 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Semantic Image Segmentation with Self-correcting Networks
Nov 17, 2018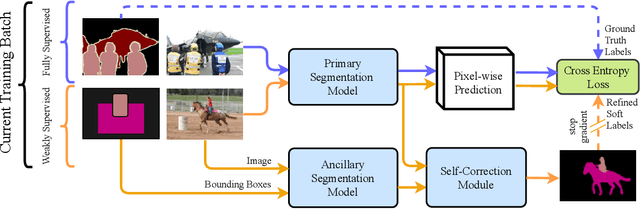
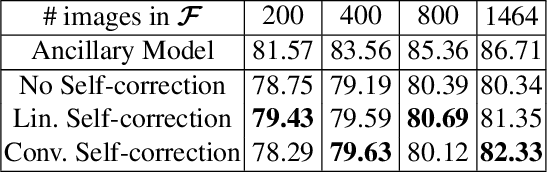
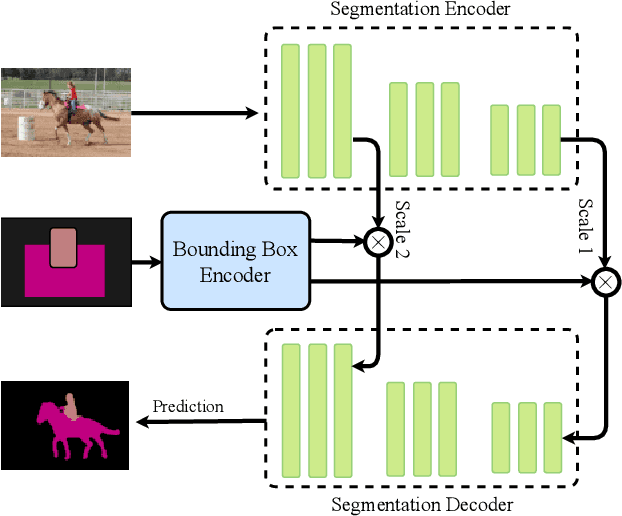
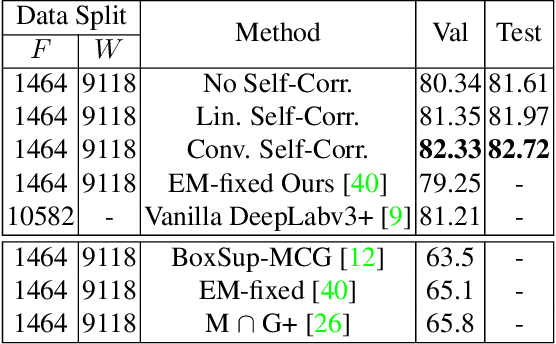
Building a large image dataset with high-quality object masks for semantic segmentation is costly and time consuming. In this paper, we reduce the data preparation cost by leveraging weak supervision in the form of object bounding boxes. To accomplish this, we propose a principled framework that trains a deep convolutional segmentation model that combines a large set of weakly supervised images (having only object bounding box labels) with a small set of fully supervised images (having semantic segmentation labels and box labels). Our framework trains the primary segmentation model with the aid of an ancillary model that generates initial segmentation labels for the weakly supervised instances and a self-correction module that improves the generated labels during training using the increasingly accurate primary model. We introduce two variants of the self-correction module using either linear or convolutional functions. Experiments on the PASCAL VOC 2012 and Cityscape datasets show that our models trained with a small fully supervised set perform similar to, or better than, models trained with a large fully supervised set while requiring ~7x less annotation effort.
Active Learning for Structured Prediction from Partially Labeled Data
Jun 09, 2017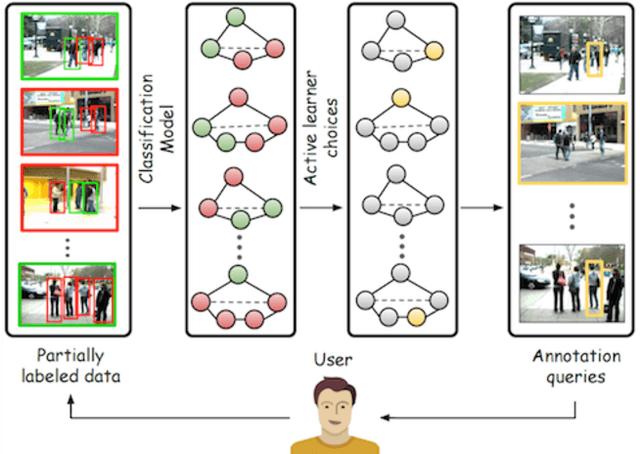
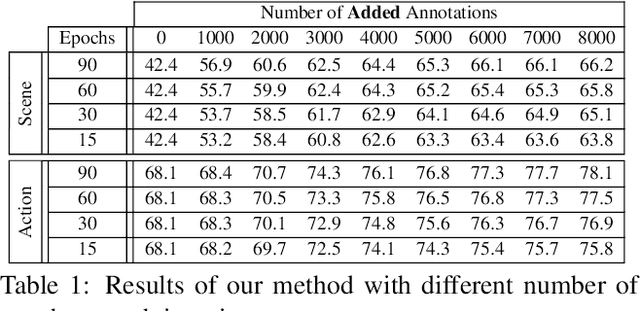
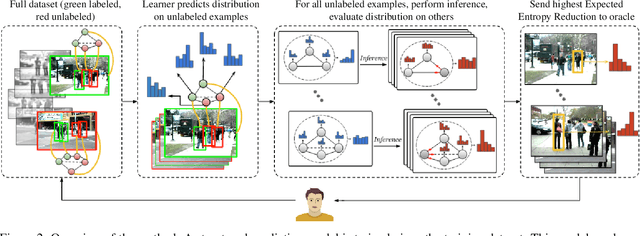
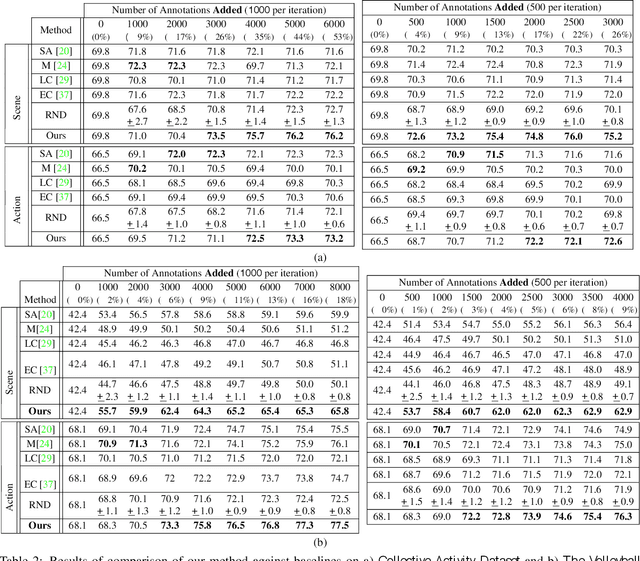
We propose a general purpose active learning algorithm for structured prediction, gathering labeled data for training a model that outputs a set of related labels for an image or video. Active learning starts with a limited initial training set, then iterates querying a user for labels on unlabeled data and retraining the model. We propose a novel algorithm for selecting data for labeling, choosing examples to maximize expected information gain based on belief propagation inference. This is a general purpose method and can be applied to a variety of tasks or models. As a specific example we demonstrate this framework for learning to recognize human actions and group activities in video sequences. Experiments show that our proposed algorithm outperforms previous active learning methods and can achieve accuracy comparable to fully supervised methods while utilizing significantly less labeled data.
Generic Tubelet Proposals for Action Localization
May 30, 2017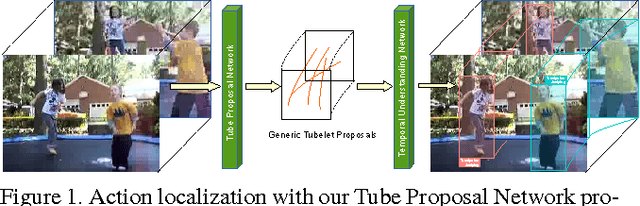

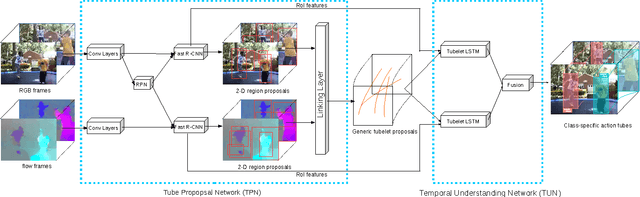
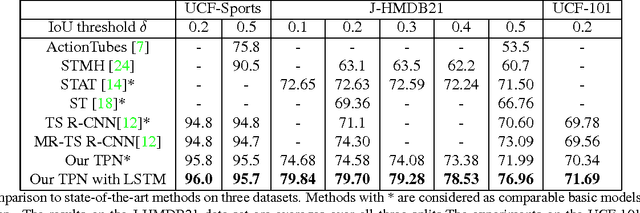
We develop a novel framework for action localization in videos. We propose the Tube Proposal Network (TPN), which can generate generic, class-independent, video-level tubelet proposals in videos. The generated tubelet proposals can be utilized in various video analysis tasks, including recognizing and localizing actions in videos. In particular, we integrate these generic tubelet proposals into a unified temporal deep network for action classification. Compared with other methods, our generic tubelet proposal method is accurate, general, and is fully differentiable under a smoothL1 loss function. We demonstrate the performance of our algorithm on the standard UCF-Sports, J-HMDB21, and UCF-101 datasets. Our class-independent TPN outperforms other tubelet generation methods, and our unified temporal deep network achieves state-of-the-art localization results on all three datasets.
Hierarchical Deep Temporal Models for Group Activity Recognition
Jul 09, 2016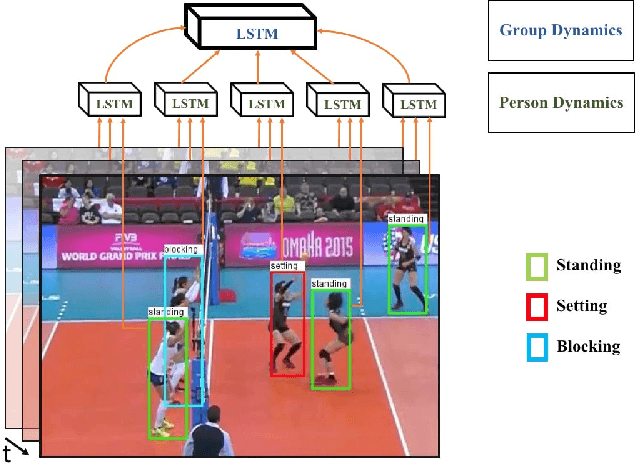

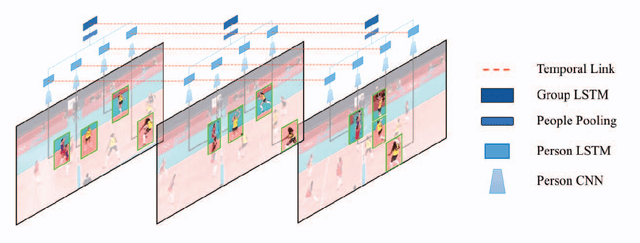
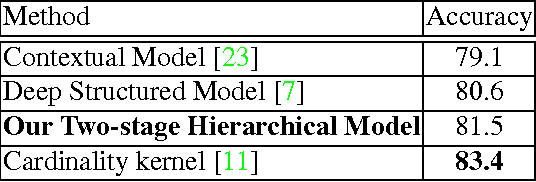
In this paper we present an approach for classifying the activity performed by a group of people in a video sequence. This problem of group activity recognition can be addressed by examining individual person actions and their relations. Temporal dynamics exist both at the level of individual person actions as well as at the level of group activity. Given a video sequence as input, methods can be developed to capture these dynamics at both person-level and group-level detail. We build a deep model to capture these dynamics based on LSTM (long short-term memory) models. In order to model both person-level and group-level dynamics, we present a 2-stage deep temporal model for the group activity recognition problem. In our approach, one LSTM model is designed to represent action dynamics of individual people in a video sequence and another LSTM model is designed to aggregate person-level information for group activity recognition. We collected a new dataset consisting of volleyball videos labeled with individual and group activities in order to evaluate our method. Experimental results on this new Volleyball Dataset and the standard benchmark Collective Activity Dataset demonstrate the efficacy of the proposed models.