 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Categorization of Crisis Events in Social Media
Apr 10, 2020
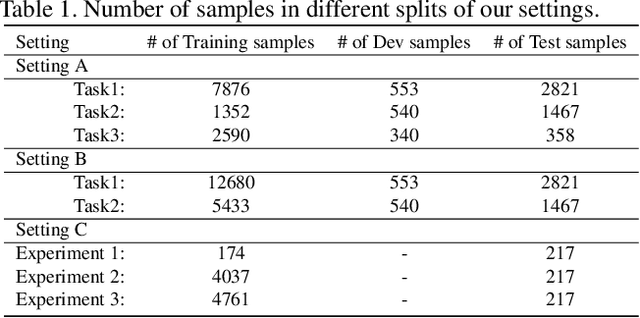
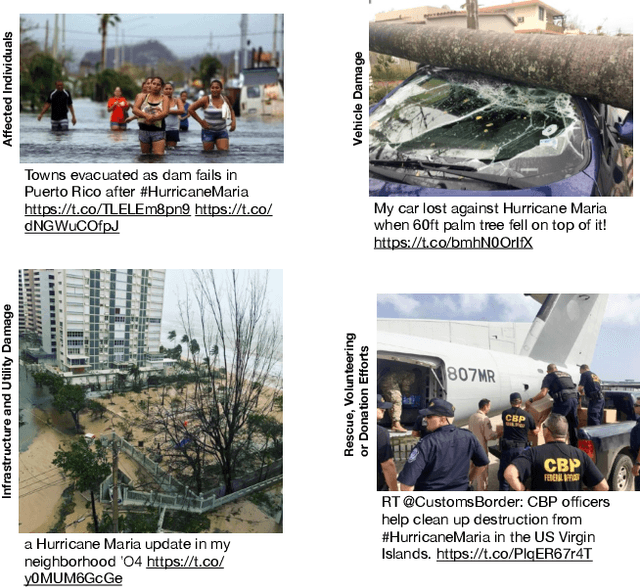
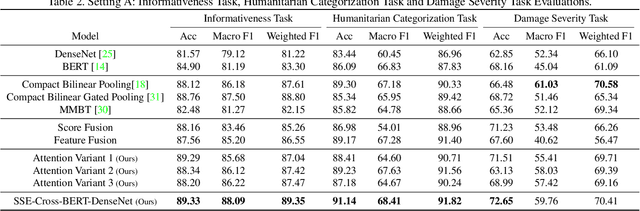
Recent developments in image classification and natural language processing, coupled with the rapid growth in social media usage, have enabled fundamental advances in detecting breaking events around the world in real-time. Emergency response is one such area that stands to gain from these advances. By processing billions of texts and images a minute, events can be automatically detected to enable emergency response workers to better assess rapidly evolving situations and deploy resources accordingly. To date, most event detection techniques in this area have focused on image-only or text-only approaches, limiting detection performance and impacting the quality of information delivered to crisis response teams. In this paper, we present a new multimodal fusion method that leverages both images and texts as input. In particular, we introduce a cross-attention module that can filter uninformative and misleading components from weak modalities on a sample by sample basis. In addition, we employ a multimodal graph-based approach to stochastically transition between embeddings of different multimodal pairs during training to better regularize the learning process as well as dealing with limited training data by constructing new matched pairs from different samples. We show that our method outperforms the unimodal approaches and strong multimodal baselines by a large margin on three crisis-related tasks.
* Conference on Computer Vision and Pattern Recognition (CVPR 2020)
Deep Sparse Representation-based Classification
Apr 24, 2019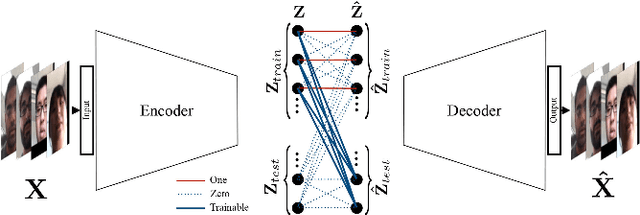

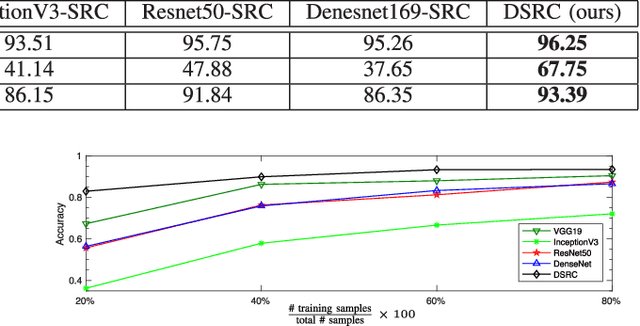
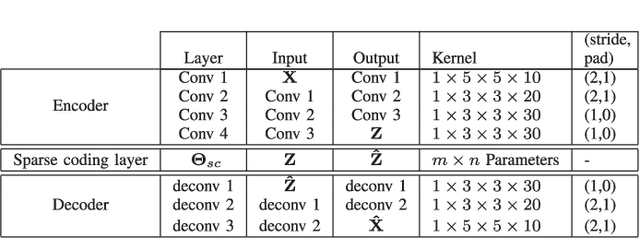
We present a transductive deep learning-based formulation for the sparse representation-based classification (SRC) method. The proposed network consists of a convolutional autoencoder along with a fully-connected layer. The role of the autoencoder network is to learn robust deep features for classification. On the other hand, the fully-connected layer, which is placed in between the encoder and the decoder networks, is responsible for finding the sparse representation. The estimated sparse codes are then used for classification. Various experiments on three different datasets show that the proposed network leads to sparse representations that give better classification results than state-of-the-art SRC methods. The source code is available at: github.com/mahdiabavisani/DSRC.
Improving the Performance of Unimodal Dynamic Hand-Gesture Recognition with Multimodal Training
Dec 14, 2018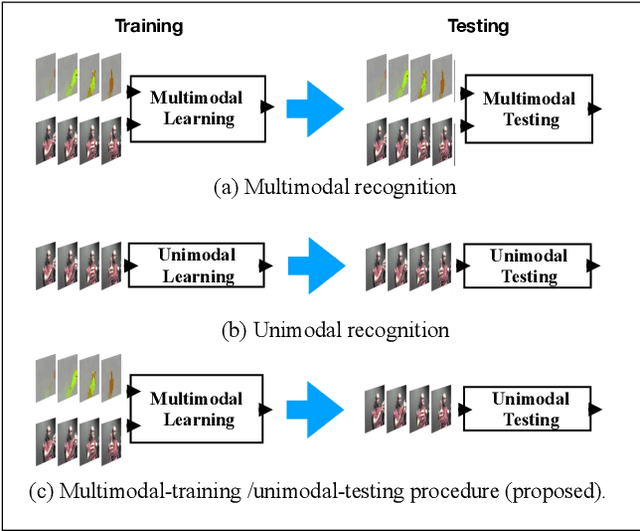
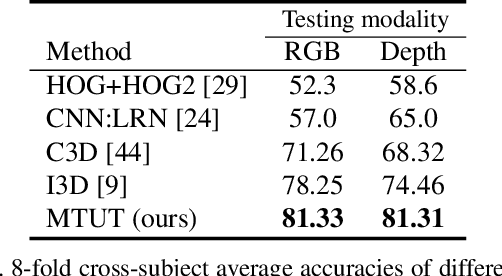


We present an efficient approach for leveraging the knowledge from multiple modalities in training unimodal 3D convolutional neural networks (3D-CNNs) for the task of dynamic hand gesture recognition. Instead of explicitly combining multimodal information, which is commonplace in many state-of-the-art methods, we propose a different framework in which we embed the knowledge of multiple modalities in individual networks so that each unimodal network can achieve an improved performance. In particular, we dedicate separate networks per available modality and enforce them to collaborate and learn to develop networks with common semantics and better representations. We introduce a "spatiotemporal semantic alignment" loss (SSA) to align the content of the features from different networks. In addition, we regularize this loss with our proposed "focal regularization parameter" to avoid negative knowledge transfer. Experimental results show that our framework improves the test time recognition accuracy of unimodal networks, and provides the state-of-the-art performance on various dynamic hand gesture recognition datasets.
Deep Multimodal Subspace Clustering Networks
Sep 19, 2018
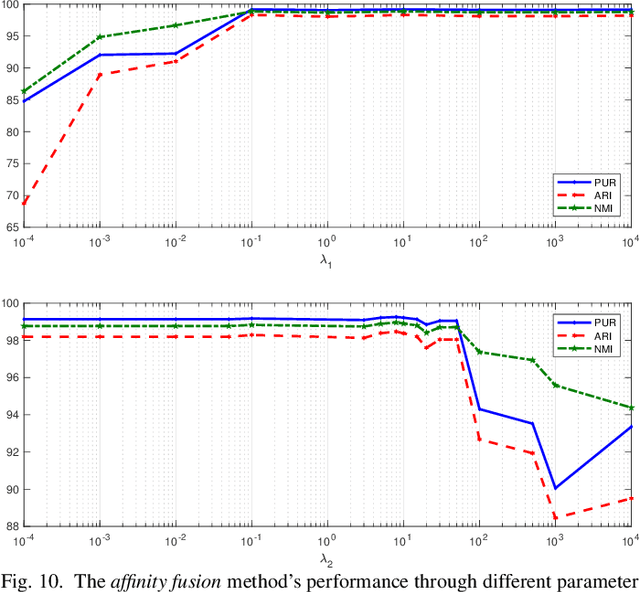

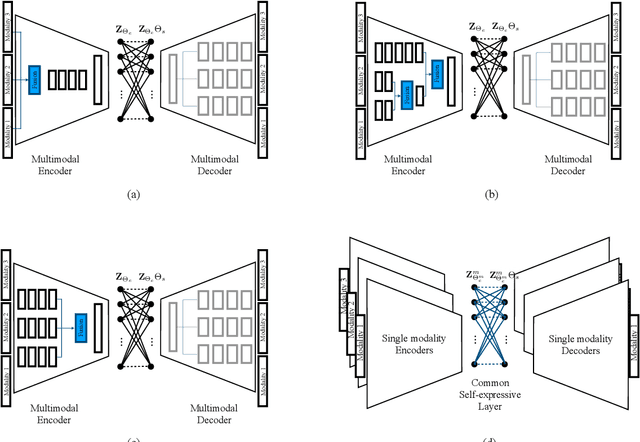
We present convolutional neural network (CNN) based approaches for unsupervised multimodal subspace clustering. The proposed framework consists of three main stages - multimodal encoder, self-expressive layer, and multimodal decoder. The encoder takes multimodal data as input and fuses them to a latent space representation. The self-expressive layer is responsible for enforcing the self-expressiveness property and acquiring an affinity matrix corresponding to the datapoints. The decoder reconstructs the original input data. The network uses the distance between the decoder's reconstruction and the original input in its training. We investigate early, late and intermediate fusion techniques and propose three different encoders corresponding to them for spatial fusion. The self-expressive layers and multimodal decoders are essentially the same for different spatial fusion-based approaches. In addition to various spatial fusion-based methods, an affinity fusion-based network is also proposed in which the self-expressive layer corresponding to different modalities is enforced to be the same. Extensive experiments on three datasets show that the proposed methods significantly outperform the state-of-the-art multimodal subspace clustering methods.
In2I : Unsupervised Multi-Image-to-Image Translation Using Generative Adversarial Networks
Nov 26, 2017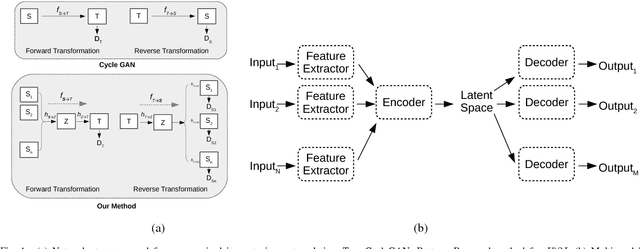



In unsupervised image-to-image translation, the goal is to learn the mapping between an input image and an output image using a set of unpaired training images. In this paper, we propose an extension of the unsupervised image-to-image translation problem to multiple input setting. Given a set of paired images from multiple modalities, a transformation is learned to translate the input into a specified domain. For this purpose, we introduce a Generative Adversarial Network (GAN) based framework along with a multi-modal generator structure and a new loss term, latent consistency loss. Through various experiments we show that leveraging multiple inputs generally improves the visual quality of the translated images. Moreover, we show that the proposed method outperforms current state-of-the-art unsupervised image-to-image translation methods.