 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Semantic Image Segmentation with Self-correcting Networks
Paper and Code
Nov 17, 2018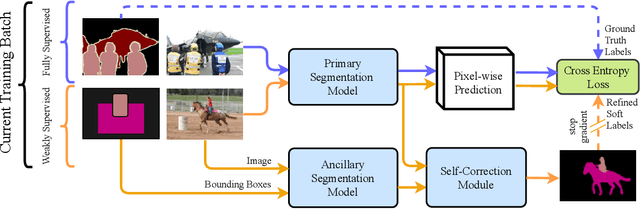
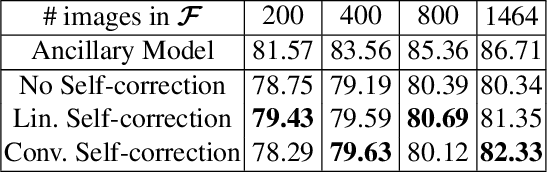
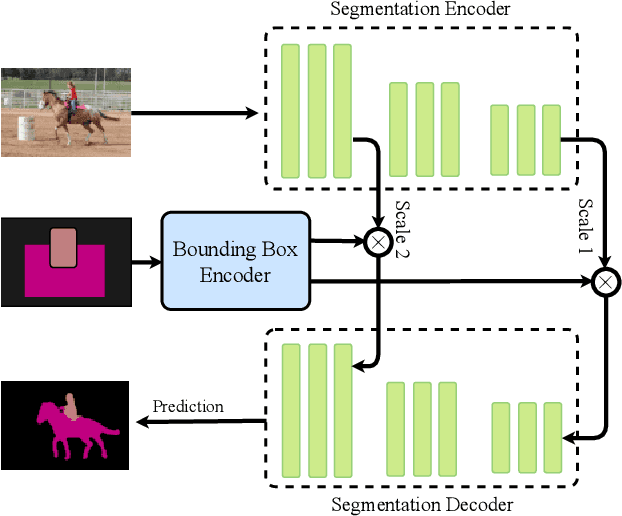
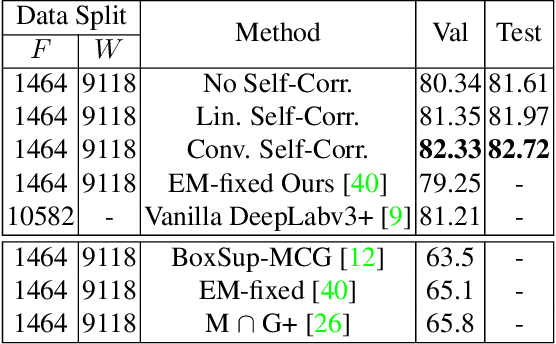
Building a large image dataset with high-quality object masks for semantic segmentation is costly and time consuming. In this paper, we reduce the data preparation cost by leveraging weak supervision in the form of object bounding boxes. To accomplish this, we propose a principled framework that trains a deep convolutional segmentation model that combines a large set of weakly supervised images (having only object bounding box labels) with a small set of fully supervised images (having semantic segmentation labels and box labels). Our framework trains the primary segmentation model with the aid of an ancillary model that generates initial segmentation labels for the weakly supervised instances and a self-correction module that improves the generated labels during training using the increasingly accurate primary model. We introduce two variants of the self-correction module using either linear or convolutional functions. Experiments on the PASCAL VOC 2012 and Cityscape datasets show that our models trained with a small fully supervised set perform similar to, or better than, models trained with a large fully supervised set while requiring ~7x less annotation effort.