 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
The Space Between: On Folding, Symmetries and Sampling
Mar 11, 2025Recent findings suggest that consecutive layers of neural networks with the ReLU activation function \emph{fold} the input space during the learning process. While many works hint at this phenomenon, an approach to quantify the folding was only recently proposed by means of a space folding measure based on Hamming distance in the ReLU activation space. We generalize this measure to a wider class of activation functions through introduction of equivalence classes of input data, analyse its mathematical and computational properties and come up with an efficient sampling strategy for its implementation. Moreover, it has been observed that space folding values increase with network depth when the generalization error is low, but decrease when the error increases. This underpins that learned symmetries in the data manifold (e.g., invariance under reflection) become visible in terms of space folds, contributing to the network's generalization capacity. Inspired by these findings, we outline a novel regularization scheme that encourages the network to seek solutions characterized by higher folding values.
CantorNet: A Sandbox for Testing Geometrical and Topological Complexity Measures
Dec 02, 2024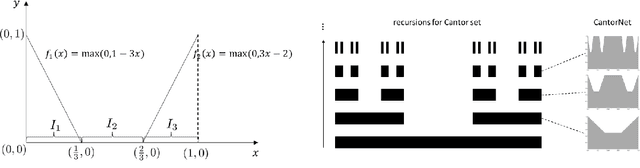
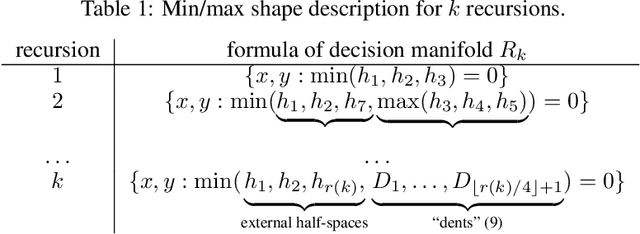
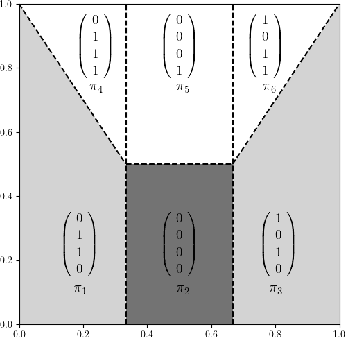
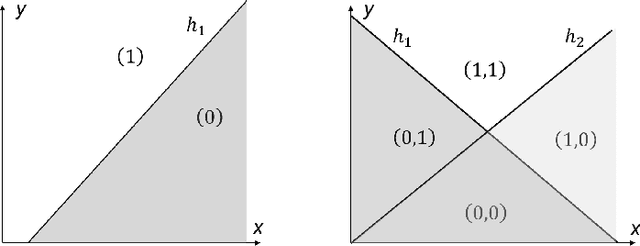
Many natural phenomena are characterized by self-similarity, for example the symmetry of human faces, or a repetitive motif of a song. Studying of such symmetries will allow us to gain deeper insights into the underlying mechanisms of complex systems. Recognizing the importance of understanding these patterns, we propose a geometrically inspired framework to study such phenomena in artificial neural networks. To this end, we introduce \emph{CantorNet}, inspired by the triadic construction of the Cantor set, which was introduced by Georg Cantor in the $19^\text{th}$ century. In mathematics, the Cantor set is a set of points lying on a single line that is self-similar and has a counter intuitive property of being an uncountably infinite null set. Similarly, we introduce CantorNet as a sandbox for studying self-similarity by means of novel topological and geometrical complexity measures. CantorNet constitutes a family of ReLU neural networks that spans the whole spectrum of possible Kolmogorov complexities, including the two opposite descriptions (linear and exponential as measured by the description length). CantorNet's decision boundaries can be arbitrarily ragged, yet are analytically known. Besides serving as a testing ground for complexity measures, our work may serve to illustrate potential pitfalls in geometry-ignorant data augmentation techniques and adversarial attacks.
On Data Augmentation and Adversarial Risk: An Empirical Analysis
Jul 06, 2020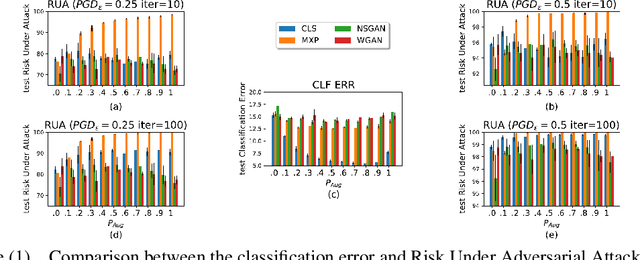
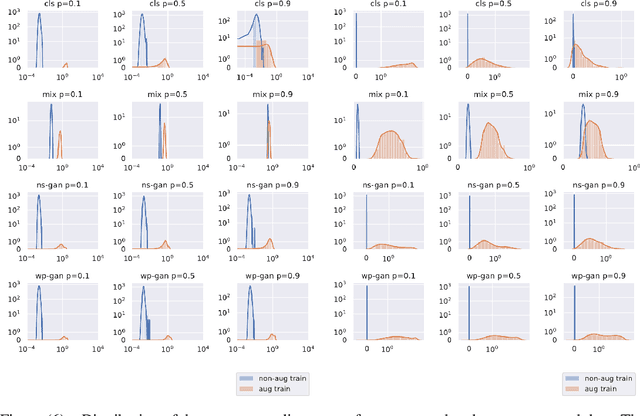
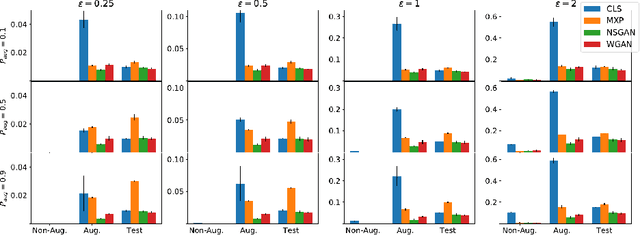
Data augmentation techniques have become standard practice in deep learning, as it has been shown to greatly improve the generalisation abilities of models. These techniques rely on different ideas such as invariance-preserving transformations (e.g, expert-defined augmentation), statistical heuristics (e.g, Mixup), and learning the data distribution (e.g, GANs). However, in the adversarial settings it remains unclear under what conditions such data augmentation methods reduce or even worsen the misclassification risk. In this paper, we therefore analyse the effect of different data augmentation techniques on the adversarial risk by three measures: (a) the well-known risk under adversarial attacks, (b) a new measure of prediction-change stress based on the Laplacian operator, and (c) the influence of training examples on prediction. The results of our empirical analysis disprove the hypothesis that an improvement in the classification performance induced by a data augmentation is always accompanied by an improvement in the risk under adversarial attack. Further, our results reveal that the augmented data has more influence than the non-augmented data, on the resulting models. Taken together, our results suggest that general-purpose data augmentations that do not take into the account the characteristics of the data and the task, must be applied with care.
ReLU Code Space: A Basis for Rating Network Quality Besides Accuracy
May 20, 2020We propose a new metric space of ReLU activation codes equipped with a truncated Hamming distance which establishes an isometry between its elements and polyhedral bodies in the input space which have recently been shown to be strongly related to safety, robustness, and confidence. This isometry allows the efficient computation of adjacency relations between the polyhedral bodies. Experiments on MNIST and CIFAR-10 indicate that information besides accuracy might be stored in the code space.