 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoToM: Benchmarking Theory of Mind Reasoning from Egocentric Videos
Paper and Code


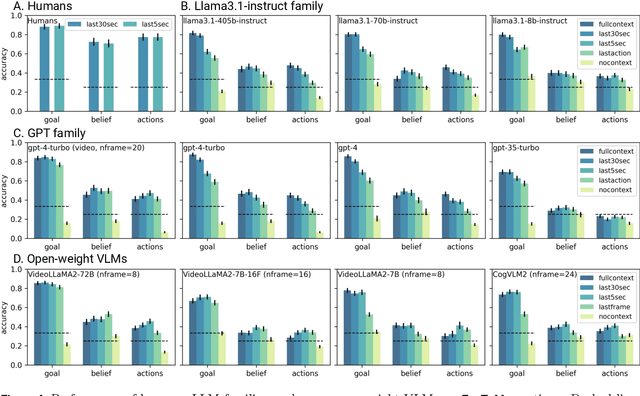

We introduce EgoToM, a new video question-answering benchmark that extends Theory-of-Mind (ToM) evaluation to egocentric domains. Using a causal ToM model, we generate multi-choice video QA instances for the Ego4D dataset to benchmark the ability to predict a camera wearer's goals, beliefs, and next actions. We study the performance of both humans and state of the art multimodal large language models (MLLMs) on these three interconnected inference problems. Our evaluation shows that MLLMs achieve close to human-level accuracy on inferring goals from egocentric videos. However, MLLMs (including the largest ones we tested with over 100B parameters) fall short of human performance when inferring the camera wearers' in-the-moment belief states and future actions that are most consistent with the unseen video future. We believe that our results will shape the future design of an important class of egocentric digital assistants which are equipped with a reasonable model of the user's internal mental states.