 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Causal Reasoning into Automated Fact-Checking
Dec 15, 2025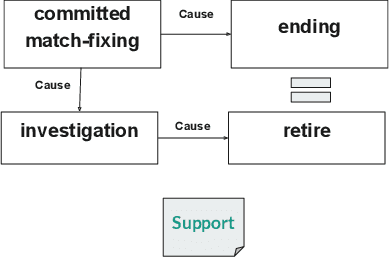
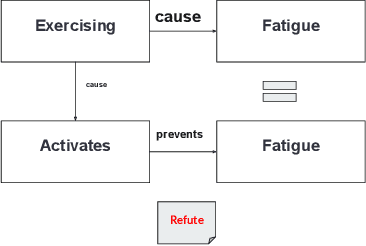

In fact-checking applications, a common reason to reject a claim is to detect the presence of erroneous cause-effect relationships between the events at play. However, current automated fact-checking methods lack dedicated causal-based reasoning, potentially missing a valuable opportunity for semantically rich explainability. To address this gap, we propose a methodology that combines event relation extraction, semantic similarity computation, and rule-based reasoning to detect logical inconsistencies between chains of events mentioned in a claim and in an evidence. Evaluated on two fact-checking datasets, this method establishes the first baseline for integrating fine-grained causal event relationships into fact-checking and enhance explainability of verdict prediction.
* Extended version of the accepted ACM SAC paper
One Configuration to Rule Them All? Towards Hyperparameter Transfer in Topic Models using Multi-Objective Bayesian Optimization
Feb 15, 2022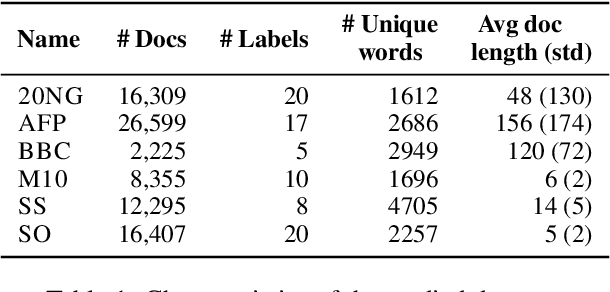
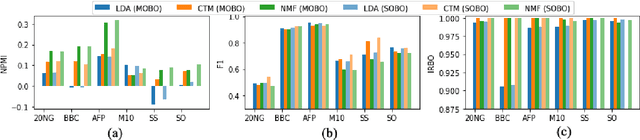


Topic models are statistical methods that extract underlying topics from document collections. When performing topic modeling, a user usually desires topics that are coherent, diverse between each other, and that constitute good document representations for downstream tasks (e.g. document classification). In this paper, we conduct a multi-objective hyperparameter optimization of three well-known topic models. The obtained results reveal the conflicting nature of different objectives and that the training corpus characteristics are crucial for the hyperparameter selection, suggesting that it is possible to transfer the optimal hyperparameter configurations between datasets.
Many-to-one Recurrent Neural Network for Session-based Recommendation
Aug 25, 2020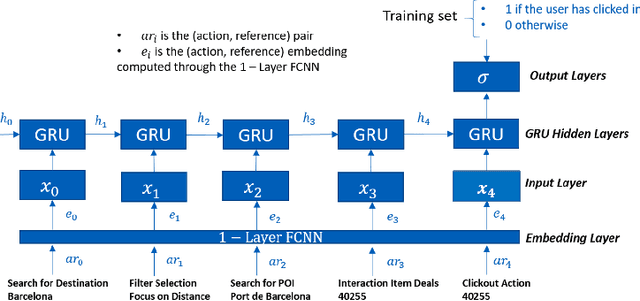
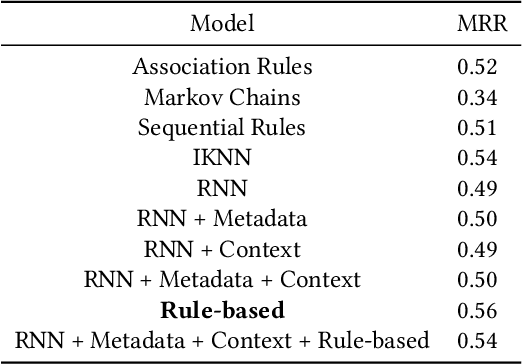
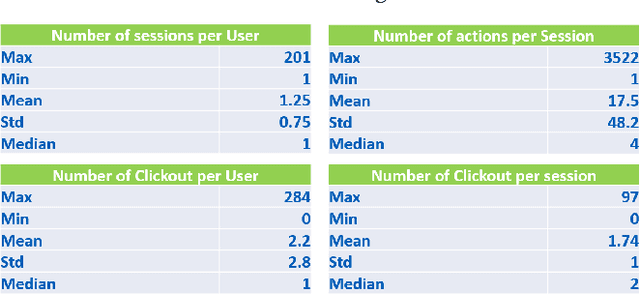
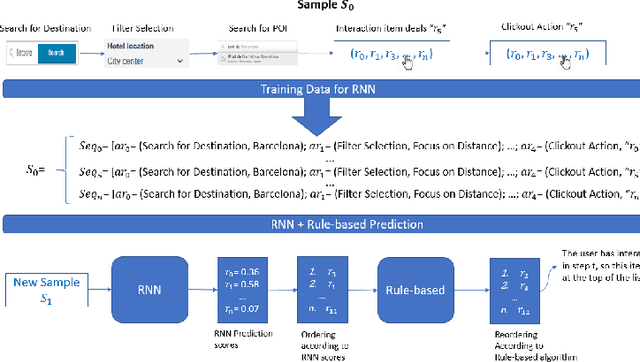
This paper presents the D2KLab team's approach to the RecSys Challenge 2019 which focuses on the task of recommending accommodations based on user sessions. What is the feeling of a person who says "Rooms of the hotel are enormous, staff are friendly and efficient"? It is positive. Similarly to the sequence of words in a sentence where one can affirm what the feeling is, analysing a sequence of actions performed by a user in a website can lead to predict what will be the item the user will add to his basket at the end of the shopping session. We propose to use a many-to-one recurrent neural network that learns the probability that a user will click on an accommodation based on the sequence of actions he has performed during his browsing session. More specifically, we combine a rule-based algorithm with a Gated Recurrent Unit RNN in order to sort the list of accommodations that is shown to the user. We optimized the RNN on a validation set, tuning the hyper-parameters such as the learning rate, the batch-size and the accommodation embedding size. This analogy with the sentiment analysis task gives promising results. However, it is computationally demanding in the training phase and it needs to be further tuned.
Two Stages Approach for Tweet Engagement Prediction
Aug 24, 2020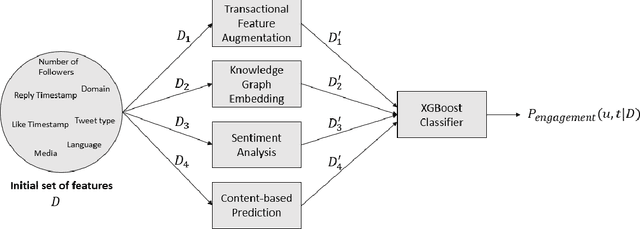
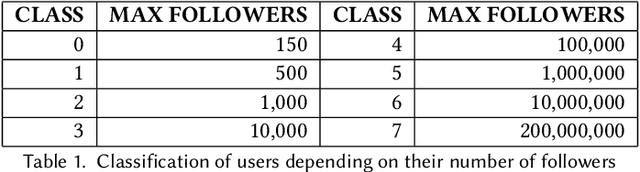
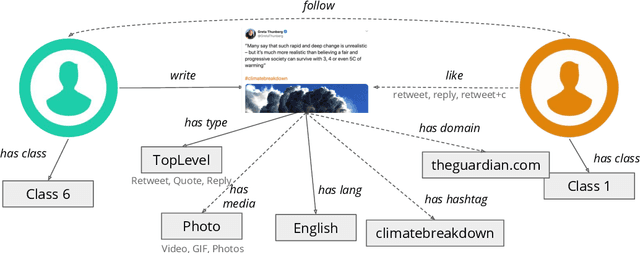

This paper describes the approach proposed by the D2KLab team for the 2020 RecSys Challenge on the task of predicting user engagement facing tweets. This approach relies on two distinct stages. First, relevant features are learned from the challenge dataset. These features are heterogeneous and are the results of different learning modules such as handcrafted features, knowledge graph embeddings, sentiment analysis features and BERT word embeddings. Second, these features are provided in input to an ensemble system based on XGBoost. This approach, only trained on a subset of the entire challenge dataset, ranked 22 in the final leaderboard.
The MeMAD Submission to the WMT18 Multimodal Translation Task
Sep 03, 2018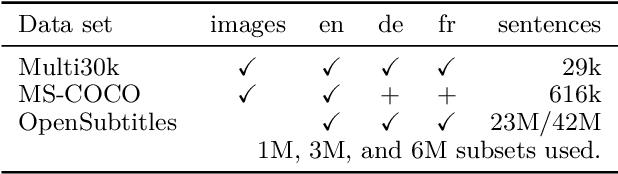
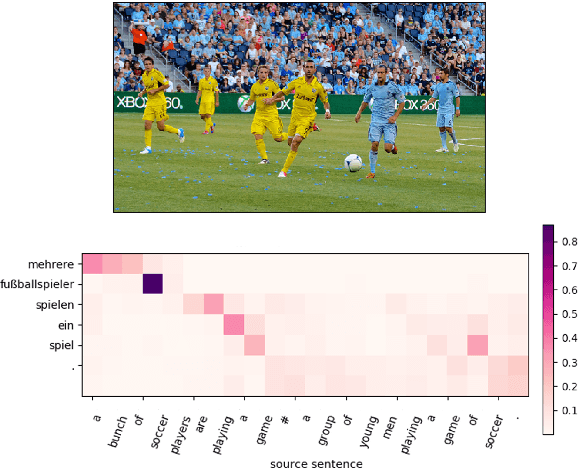
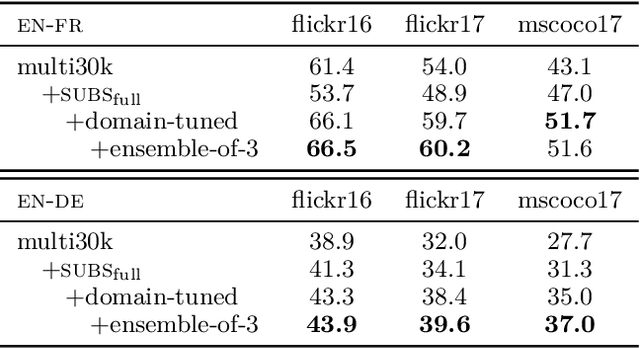

This paper describes the MeMAD project entry to the WMT Multimodal Machine Translation Shared Task. We propose adapting the Transformer neural machine translation (NMT) architecture to a multi-modal setting. In this paper, we also describe the preliminary experiments with text-only translation systems leading us up to this choice. We have the top scoring system for both English-to-German and English-to-French, according to the automatic metrics for flickr18. Our experiments show that the effect of the visual features in our system is small. Our largest gains come from the quality of the underlying text-only NMT system. We find that appropriate use of additional data is effective.