 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagePairs: Realistic Super Resolution Dataset via Beam Splitter Camera Rig
Paper and Code
Apr 18, 2020
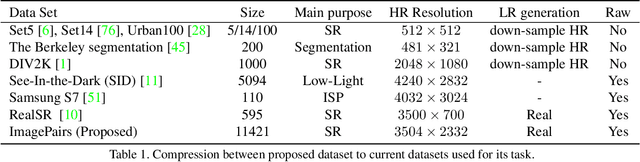
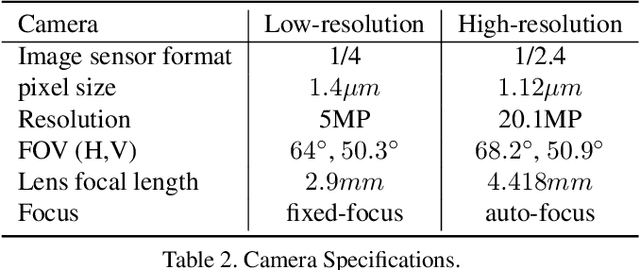
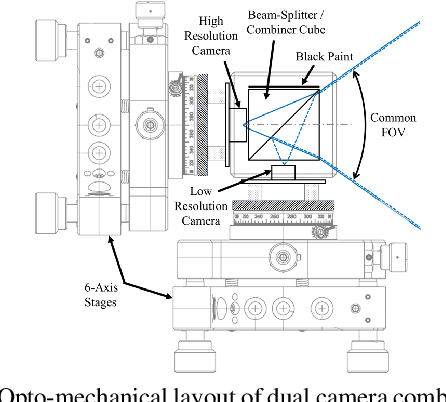
Super Resolution is the problem of recovering a high-resolution image from a single or multiple low-resolution images of the same scene. It is an ill-posed problem since high frequency visual details of the scene are completely lost in low-resolution images. To overcome this, many machine learning approaches have been proposed aiming at training a model to recover the lost details in the new scenes. Such approaches include the recent successful effort in utilizing deep learning techniques to solve super resolution problem. As proven, data itself plays a significant role in the machine learning process especially deep learning approaches which are data hungry. Therefore, to solve the problem, the process of gathering data and its formation could be equally as vital as the machine learning technique used. Herein, we are proposing a new data acquisition technique for gathering real image data set which could be used as an input for super resolution, noise cancellation and quality enhancement techniques. We use a beam-splitter to capture the same scene by a low resolution camera and a high resolution camera. Since we also release the raw images, this large-scale dataset could be used for other tasks such as ISP generation. Unlike current small-scale dataset used for these tasks, our proposed dataset includes 11,421 pairs of low-resolution high-resolution images of diverse scenes. To our knowledge this is the most complete dataset for super resolution, ISP and image quality enhancement. The benchmarking result shows how the new dataset can be successfully used to significantly improve the quality of real-world image super resolution.