 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cost-Accuracy Trade-offs in Multimodal Search Relevance Judgements
Oct 25, 2024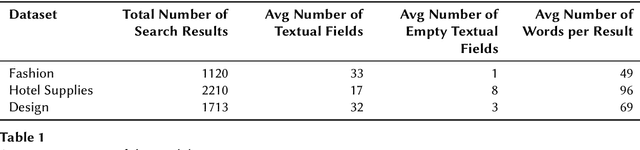

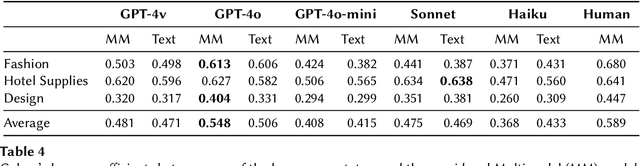
Large Language Models (LLMs) have demonstrated potential as effective search relevance evaluators. However, there is a lack of comprehensive guidance on which models consistently perform optimally across various contexts or within specific use cases. In this paper, we assess several LLMs and Multimodal Language Models (MLLMs) in terms of their alignment with human judgments across multiple multimodal search scenarios. Our analysis investigates the trade-offs between cost and accuracy, highlighting that model performance varies significantly depending on the context. Interestingly, in smaller models, the inclusion of a visual component may hinder performance rather than enhance it. These findings highlight the complexities involved in selecting the most appropriate model for practical applications.
Reliable LLM-based User Simulator for Task-Oriented Dialogue Systems
Feb 20, 2024



In the realm of dialogue systems, user simulation techniques have emerged as a game-changer, redefining the evaluation and enhancement of task-oriented dialogue (TOD) systems. These methods are crucial for replicating real user interactions, enabling applications like synthetic data augmentation, error detection, and robust evaluation. However, existing approaches often rely on rigid rule-based methods or on annotated data. This paper introduces DAUS, a Domain-Aware User Simulator. Leveraging large language models, we fine-tune DAUS on real examples of task-oriented dialogues. Results on two relevant benchmarks showcase significant improvements in terms of user goal fulfillment. Notably, we have observed that fine-tuning enhances the simulator's coherence with user goals, effectively mitigating hallucinations -- a major source of inconsistencies in simulator responses.
In-Context Learning User Simulators for Task-Oriented Dialog Systems
Jun 01, 2023



This paper presents a novel application of large language models in user simulation for task-oriented dialog systems, specifically focusing on an in-context learning approach. By harnessing the power of these models, the proposed approach generates diverse utterances based on user goals and limited dialog examples. Unlike traditional simulators, this method eliminates the need for labor-intensive rule definition or extensive annotated data, making it more efficient and accessible. Additionally, an error analysis of the interaction between the user simulator and dialog system uncovers common mistakes, providing valuable insights into areas that require improvement. Our implementation is available at https://github.com/telepathylabsai/prompt-based-user-simulator.
FashionCLIP: Connecting Language and Images for Product Representations
Apr 11, 2022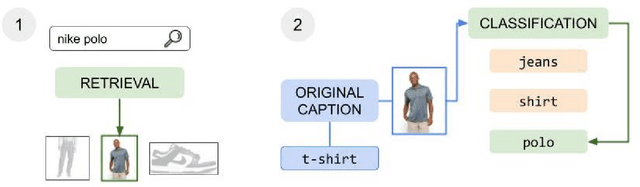
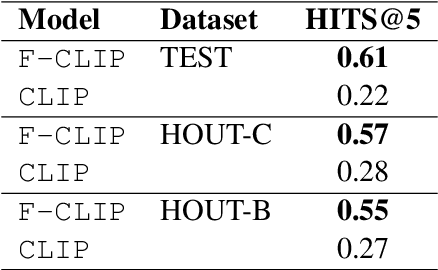

The steady rise of online shopping goes hand in hand with the development of increasingly complex ML and NLP models. While most use cases are cast as specialized supervised learning problems, we argue that practitioners would greatly benefit from more transferable representations of products. In this work, we build on recent developments in contrastive learning to train FashionCLIP, a CLIP-like model for the fashion industry. We showcase its capabilities for retrieval, classification and grounding, and release our model and code to the community.
One Configuration to Rule Them All? Towards Hyperparameter Transfer in Topic Models using Multi-Objective Bayesian Optimization
Feb 15, 2022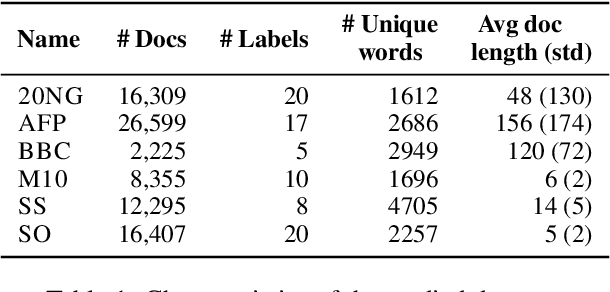
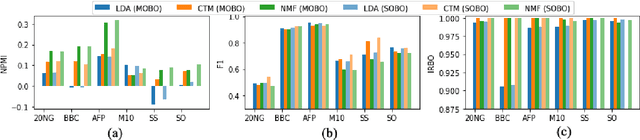


Topic models are statistical methods that extract underlying topics from document collections. When performing topic modeling, a user usually desires topics that are coherent, diverse between each other, and that constitute good document representations for downstream tasks (e.g. document classification). In this paper, we conduct a multi-objective hyperparameter optimization of three well-known topic models. The obtained results reveal the conflicting nature of different objectives and that the training corpus characteristics are crucial for the hyperparameter selection, suggesting that it is possible to transfer the optimal hyperparameter configurations between datasets.
Contrastive Language-Image Pre-training for the Italian Language
Aug 19, 2021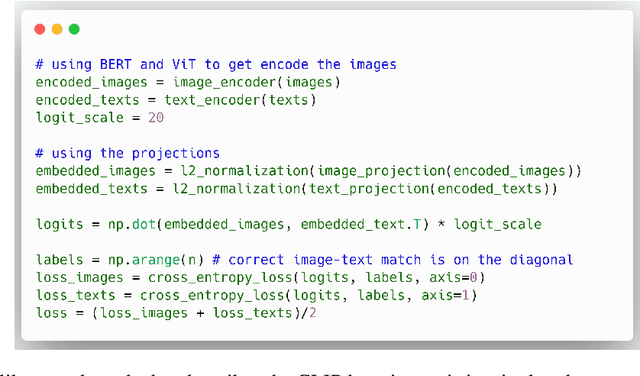


CLIP (Contrastive Language-Image Pre-training) is a very recent multi-modal model that jointly learns representations of images and texts. The model is trained on a massive amount of English data and shows impressive performance on zero-shot classification tasks. Training the same model on a different language is not trivial, since data in other languages might be not enough and the model needs high-quality translations of the texts to guarantee a good performance. In this paper, we present the first CLIP model for the Italian Language (CLIP-Italian), trained on more than 1.4 million image-text pairs. Results show that CLIP-Italian outperforms the multilingual CLIP model on the tasks of image retrieval and zero-shot classification.
Cross-lingual Contextualized Topic Models with Zero-shot Learning
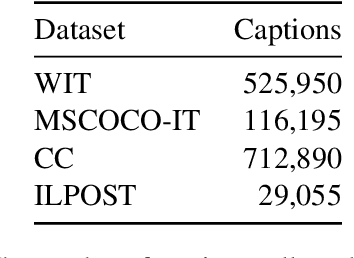
Apr 16, 2020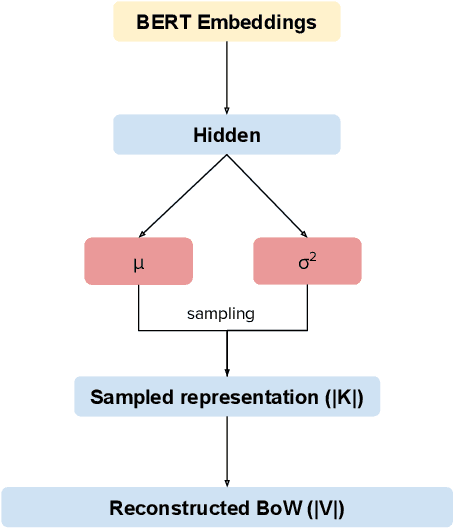
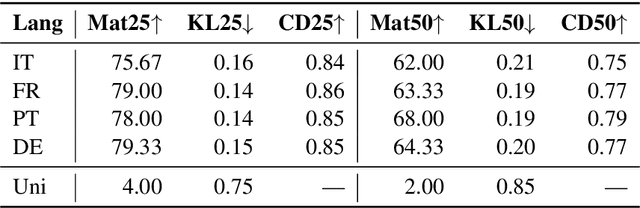
Many data sets in a domain (reviews, forums, news, etc.) exist in parallel languages. They all cover the same content, but the linguistic differences make it impossible to use traditional, bag-of-word-based topic models. Models have to be either single-language or suffer from a huge, but extremely sparse vocabulary. Both issues can be addressed by transfer learning. In this paper, we introduce a zero-shot cross-lingual topic model, i.e., our model learns topics on one language (here, English), and predicts them for documents in other languages. By using the text of the same document in different languages, we can evaluate the quality of the predictions. Our results show that topics are coherent and stable across languages, which suggests exciting future research directions.
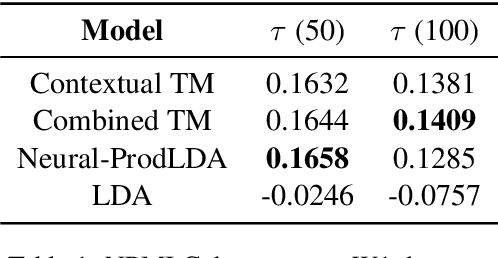
Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence
Apr 08, 2020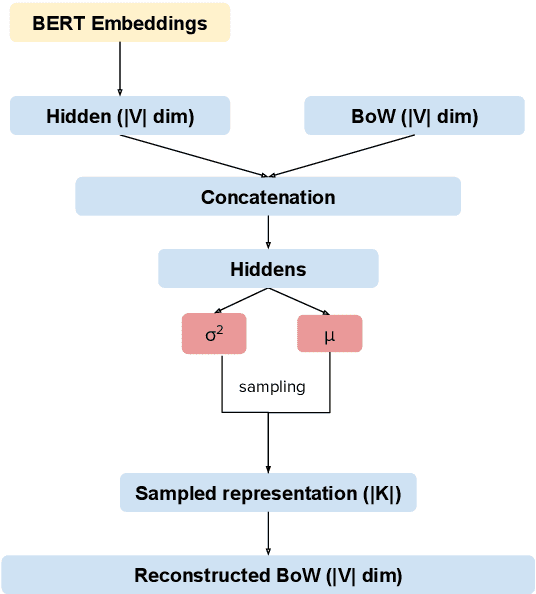
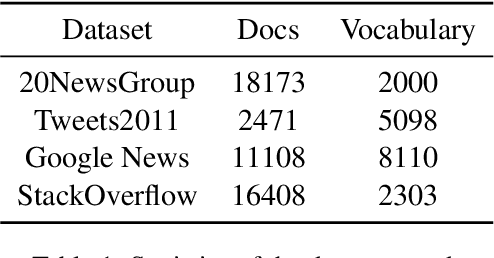
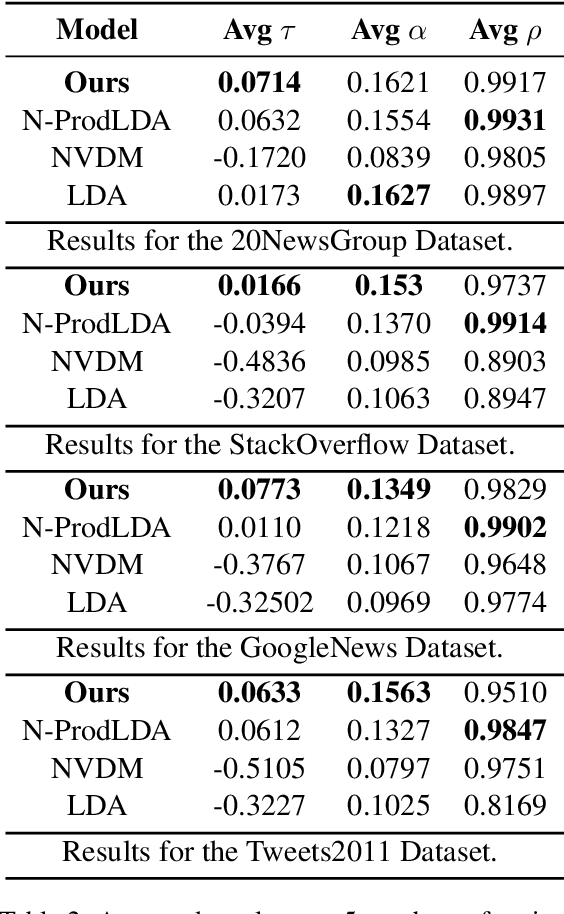
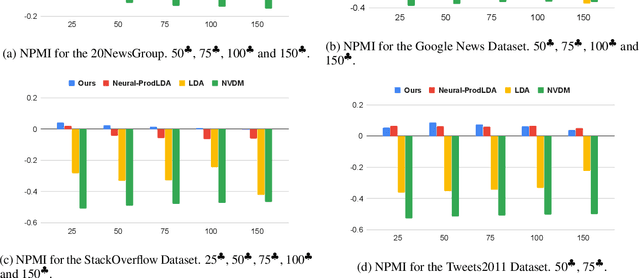
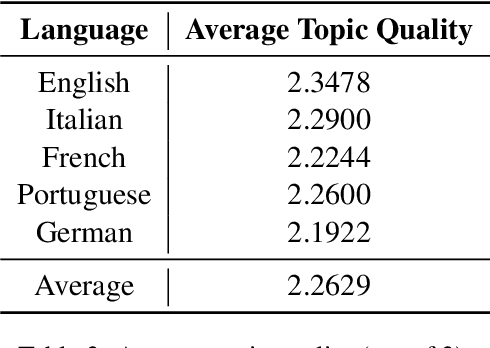
Topic models extract meaningful groups of words from documents, allowing for a better understanding of data. However, the solutions are often not coherent enough, and thus harder to interpret. Coherence can be improved by adding more contextual knowledge to the model. Recently, neural topic models have become available, while BERT-based representations have further pushed the state of the art of neural models in general. We combine pre-trained representations and neural topic models. Pre-trained BERT sentence embeddings indeed support the generation of more meaningful and coherent topics than either standard LDA or existing neural topic models. Results on four datasets show that our approach effectively increases topic coherence.