 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Preference Modeling Using Visual Motion Prediction Improves Robot Skill Learning from Egocentric Human Video
Feb 11, 2026We present an approach to robot learning from egocentric human videos by modeling human preferences in a reward function and optimizing robot behavior to maximize this reward. Prior work on reward learning from human videos attempts to measure the long-term value of a visual state as the temporal distance between it and the terminal state in a demonstration video. These approaches make assumptions that limit performance when learning from video. They must also transfer the learned value function across the embodiment and environment gap. Our method models human preferences by learning to predict the motion of tracked points between subsequent images and defines a reward function as the agreement between predicted and observed object motion in a robot's behavior at each step. We then use a modified Soft Actor Critic (SAC) algorithm initialized with 10 on-robot demonstrations to estimate a value function from this reward and optimize a policy that maximizes this value function, all on the robot. Our approach is capable of learning on a real robot, and we show that policies learned with our reward model match or outperform prior work across multiple tasks in both simulation and on the real robot.
Latent Policy Steering with Embodiment-Agnostic Pretrained World Models
Jul 17, 2025



Learning visuomotor policies via imitation has proven effective across a wide range of robotic domains. However, the performance of these policies is heavily dependent on the number of training demonstrations, which requires expensive data collection in the real world. In this work, we aim to reduce data collection efforts when learning visuomotor robot policies by leveraging existing or cost-effective data from a wide range of embodiments, such as public robot datasets and the datasets of humans playing with objects (human data from play). Our approach leverages two key insights. First, we use optic flow as an embodiment-agnostic action representation to train a World Model (WM) across multi-embodiment datasets, and finetune it on a small amount of robot data from the target embodiment. Second, we develop a method, Latent Policy Steering (LPS), to improve the output of a behavior-cloned policy by searching in the latent space of the WM for better action sequences. In real world experiments, we observe significant improvements in the performance of policies trained with a small amount of data (over 50% relative improvement with 30 demonstrations and over 20% relative improvement with 50 demonstrations) by combining the policy with a WM pretrained on two thousand episodes sampled from the existing Open X-embodiment dataset across different robots or a cost-effective human dataset from play.
User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance
Aug 04, 2024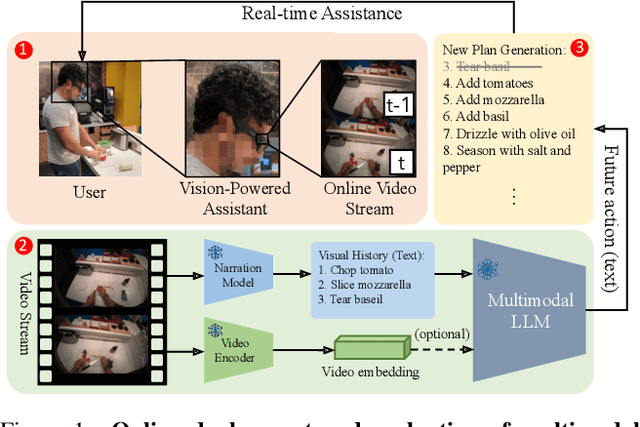

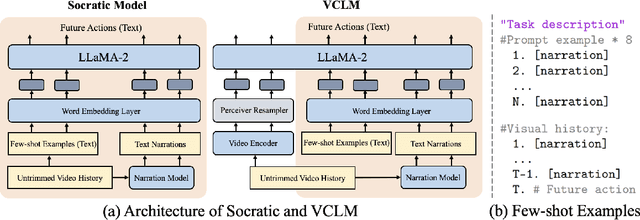

Our research investigates the capability of modern multimodal reasoning models, powered by Large Language Models (LLMs), to facilitate vision-powered assistants for multi-step daily activities. Such assistants must be able to 1) encode relevant visual history from the assistant's sensors, e.g., camera, 2) forecast future actions for accomplishing the activity, and 3) replan based on the user in the loop. To evaluate the first two capabilities, grounding visual history and forecasting in short and long horizons, we conduct benchmarking of two prominent classes of multimodal LLM approaches -- Socratic Models and Vision Conditioned Language Models (VCLMs) on video-based action anticipation tasks using offline datasets. These offline benchmarks, however, do not allow us to close the loop with the user, which is essential to evaluate the replanning capabilities and measure successful activity completion in assistive scenarios. To that end, we conduct a first-of-its-kind user study, with 18 participants performing 3 different multi-step cooking activities while wearing an egocentric observation device called Aria and following assistance from multimodal LLMs. We find that the Socratic approach outperforms VCLMs in both offline and online settings. We further highlight how grounding long visual history, common in activity assistance, remains challenging in current models, especially for VCLMs, and demonstrate that offline metrics do not indicate online performance.
Using Memory-Based Learning to Solve Tasks with State-Action Constraints
Mar 08, 2023


Tasks where the set of possible actions depend discontinuously on the state pose a significant challenge for current reinforcement learning algorithms. For example, a locked door must be first unlocked, and then the handle turned before the door can be opened. The sequential nature of these tasks makes obtaining final rewards difficult, and transferring information between task variants using continuous learned values such as weights rather than discrete symbols can be inefficient. Our key insight is that agents that act and think symbolically are often more effective in dealing with these tasks. We propose a memory-based learning approach that leverages the symbolic nature of constraints and temporal ordering of actions in these tasks to quickly acquire and transfer high-level information. We evaluate the performance of memory-based learning on both real and simulated tasks with approximately discontinuous constraints between states and actions, and show our method learns to solve these tasks an order of magnitude faster than both model-based and model-free deep reinforcement learning methods.
Configuration Space Decomposition for Scalable Proxy Collision Checking in Robot Planning and Control
Jan 26, 2022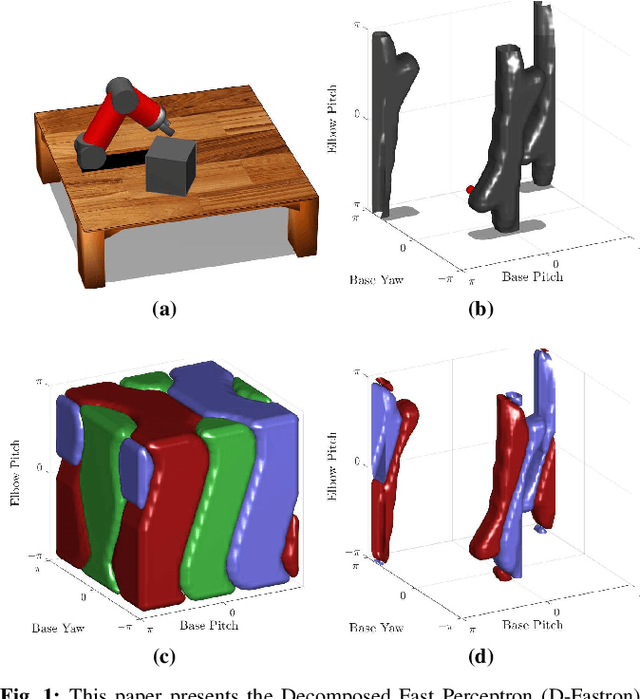
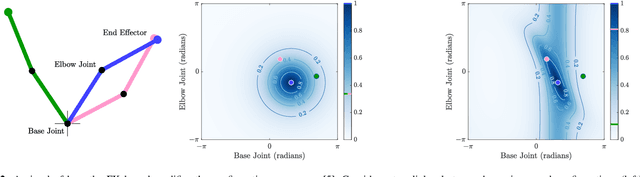


Real-time robot motion planning in complex high-dimensional environments remains an open problem. Motion planning algorithms, and their underlying collision checkers, are crucial to any robot control stack. Collision checking takes up a large portion of the computational time in robot motion planning. Existing collision checkers make trade-offs between speed and accuracy and scale poorly to high-dimensional, complex environments. We present a novel space decomposition method using K-Means clustering in the Forward Kinematics space to accelerate proxy collision checking. We train individual configuration space models using Fastron, a kernel perceptron algorithm, on these decomposed subspaces, yielding compact yet highly accurate models that can be queried rapidly and scale better to more complex environments. We demonstrate this new method, called Decomposed Fast Perceptron (D-Fastron), on the 7-DOF Baxter robot producing on average 29x faster collision checks and up to 9.8x faster motion planning compared to state-of-the-art geometric collision checkers.
Model-free Visual Control for Continuum Robot Manipulators via Orientation Adaptation
Sep 01, 2019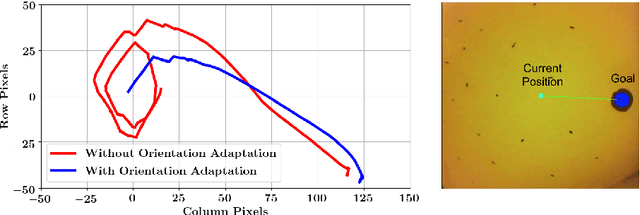
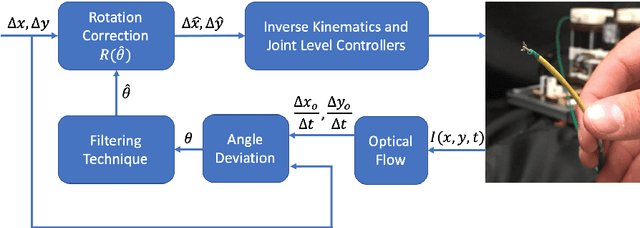


We present an orientation adaptive controller to compensate for the effects of highly constrained environments on continuum manipulator actuation. A transformation matrix updated using optimal estimation techniques from optical flow measurements captured by the distal camera is composed with any Jacobian estimation or kinematic model to compensate for these effects. By utilizing domain knowledge to define the structure of this matrix, fewer parameters need to be estimated and a stable controller can be guaranteed. The algorithm is tested on a custom robotic catheter and convergence is shown both empirically and theoretically.