 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIY Human Action Data Set Generation
Paper and Code
Mar 29, 2018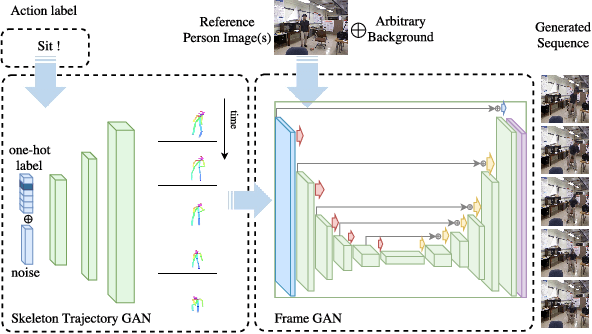
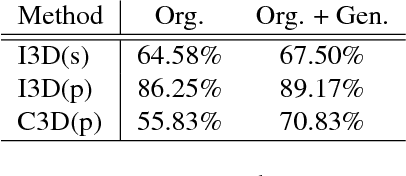
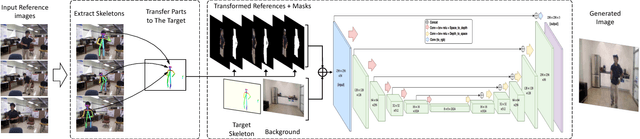
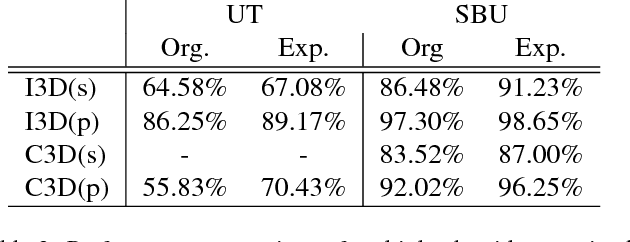
The recent successes in applying deep learning techniques to solve standard computer vision problems has aspired researchers to propose new computer vision problems in different domains. As previously established in the field, training data itself plays a significant role in the machine learning process, especially deep learning approaches which are data hungry. In order to solve each new problem and get a decent performance, a large amount of data needs to be captured which may in many cases pose logistical difficulties. Therefore, the ability to generate de novo data or expand an existing data set, however small, in order to satisfy data requirement of current networks may be invaluable. Herein, we introduce a novel way to partition an action video clip into action, subject and context. Each part is manipulated separately and reassembled with our proposed video generation technique. Furthermore, our novel human skeleton trajectory generation along with our proposed video generation technique, enables us to generate unlimited action recognition training data. These techniques enables us to generate video action clips from an small set without costly and time-consuming data acquisition. Lastly, we prove through extensive set of experiments on two small human action recognition data sets, that this new data generation technique can improve the performance of current action recognition neural nets.