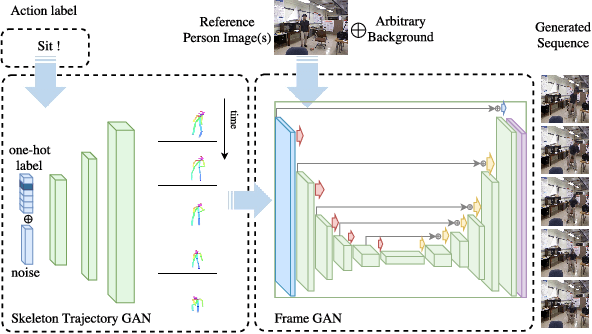
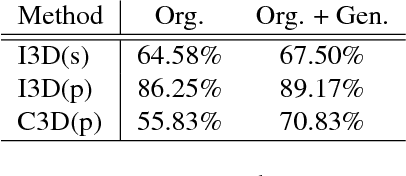
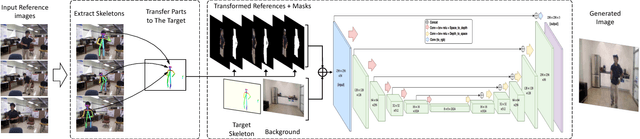
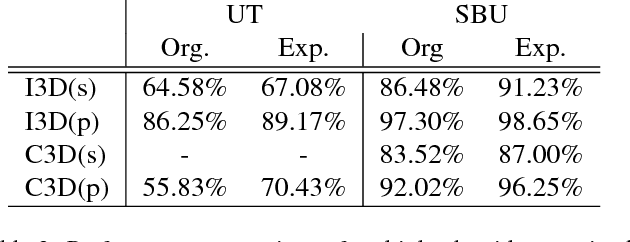
The recent successes in applying deep learning techniques to solve standard computer vision problems has aspired researchers to propose new computer vision problems in different domains. As previously established in the field, training data itself plays a significant role in the machine learning process, especially deep learning approaches which are data hungry. In order to solve each new problem and get a decent performance, a large amount of data needs to be captured which may in many cases pose logistical difficulties. Therefore, the ability to generate de novo data or expand an existing data set, however small, in order to satisfy data requirement of current networks may be invaluable. Herein, we introduce a novel way to partition an action video clip into action, subject and context. Each part is manipulated separately and reassembled with our proposed video generation technique. Furthermore, our novel human skeleton trajectory generation along with our proposed video generation technique, enables us to generate unlimited action recognition training data. These techniques enables us to generate video action clips from an small set without costly and time-consuming data acquisition. Lastly, we prove through extensive set of experiments on two small human action recognition data sets, that this new data generation technique can improve the performance of current action recognition neural nets.
Active Learning for Structured Prediction from Partially Labeled Data
Jun 09, 2017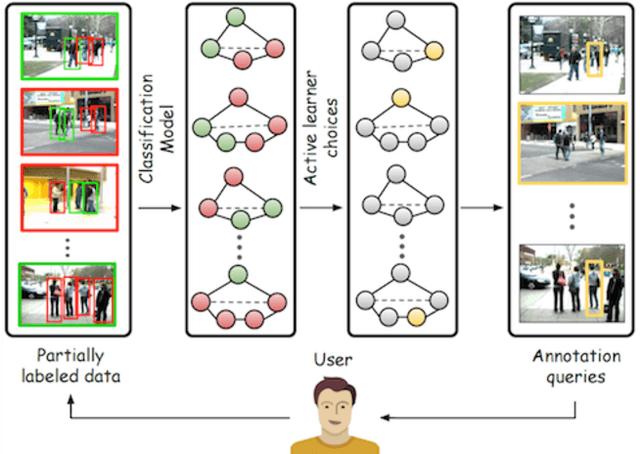
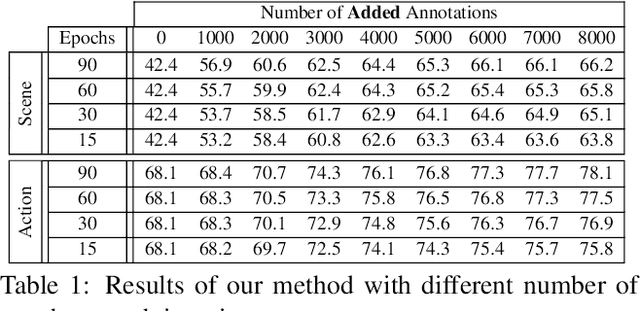
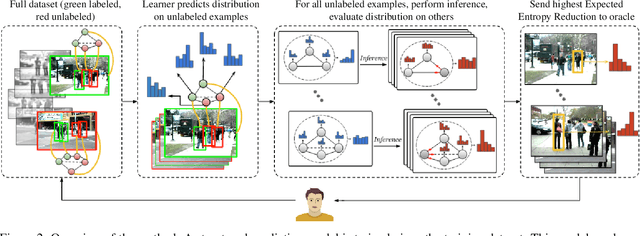
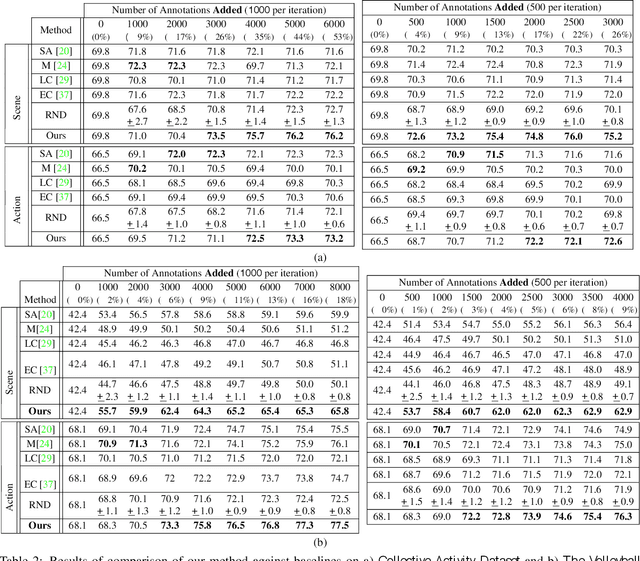
We propose a general purpose active learning algorithm for structured prediction, gathering labeled data for training a model that outputs a set of related labels for an image or video. Active learning starts with a limited initial training set, then iterates querying a user for labels on unlabeled data and retraining the model. We propose a novel algorithm for selecting data for labeling, choosing examples to maximize expected information gain based on belief propagation inference. This is a general purpose method and can be applied to a variety of tasks or models. As a specific example we demonstrate this framework for learning to recognize human actions and group activities in video sequences. Experiments show that our proposed algorithm outperforms previous active learning methods and can achieve accuracy comparable to fully supervised methods while utilizing significantly less labeled data.
Discovering Human Interactions in Videos with Limited Data Labeling
Feb 12, 2015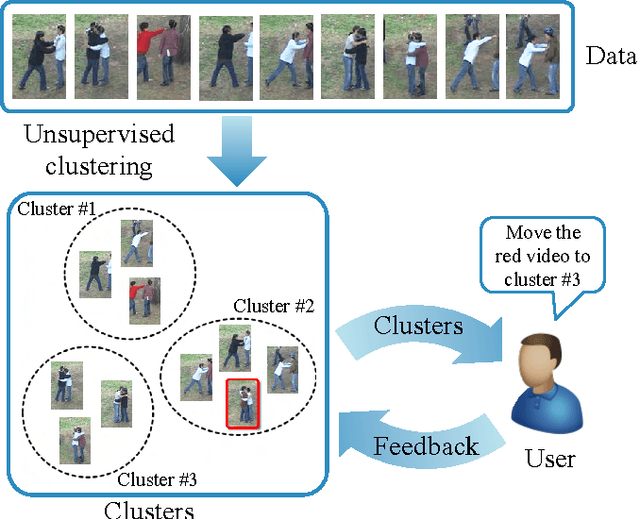
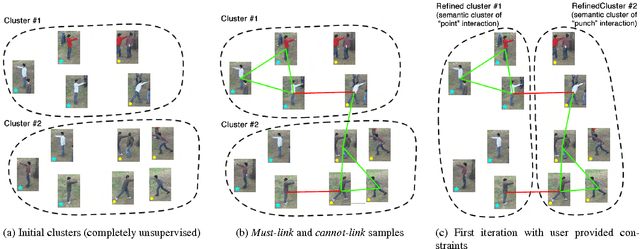
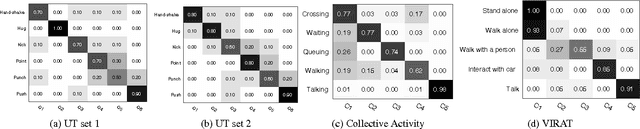
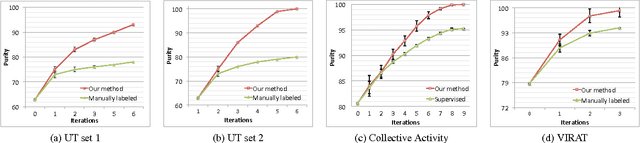
We present a novel approach for discovering human interactions in videos. Activity understanding techniques usually require a large number of labeled examples, which are not available in many practical cases. Here, we focus on recovering semantically meaningful clusters of human-human and human-object interaction in an unsupervised fashion. A new iterative solution is introduced based on Maximum Margin Clustering (MMC), which also accepts user feedback to refine clusters. This is achieved by formulating the whole process as a unified constrained latent max-margin clustering problem. Extensive experiments have been carried out over three challenging datasets, Collective Activity, VIRAT, and UT-interaction. Empirical results demonstrate that the proposed algorithm can efficiently discover perfect semantic clusters of human interactions with only a small amount of labeling effort.