 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Space Between: On Folding, Symmetries and Sampling
Mar 11, 2025Recent findings suggest that consecutive layers of neural networks with the ReLU activation function \emph{fold} the input space during the learning process. While many works hint at this phenomenon, an approach to quantify the folding was only recently proposed by means of a space folding measure based on Hamming distance in the ReLU activation space. We generalize this measure to a wider class of activation functions through introduction of equivalence classes of input data, analyse its mathematical and computational properties and come up with an efficient sampling strategy for its implementation. Moreover, it has been observed that space folding values increase with network depth when the generalization error is low, but decrease when the error increases. This underpins that learned symmetries in the data manifold (e.g., invariance under reflection) become visible in terms of space folds, contributing to the network's generalization capacity. Inspired by these findings, we outline a novel regularization scheme that encourages the network to seek solutions characterized by higher folding values.
Contrastive Language-Image Pre-training for the Italian Language
Aug 19, 2021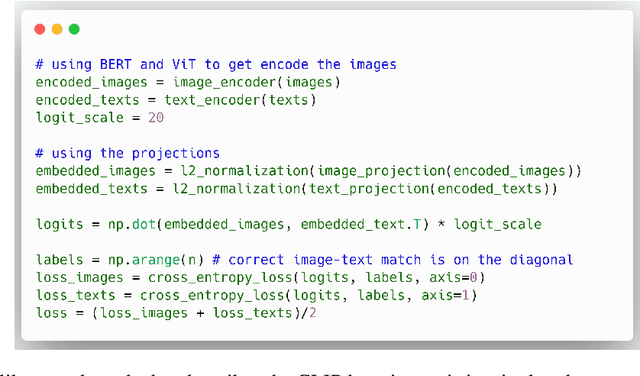
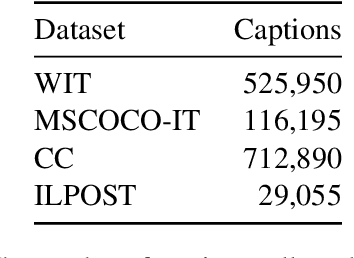


CLIP (Contrastive Language-Image Pre-training) is a very recent multi-modal model that jointly learns representations of images and texts. The model is trained on a massive amount of English data and shows impressive performance on zero-shot classification tasks. Training the same model on a different language is not trivial, since data in other languages might be not enough and the model needs high-quality translations of the texts to guarantee a good performance. In this paper, we present the first CLIP model for the Italian Language (CLIP-Italian), trained on more than 1.4 million image-text pairs. Results show that CLIP-Italian outperforms the multilingual CLIP model on the tasks of image retrieval and zero-shot classification.