 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigiData: Training and Evaluating General-Purpose Mobile Control Agents
Nov 11, 2025AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.
Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
Oct 25, 2025There has been a surge of interest in assistive wearable agents: agents embodied in wearable form factors (e.g., smart glasses) who take assistive actions toward a user's goal/query (e.g. "Where did I leave my keys?"). In this work, we consider the important complementary problem of inferring that goal from multi-modal contextual observations. Solving this "goal inference" problem holds the promise of eliminating the effort needed to interact with such an agent. This work focuses on creating WAGIBench, a strong benchmark to measure progress in solving this problem using vision-language models (VLMs). Given the limited prior work in this area, we collected a novel dataset comprising 29 hours of multimodal data from 348 participants across 3,477 recordings, featuring ground-truth goals alongside accompanying visual, audio, digital, and longitudinal contextual observations. We validate that human performance exceeds model performance, achieving 93% multiple-choice accuracy compared with 84% for the best-performing VLM. Generative benchmark results that evaluate several families of modern vision-language models show that larger models perform significantly better on the task, yet remain far from practical usefulness, as they produce relevant goals only 55% of the time. Through a modality ablation, we show that models benefit from extra information in relevant modalities with minimal performance degradation from irrelevant modalities.
EgoToM: Benchmarking Theory of Mind Reasoning from Egocentric Videos
Mar 28, 2025

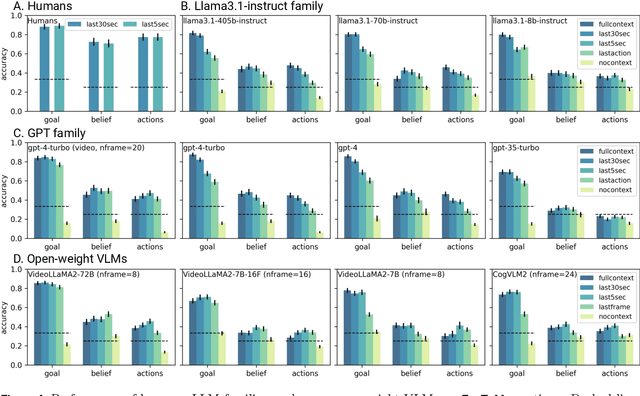

We introduce EgoToM, a new video question-answering benchmark that extends Theory-of-Mind (ToM) evaluation to egocentric domains. Using a causal ToM model, we generate multi-choice video QA instances for the Ego4D dataset to benchmark the ability to predict a camera wearer's goals, beliefs, and next actions. We study the performance of both humans and state of the art multimodal large language models (MLLMs) on these three interconnected inference problems. Our evaluation shows that MLLMs achieve close to human-level accuracy on inferring goals from egocentric videos. However, MLLMs (including the largest ones we tested with over 100B parameters) fall short of human performance when inferring the camera wearers' in-the-moment belief states and future actions that are most consistent with the unseen video future. We believe that our results will shape the future design of an important class of egocentric digital assistants which are equipped with a reasonable model of the user's internal mental states.
Multiscale Video Pretraining for Long-Term Activity Forecasting
Jul 24, 2023Long-term activity forecasting is an especially challenging research problem because it requires understanding the temporal relationships between observed actions, as well as the variability and complexity of human activities. Despite relying on strong supervision via expensive human annotations, state-of-the-art forecasting approaches often generalize poorly to unseen data. To alleviate this issue, we propose Multiscale Video Pretraining (MVP), a novel self-supervised pretraining approach that learns robust representations for forecasting by learning to predict contextualized representations of future video clips over multiple timescales. MVP is based on our observation that actions in videos have a multiscale nature, where atomic actions typically occur at a short timescale and more complex actions may span longer timescales. We compare MVP to state-of-the-art self-supervised video learning approaches on downstream long-term forecasting tasks including long-term action anticipation and video summary prediction. Our comprehensive experiments across the Ego4D and Epic-Kitchens-55/100 datasets demonstrate that MVP out-performs state-of-the-art methods by significant margins. Notably, MVP obtains a relative performance gain of over 20% accuracy in video summary forecasting over existing methods.
EgoAdapt: A multi-stream evaluation study of adaptation to real-world egocentric user video
Jul 11, 2023



In egocentric action recognition a single population model is typically trained and subsequently embodied on a head-mounted device, such as an augmented reality headset. While this model remains static for new users and environments, we introduce an adaptive paradigm of two phases, where after pretraining a population model, the model adapts on-device and online to the user's experience. This setting is highly challenging due to the change from population to user domain and the distribution shifts in the user's data stream. Coping with the latter in-stream distribution shifts is the focus of continual learning, where progress has been rooted in controlled benchmarks but challenges faced in real-world applications often remain unaddressed. We introduce EgoAdapt, a benchmark for real-world egocentric action recognition that facilitates our two-phased adaptive paradigm, and real-world challenges naturally occur in the egocentric video streams from Ego4d, such as long-tailed action distributions and large-scale classification over 2740 actions. We introduce an evaluation framework that directly exploits the user's data stream with new metrics to measure the adaptation gain over the population model, online generalization, and hindsight performance. In contrast to single-stream evaluation in existing works, our framework proposes a meta-evaluation that aggregates the results from 50 independent user streams. We provide an extensive empirical study for finetuning and experience replay.
How You Move Your Head Tells What You Do: Self-supervised Video Representation Learning with Egocentric Cameras and IMU Sensors
Oct 04, 2021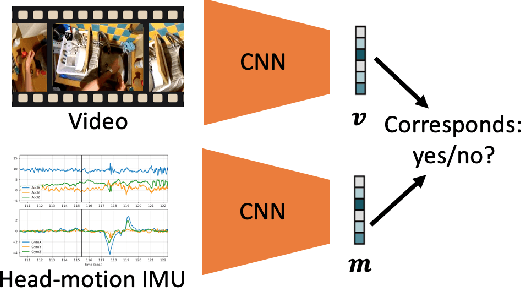
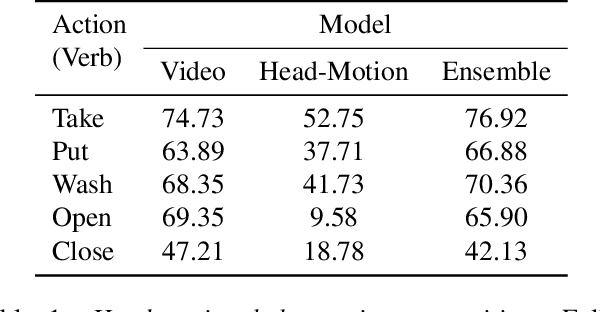
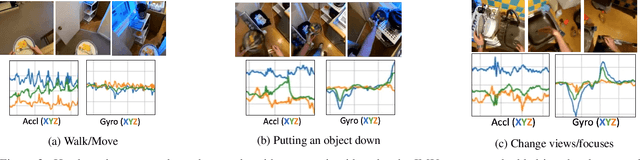
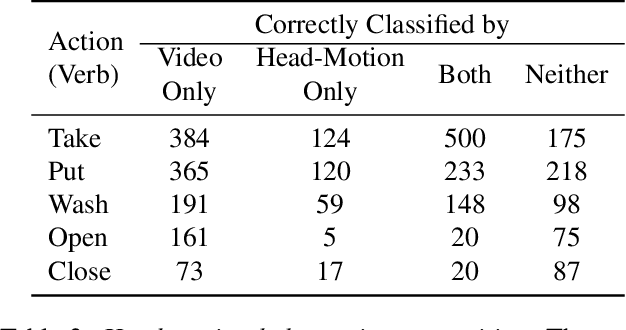
Understanding users' activities from head-mounted cameras is a fundamental task for Augmented and Virtual Reality (AR/VR) applications. A typical approach is to train a classifier in a supervised manner using data labeled by humans. This approach has limitations due to the expensive annotation cost and the closed coverage of activity labels. A potential way to address these limitations is to use self-supervised learning (SSL). Instead of relying on human annotations, SSL leverages intrinsic properties of data to learn representations. We are particularly interested in learning egocentric video representations benefiting from the head-motion generated by users' daily activities, which can be easily obtained from IMU sensors embedded in AR/VR devices. Towards this goal, we propose a simple but effective approach to learn video representation by learning to tell the corresponding pairs of video clip and head-motion. We demonstrate the effectiveness of our learned representation for recognizing egocentric activities of people and dogs.
Unifying Few- and Zero-Shot Egocentric Action Recognition
May 27, 2020
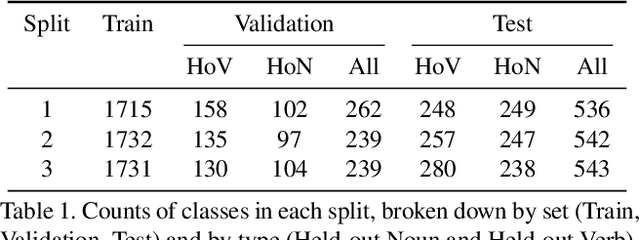
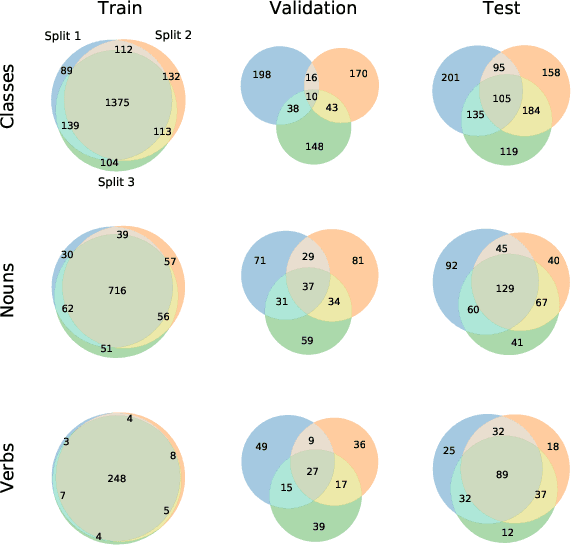
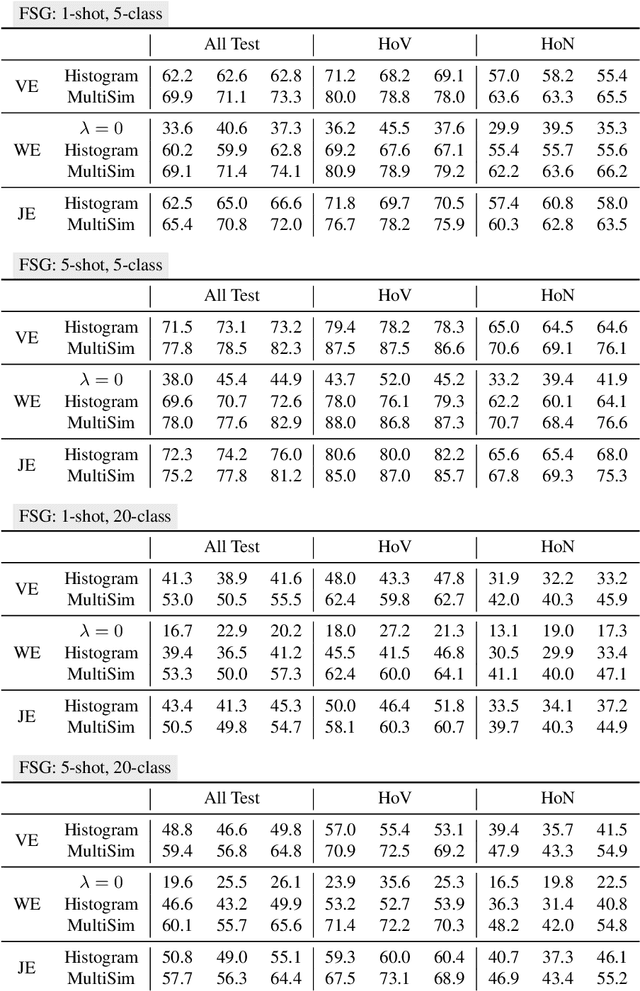
Although there has been significant research in egocentric action recognition, most methods and tasks, including EPIC-KITCHENS, suppose a fixed set of action classes. Fixed-set classification is useful for benchmarking methods, but is often unrealistic in practical settings due to the compositionality of actions, resulting in a functionally infinite-cardinality label set. In this work, we explore generalization with an open set of classes by unifying two popular approaches: few- and zero-shot generalization (the latter which we reframe as cross-modal few-shot generalization). We propose a new set of splits derived from the EPIC-KITCHENS dataset that allow evaluation of open-set classification, and use these splits to show that adding a metric-learning loss to the conventional direct-alignment baseline can improve zero-shot classification by as much as 10%, while not sacrificing few-shot performance.
Stochastic Prototype Embeddings
Sep 25, 2019
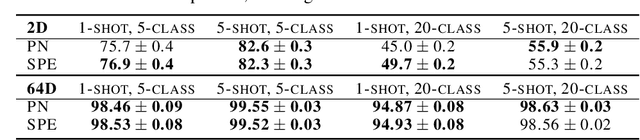
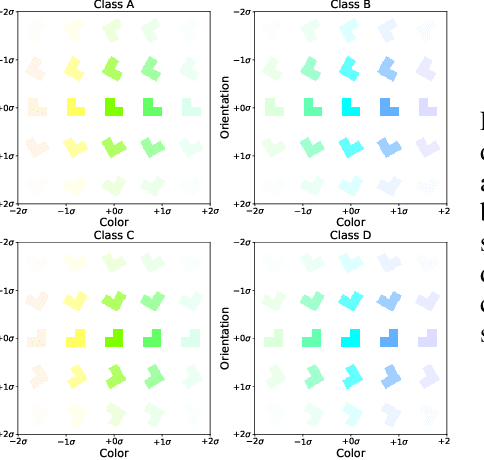
Supervised deep-embedding methods project inputs of a domain to a representational space in which same-class instances lie near one another and different-class instances lie far apart. We propose a probabilistic method that treats embeddings as random variables. Extending a state-of-the-art deterministic method, Prototypical Networks (Snell et al., 2017), our approach supposes the existence of a class prototype around which class instances are Gaussian distributed. The prototype posterior is a product distribution over labeled instances, and query instances are classified by marginalizing relative prototype proximity over embedding uncertainty. We describe an efficient sampler for approximate inference that allows us to train the model at roughly the same space and time cost as its deterministic sibling. Incorporating uncertainty improves performance on few-shot learning and gracefully handles label noise and out-of-distribution inputs. Compared to the state-of-the-art stochastic method, Hedged Instance Embeddings (Oh et al., 2019), we achieve superior large- and open-set classification accuracy. Our method also aligns class-discriminating features with the axes of the embedding space, yielding an interpretable, disentangled representation.
Adapted Deep Embeddings: A Synthesis of Methods for $k$-Shot Inductive Transfer Learning
Oct 27, 2018
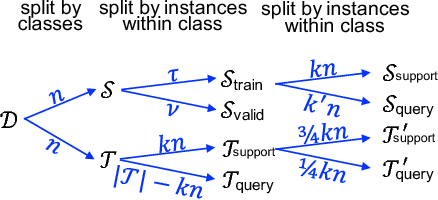

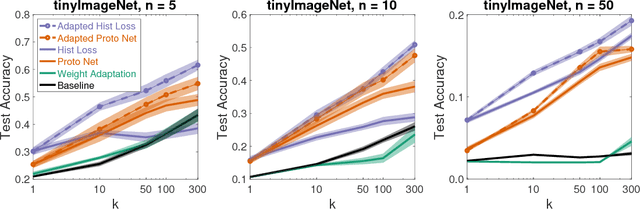
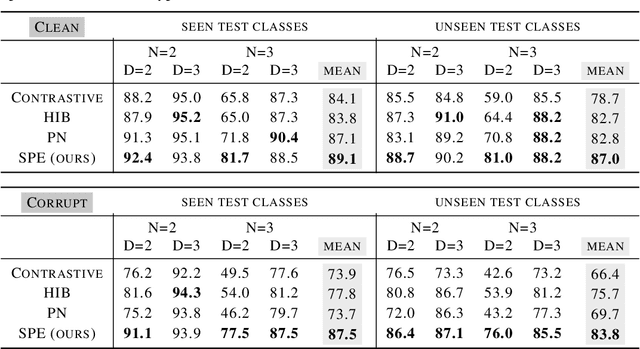
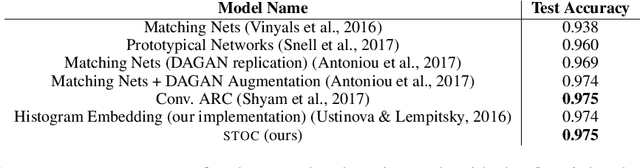
The focus in machine learning has branched beyond training classifiers on a single task to investigating how previously acquired knowledge in a source domain can be leveraged to facilitate learning in a related target domain, known as inductive transfer learning. Three active lines of research have independently explored transfer learning using neural networks. In weight transfer, a model trained on the source domain is used as an initialization point for a network to be trained on the target domain. In deep metric learning, the source domain is used to construct an embedding that captures class structure in both the source and target domains. In few-shot learning, the focus is on generalizing well in the target domain based on a limited number of labeled examples. We compare state-of-the-art methods from these three paradigms and also explore hybrid adapted-embedding methods that use limited target-domain data to fine tune embeddings constructed from source-domain data. We conduct a systematic comparison of methods in a variety of domains, varying the number of labeled instances available in the target domain ($k$), as well as the number of target-domain classes. We reach three principal conclusions: (1) Deep embeddings are far superior, compared to weight transfer, as a starting point for inter-domain transfer or model re-use (2) Our hybrid methods robustly outperform every few-shot learning and every deep metric learning method previously proposed, with a mean error reduction of 34% over state-of-the-art. (3) Among loss functions for discovering embeddings, the histogram loss (Ustinova & Lempitsky, 2016) is most robust. We hope our results will motivate a unification of research in weight transfer, deep metric learning, and few-shot learning.
Open-Ended Content-Style Recombination Via Leakage Filtering
Sep 28, 2018

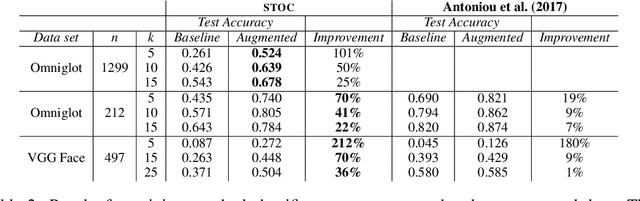
We consider visual domains in which a class label specifies the content of an image, and class-irrelevant properties that differentiate instances constitute the style. We present a domain-independent method that permits the open-ended recombination of style of one image with the content of another. Open ended simply means that the method generalizes to style and content not present in the training data. The method starts by constructing a content embedding using an existing deep metric-learning technique. This trained content encoder is incorporated into a variational autoencoder (VAE), paired with a to-be-trained style encoder. The VAE reconstruction loss alone is inadequate to ensure a decomposition of the latent representation into style and content. Our method thus includes an auxiliary loss, leakage filtering, which ensures that no style information remaining in the content representation is used for reconstruction and vice versa. We synthesize novel images by decoding the style representation obtained from one image with the content representation from another. Using this method for data-set augmentation, we obtain state-of-the-art performance on few-shot learning tasks.