 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Multimodal Generative Recommendation for Fusing Semantic and Collaborative Signals
Feb 03, 2026Sequential recommender systems rank relevant items by modeling a user's interaction history and computing the inner product between the resulting user representation and stored item embeddings. To avoid the significant memory overhead of storing large item sets, the generative recommendation paradigm instead models each item as a series of discrete semantic codes. Here, the next item is predicted by an autoregressive model that generates the code sequence corresponding to the predicted item. However, despite promising ranking capabilities on small datasets, these methods have yet to surpass traditional sequential recommenders on large item sets, limiting their adoption in the very scenarios they were designed to address. To resolve this, we propose MSCGRec, a Multimodal Semantic and Collaborative Generative Recommender. MSCGRec incorporates multiple semantic modalities and introduces a novel self-supervised quantization learning approach for images based on the DINO framework. Additionally, MSCGRec fuses collaborative and semantic signals by extracting collaborative features from sequential recommenders and treating them as a separate modality. Finally, we propose constrained sequence learning that restricts the large output space during training to the set of permissible tokens. We empirically demonstrate on three large real-world datasets that MSCGRec outperforms both sequential and generative recommendation baselines and provide an extensive ablation study to validate the impact of each component.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
RePanda: Pandas-powered Tabular Verification and Reasoning
Mar 14, 2025Fact-checking tabular data is essential for ensuring the accuracy of structured information. However, existing methods often rely on black-box models with opaque reasoning. We introduce RePanda, a structured fact verification approach that translates claims into executable pandas queries, enabling interpretable and verifiable reasoning. To train RePanda, we construct PanTabFact, a structured dataset derived from the TabFact train set, where claims are paired with executable queries generated using DeepSeek-Chat and refined through automated error correction. Fine-tuning DeepSeek-coder-7B-instruct-v1.5 on PanTabFact, RePanda achieves 84.09% accuracy on the TabFact test set. To evaluate Out-of-Distribution (OOD) generalization, we interpret question-answer pairs from WikiTableQuestions as factual claims and refer to this dataset as WikiFact. Without additional fine-tuning, RePanda achieves 84.72% accuracy on WikiFact, significantly outperforming all other baselines and demonstrating strong OOD robustness. Notably, these results closely match the zero-shot performance of DeepSeek-Chat (671B), indicating that our fine-tuning approach effectively distills structured reasoning from a much larger model into a compact, locally executable 7B model. Beyond fact verification, RePanda extends to tabular question answering by generating executable queries that retrieve precise answers. To support this, we introduce PanWiki, a dataset mapping WikiTableQuestions to pandas queries. Fine-tuning on PanWiki, RePanda achieves 75.1% accuracy in direct answer retrieval. These results highlight the effectiveness of structured execution-based reasoning for tabular verification and question answering. We have publicly released the dataset on Hugging Face at datasets/AtoosaChegini/PanTabFact.
Preference Discerning with LLM-Enhanced Generative Retrieval
Dec 11, 2024



Sequential recommendation systems aim to provide personalized recommendations for users based on their interaction history. To achieve this, they often incorporate auxiliary information, such as textual descriptions of items and auxiliary tasks, like predicting user preferences and intent. Despite numerous efforts to enhance these models, they still suffer from limited personalization. To address this issue, we propose a new paradigm, which we term preference discerning. In preference dscerning, we explicitly condition a generative sequential recommendation system on user preferences within its context. To this end, we generate user preferences using Large Language Models (LLMs) based on user reviews and item-specific data. To evaluate preference discerning capabilities of sequential recommendation systems, we introduce a novel benchmark that provides a holistic evaluation across various scenarios, including preference steering and sentiment following. We assess current state-of-the-art methods using our benchmark and show that they struggle to accurately discern user preferences. Therefore, we propose a new method named Mender ($\textbf{M}$ultimodal Prefer$\textbf{en}$ce $\textbf{d}$iscern$\textbf{er}$), which improves upon existing methods and achieves state-of-the-art performance on our benchmark. Our results show that Mender can be effectively guided by human preferences even though they have not been observed during training, paving the way toward more personalized sequential recommendation systems. We will open-source the code and benchmarks upon publication.
CantorNet: A Sandbox for Testing Geometrical and Topological Complexity Measures
Dec 02, 2024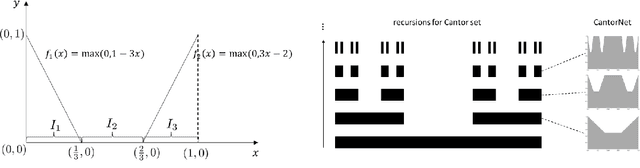
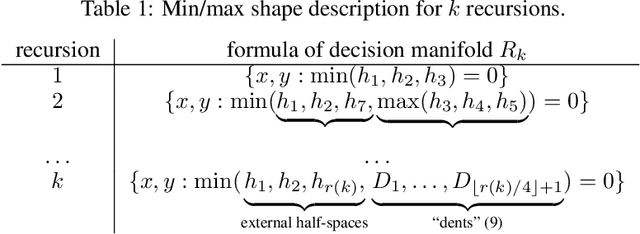
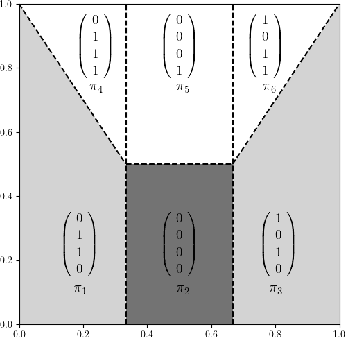
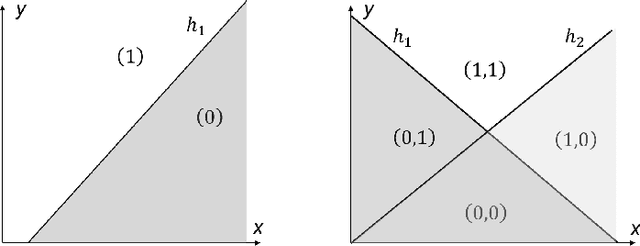
Many natural phenomena are characterized by self-similarity, for example the symmetry of human faces, or a repetitive motif of a song. Studying of such symmetries will allow us to gain deeper insights into the underlying mechanisms of complex systems. Recognizing the importance of understanding these patterns, we propose a geometrically inspired framework to study such phenomena in artificial neural networks. To this end, we introduce \emph{CantorNet}, inspired by the triadic construction of the Cantor set, which was introduced by Georg Cantor in the $19^\text{th}$ century. In mathematics, the Cantor set is a set of points lying on a single line that is self-similar and has a counter intuitive property of being an uncountably infinite null set. Similarly, we introduce CantorNet as a sandbox for studying self-similarity by means of novel topological and geometrical complexity measures. CantorNet constitutes a family of ReLU neural networks that spans the whole spectrum of possible Kolmogorov complexities, including the two opposite descriptions (linear and exponential as measured by the description length). CantorNet's decision boundaries can be arbitrarily ragged, yet are analytically known. Besides serving as a testing ground for complexity measures, our work may serve to illustrate potential pitfalls in geometry-ignorant data augmentation techniques and adversarial attacks.
Unifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024

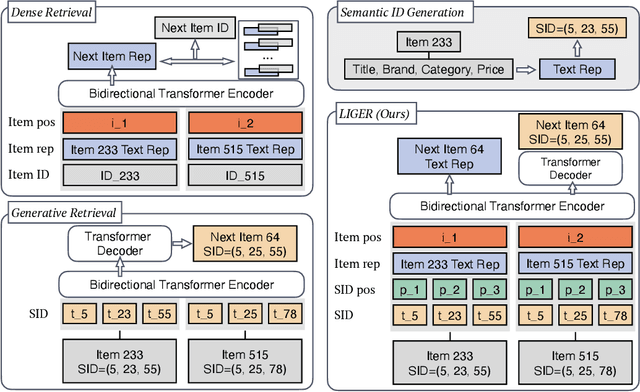
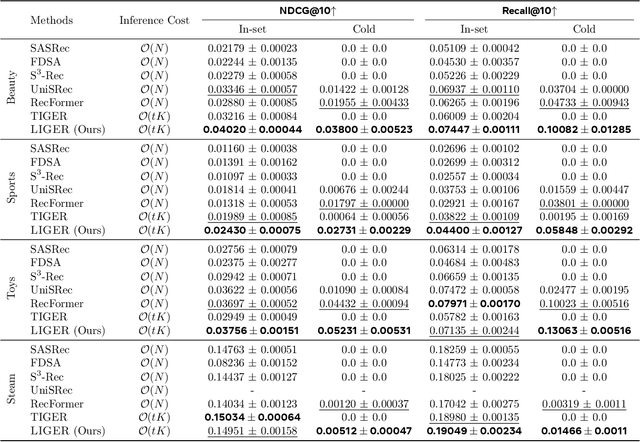
Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.
User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance
Aug 04, 2024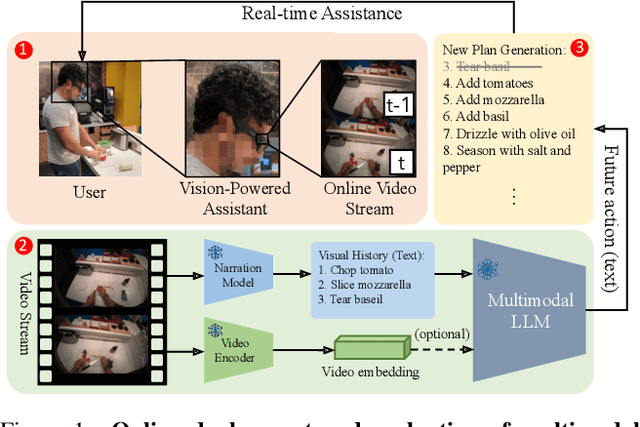

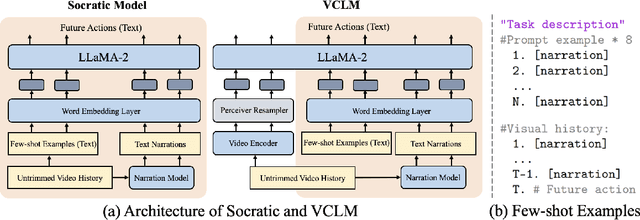

Our research investigates the capability of modern multimodal reasoning models, powered by Large Language Models (LLMs), to facilitate vision-powered assistants for multi-step daily activities. Such assistants must be able to 1) encode relevant visual history from the assistant's sensors, e.g., camera, 2) forecast future actions for accomplishing the activity, and 3) replan based on the user in the loop. To evaluate the first two capabilities, grounding visual history and forecasting in short and long horizons, we conduct benchmarking of two prominent classes of multimodal LLM approaches -- Socratic Models and Vision Conditioned Language Models (VCLMs) on video-based action anticipation tasks using offline datasets. These offline benchmarks, however, do not allow us to close the loop with the user, which is essential to evaluate the replanning capabilities and measure successful activity completion in assistive scenarios. To that end, we conduct a first-of-its-kind user study, with 18 participants performing 3 different multi-step cooking activities while wearing an egocentric observation device called Aria and following assistance from multimodal LLMs. We find that the Socratic approach outperforms VCLMs in both offline and online settings. We further highlight how grounding long visual history, common in activity assistance, remains challenging in current models, especially for VCLMs, and demonstrate that offline metrics do not indicate online performance.
EgoAdapt: A multi-stream evaluation study of adaptation to real-world egocentric user video
Jul 11, 2023



In egocentric action recognition a single population model is typically trained and subsequently embodied on a head-mounted device, such as an augmented reality headset. While this model remains static for new users and environments, we introduce an adaptive paradigm of two phases, where after pretraining a population model, the model adapts on-device and online to the user's experience. This setting is highly challenging due to the change from population to user domain and the distribution shifts in the user's data stream. Coping with the latter in-stream distribution shifts is the focus of continual learning, where progress has been rooted in controlled benchmarks but challenges faced in real-world applications often remain unaddressed. We introduce EgoAdapt, a benchmark for real-world egocentric action recognition that facilitates our two-phased adaptive paradigm, and real-world challenges naturally occur in the egocentric video streams from Ego4d, such as long-tailed action distributions and large-scale classification over 2740 actions. We introduce an evaluation framework that directly exploits the user's data stream with new metrics to measure the adaptation gain over the population model, online generalization, and hindsight performance. In contrast to single-stream evaluation in existing works, our framework proposes a meta-evaluation that aggregates the results from 50 independent user streams. We provide an extensive empirical study for finetuning and experience replay.
Pretrained Language Models as Visual Planners for Human Assistance
Apr 27, 2023To make progress towards multi-modal AI assistants which can guide users to achieve complex multi-step goals, we propose the task of Visual Planning for Assistance (VPA). Given a goal briefly described in natural language, e.g., "make a shelf", and a video of the user's progress so far, the aim of VPA is to obtain a plan, i.e., a sequence of actions such as "sand shelf", "paint shelf", etc., to achieve the goal. This requires assessing the user's progress from the untrimmed video, and relating it to the requirements of underlying goal, i.e., relevance of actions and ordering dependencies amongst them. Consequently, this requires handling long video history, and arbitrarily complex action dependencies. To address these challenges, we decompose VPA into video action segmentation and forecasting. We formulate the forecasting step as a multi-modal sequence modeling problem and present Visual Language Model based Planner (VLaMP), which leverages pre-trained LMs as the sequence model. We demonstrate that VLaMP performs significantly better than baselines w.r.t all metrics that evaluate the generated plan. Moreover, through extensive ablations, we also isolate the value of language pre-training, visual observations, and goal information on the performance. We will release our data, model, and code to enable future research on visual planning for assistance.