 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoToM: Benchmarking Theory of Mind Reasoning from Egocentric Videos
Mar 28, 2025

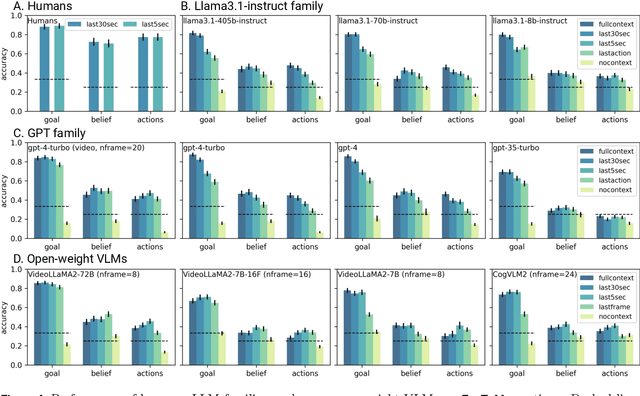

We introduce EgoToM, a new video question-answering benchmark that extends Theory-of-Mind (ToM) evaluation to egocentric domains. Using a causal ToM model, we generate multi-choice video QA instances for the Ego4D dataset to benchmark the ability to predict a camera wearer's goals, beliefs, and next actions. We study the performance of both humans and state of the art multimodal large language models (MLLMs) on these three interconnected inference problems. Our evaluation shows that MLLMs achieve close to human-level accuracy on inferring goals from egocentric videos. However, MLLMs (including the largest ones we tested with over 100B parameters) fall short of human performance when inferring the camera wearers' in-the-moment belief states and future actions that are most consistent with the unseen video future. We believe that our results will shape the future design of an important class of egocentric digital assistants which are equipped with a reasonable model of the user's internal mental states.
Online Unsupervised Learning of Visual Representations and Categories
Sep 13, 2021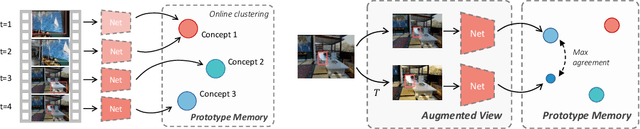
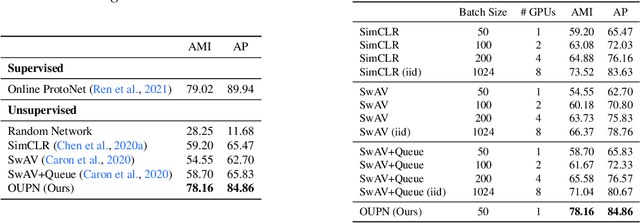


Real world learning scenarios involve a nonstationary distribution of classes with sequential dependencies among the samples, in contrast to the standard machine learning formulation of drawing samples independently from a fixed, typically uniform distribution. Furthermore, real world interactions demand learning on-the-fly from few or no class labels. In this work, we propose an unsupervised model that simultaneously performs online visual representation learning and few-shot learning of new categories without relying on any class labels. Our model is a prototype-based memory network with a control component that determines when to form a new class prototype. We formulate it as an online Gaussian mixture model, where components are created online with only a single new example, and assignments do not have to be balanced, which permits an approximation to natural imbalanced distributions from uncurated raw data. Learning includes a contrastive loss that encourages different views of the same image to be assigned to the same prototype. The result is a mechanism that forms categorical representations of objects in nonstationary environments. Experiments show that our method can learn from an online stream of visual input data and is significantly better at category recognition compared to state-of-the-art self-supervised learning methods.
Training cascaded networks for speeded decisions using a temporal-difference loss
Feb 19, 2021
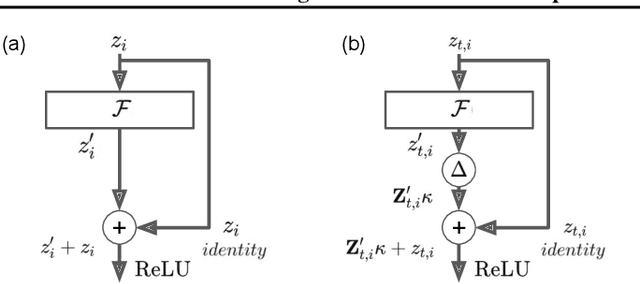

Although deep feedforward neural networks share some characteristics with the primate visual system, a key distinction is their dynamics. Deep nets typically operate in sequential stages wherein each layer fully completes its computation before processing begins in subsequent layers. In contrast, biological systems have cascaded dynamics: information propagates from neurons at all layers in parallel but transmission is gradual over time. In our work, we construct a cascaded ResNet by introducing a propagation delay into each residual block and updating all layers in parallel in a stateful manner. Because information transmitted through skip connections avoids delays, the functional depth of the architecture increases over time and yields a trade off between processing speed and accuracy. We introduce a temporal-difference (TD) training loss that achieves a strictly superior speed accuracy profile over standard losses. The CascadedTD model has intriguing properties, including: typical instances are classified more rapidly than atypical instances; CascadedTD is more robust to both persistent and transient noise than is a conventional ResNet; and the time-varying output trace of CascadedTD provides a signal that can be used by `meta-cognitive' models for OOD detection and to determine when to terminate processing.
Wandering Within a World: Online Contextualized Few-Shot Learning
Jul 09, 2020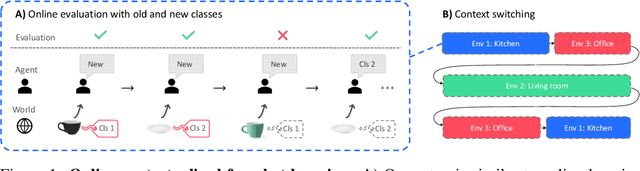


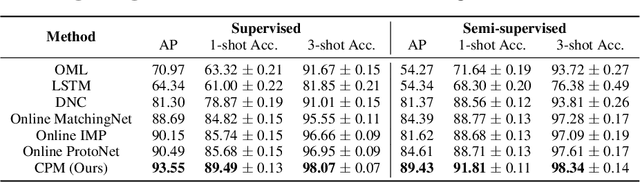
We aim to bridge the gap between typical human and machine-learning environments by extending the standard framework of few-shot learning to an online, continual setting. In this setting, episodes do not have separate training and testing phases, and instead models are evaluated online while learning novel classes. As in real world, where the presence of spatiotemporal context helps us retrieve learned skills in the past, our online few-shot learning setting also features an underlying context that changes throughout time. Object classes are correlated within a context and inferring the correct context can lead to better performance. Building upon this setting, we propose a new few-shot learning dataset based on large scale indoor imagery that mimics the visual experience of an agent wandering within a world. Furthermore, we convert popular few-shot learning approaches into online versions and we also propose a new model named contextual prototypical memory that can make use of spatiotemporal contextual information from the recent past.
In Automation We Trust: Investigating the Role of Uncertainty in Active Learning Systems
Apr 02, 2020


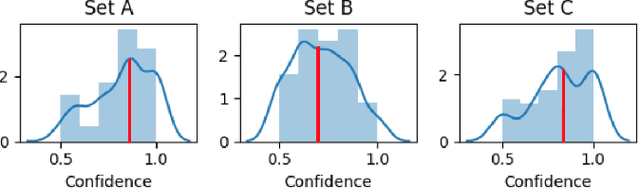
We investigate how different active learning (AL) query policies coupled with classification uncertainty visualizations affect analyst trust in automated classification systems. A current standard policy for AL is to query the oracle (e.g., the analyst) to refine labels for datapoints where the classifier has the highest uncertainty. This is an optimal policy for the automation system as it yields maximal information gain. However, model-centric policies neglect the effects of this uncertainty on the human component of the system and the consequent manner in which the human will interact with the system post-training. In this paper, we present an empirical study evaluating how AL query policies and visualizations lending transparency to classification influence trust in automated classification of image data. We found that query policy significantly influences an analyst's trust in an image classification system, and we use these results to propose a set of oracle query policies and visualizations for use during AL training phases that can influence analyst trust in classification.
MMTM: Multimodal Transfer Module for CNN Fusion
Nov 20, 2019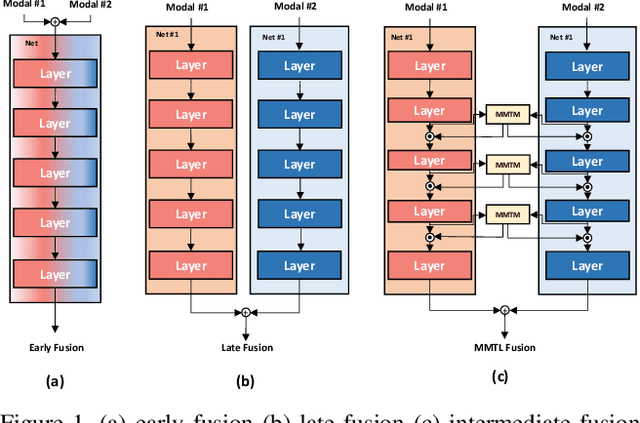

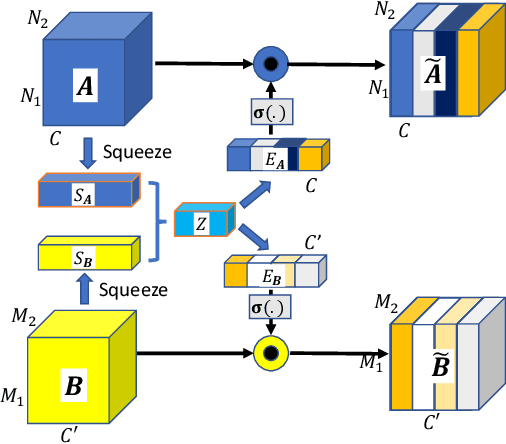
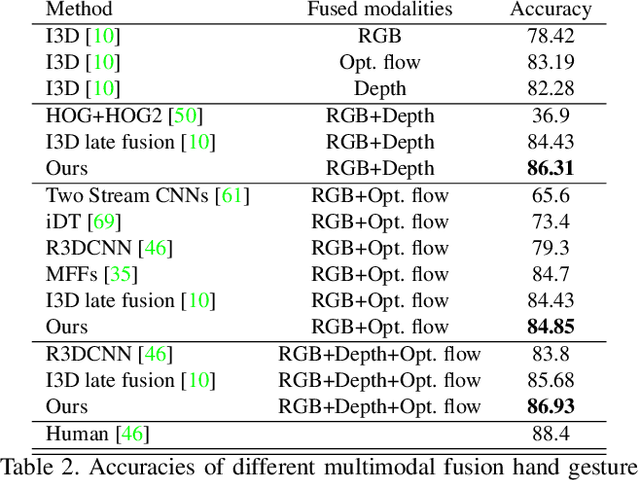
In late fusion, each modality is processed in a separate unimodal Convolutional Neural Network (CNN) stream and the scores of each modality are fused at the end. Due to its simplicity late fusion is still the predominant approach in many state-of-the-art multimodal applications. In this paper, we present a simple neural network module for leveraging the knowledge from multiple modalities in convolutional neural networks. The propose unit, named Multimodal Transfer Module (MMTM), can be added at different levels of the feature hierarchy, enabling slow modality fusion. Using squeeze and excitation operations, MMTM utilizes the knowledge of multiple modalities to recalibrate the channel-wise features in each CNN stream. Despite other intermediate fusion methods, the proposed module could be used for feature modality fusion in convolution layers with different spatial dimensions. Another advantage of the proposed method is that it could be added among unimodal branches with minimum changes in the their network architectures, allowing each branch to be initialized with existing pretrained weights. Experimental results show that our framework improves the recognition accuracy of well-known multimodal networks. We demonstrate state-of-the-art or competitive performance on four datasets that span the task domains of dynamic hand gesture recognition, speech enhancement, and action recognition with RGB and body joints.
Virtual-to-Real-World Transfer Learning for Robots on Wilderness Trails
Jan 17, 2019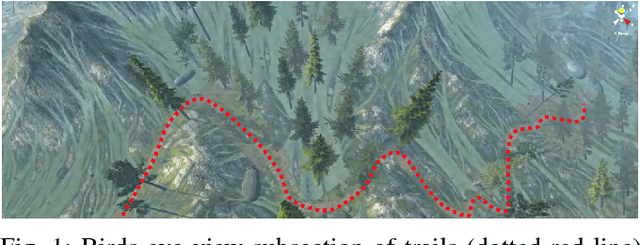
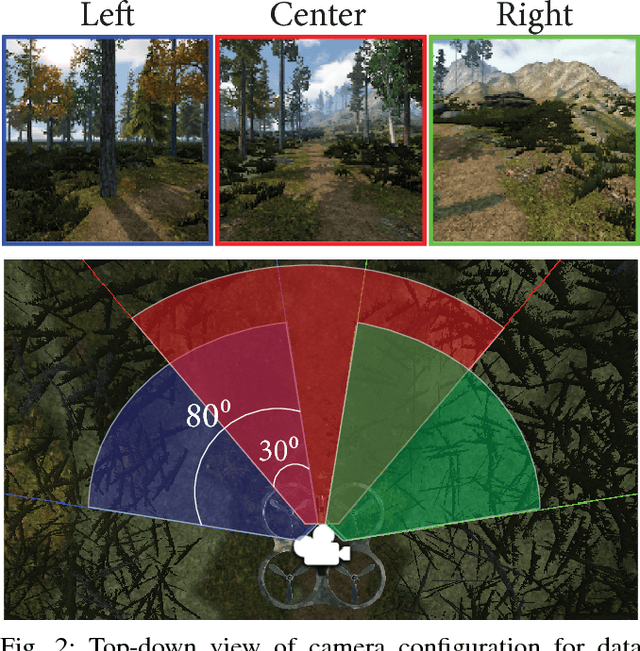
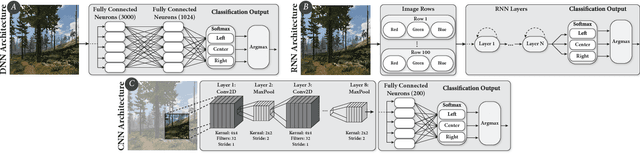
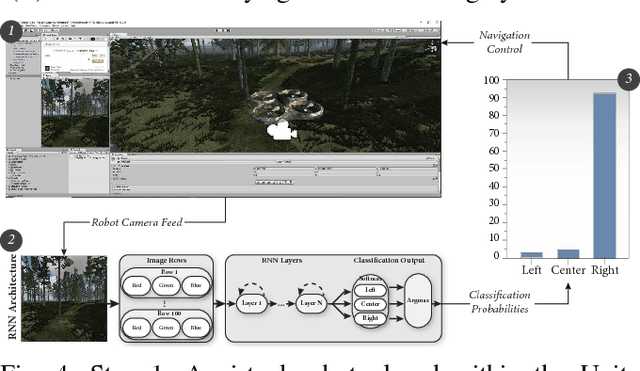
Robots hold promise in many scenarios involving outdoor use, such as search-and-rescue, wildlife management, and collecting data to improve environment, climate, and weather forecasting. However, autonomous navigation of outdoor trails remains a challenging problem. Recent work has sought to address this issue using deep learning. Although this approach has achieved state-of-the-art results, the deep learning paradigm may be limited due to a reliance on large amounts of annotated training data. Collecting and curating training datasets may not be feasible or practical in many situations, especially as trail conditions may change due to seasonal weather variations, storms, and natural erosion. In this paper, we explore an approach to address this issue through virtual-to-real-world transfer learning using a variety of deep learning models trained to classify the direction of a trail in an image. Our approach utilizes synthetic data gathered from virtual environments for model training, bypassing the need to collect a large amount of real images of the outdoors. We validate our approach in three main ways. First, we demonstrate that our models achieve classification accuracies upwards of 95% on our synthetic data set. Next, we utilize our classification models in the control system of a simulated robot to demonstrate feasibility. Finally, we evaluate our models on real-world trail data and demonstrate the potential of virtual-to-real-world transfer learning.
* iROS 2018