 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Morphomics, Morphological Features on CT scans for lung nodule malignancy diagnosis
Jul 27, 2022
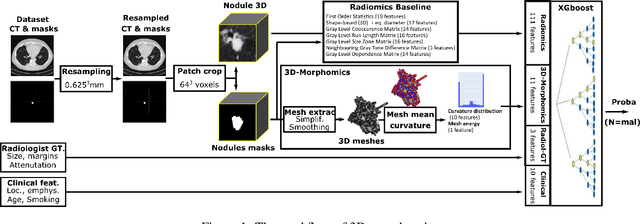
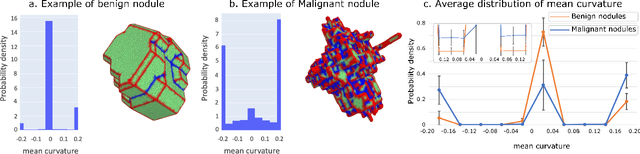
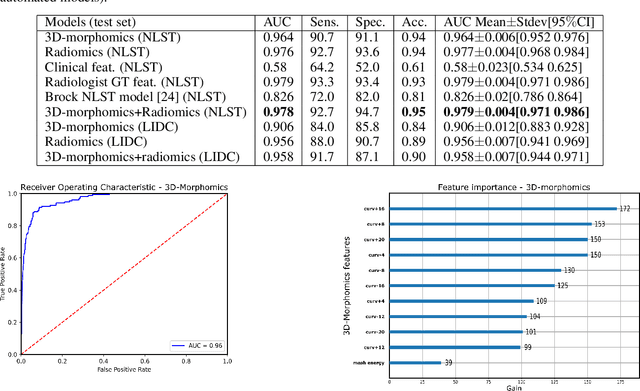
Pathologies systematically induce morphological changes, thus providing a major but yet insufficiently quantified source of observables for diagnosis. The study develops a predictive model of the pathological states based on morphological features (3D-morphomics) on Computed Tomography (CT) volumes. A complete workflow for mesh extraction and simplification of an organ's surface is developed, and coupled with an automatic extraction of morphological features given by the distribution of mean curvature and mesh energy. An XGBoost supervised classifier is then trained and tested on the 3D-morphomics to predict the pathological states. This framework is applied to the prediction of the malignancy of lung's nodules. On a subset of NLST database with malignancy confirmed biopsy, using 3D-morphomics only, the classification model of lung nodules into malignant vs. benign achieves 0.964 of AUC. Three other sets of classical features are trained and tested, (1) clinical relevant features gives an AUC of 0.58, (2) 111 radiomics gives an AUC of 0.976, (3) radiologist ground truth (GT) containing the nodule size, attenuation and spiculation qualitative annotations gives an AUC of 0.979. We also test the Brock model and obtain an AUC of 0.826. Combining 3D-morphomics and radiomics features achieves state-of-the-art results with an AUC of 0.978 where the 3D-morphomics have some of the highest predictive powers. As a validation on a public independent cohort, models are applied to the LIDC dataset, the 3D-morphomics achieves an AUC of 0.906 and the 3D-morphomics+radiomics achieves an AUC of 0.958, which ranks second in the challenge among deep models. It establishes the curvature distributions as efficient features for predicting lung nodule malignancy and a new method that can be applied directly to arbitrary computer aided diagnosis task.
Optimization Strategies in Multi-Task Learning: Averaged or Independent Losses?
Oct 04, 2021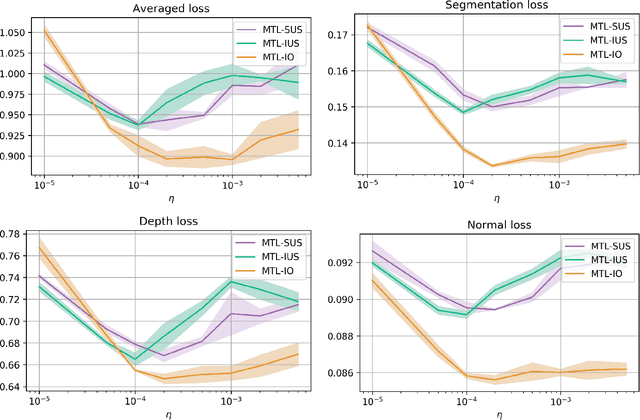
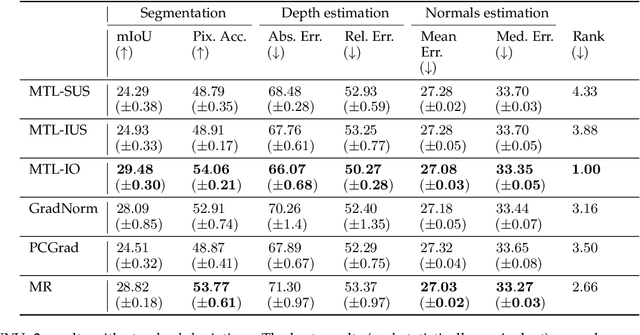
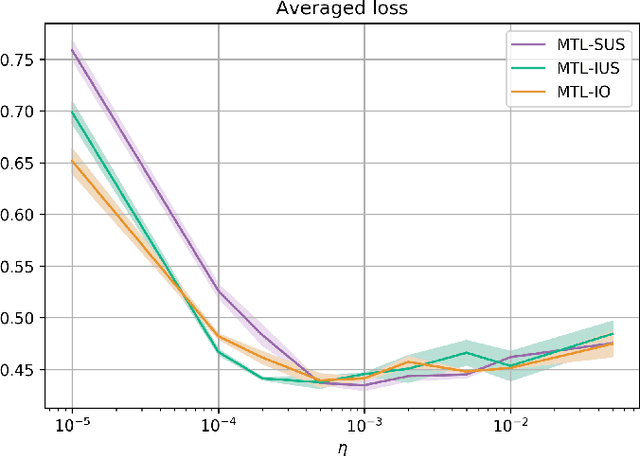
In Multi-Task Learning (MTL), it is a common practice to train multi-task networks by optimizing an objective function, which is a weighted average of the task-specific objective functions. Although the computational advantages of this strategy are clear, the complexity of the resulting loss landscape has not been studied in the literature. Arguably, its optimization may be more difficult than a separate optimization of the constituting task-specific objectives. In this work, we investigate the benefits of such an alternative, by alternating independent gradient descent steps on the different task-specific objective functions and we formulate a novel way to combine this approach with state-of-the-art optimizers. As the separation of task-specific objectives comes at the cost of increased computational time, we propose a random task grouping as a trade-off between better optimization and computational efficiency. Experimental results over three well-known visual MTL datasets show better overall absolute performance on losses and standard metrics compared to an averaged objective function and other state-of-the-art MTL methods. In particular, our method shows the most benefits when dealing with tasks of different nature and it enables a wider exploration of the shared parameter space. We also show that our random grouping strategy allows to trade-off between these benefits and computational efficiency.
Maximum Roaming Multi-Task Learning
Jun 17, 2020
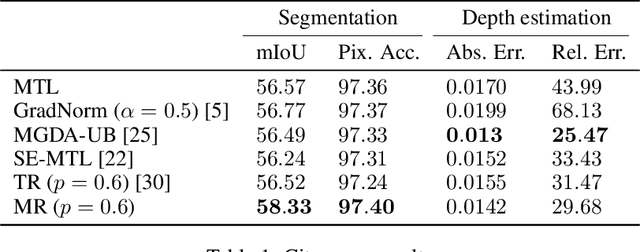
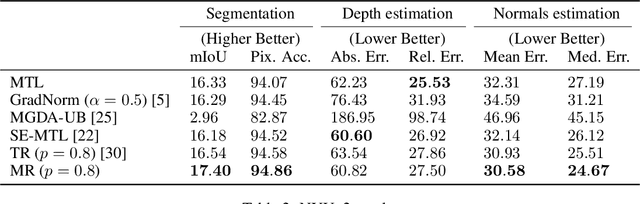
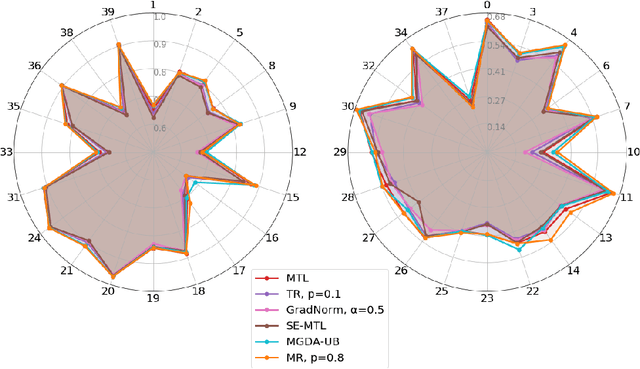
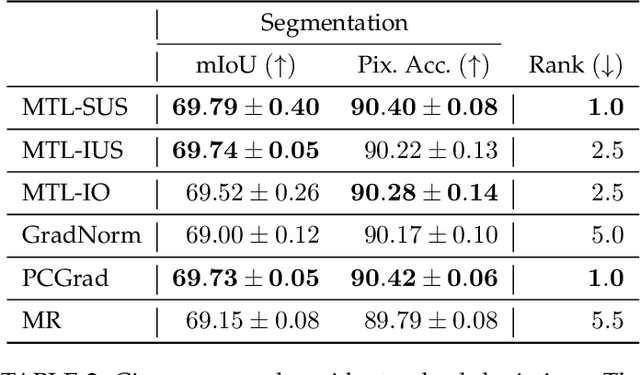
Multi-task learning has gained popularity due to the advantages it provides with respect to resource usage and performance. Nonetheless, the joint optimization of parameters with respect to multiple tasks remains an active research topic. Sub-partitioning the parameters between different tasks has proven to be an efficient way to relax the optimization constraints over the shared weights, may the partitions be disjoint or overlapping. However, one drawback of this approach is that it can weaken the inductive bias generally set up by the joint task optimization. In this work, we present a novel way to partition the parameter space without weakening the inductive bias. Specifically, we propose Maximum Roaming, a method inspired by dropout that randomly varies the parameter partitioning, while forcing them to visit as many tasks as possible at a regulated frequency, so that the network fully adapts to each update. We study the properties of our method through experiments on a variety of visual multi-task data sets. Experimental results suggest that the regularization brought by roaming has more impact on performance than usual partitioning optimization strategies. The overall method is flexible, easily applicable, provides superior regularization and consistently achieves improved performances compared to recent multi-task learning formulations.
The MeMAD Submission to the WMT18 Multimodal Translation Task
Sep 03, 2018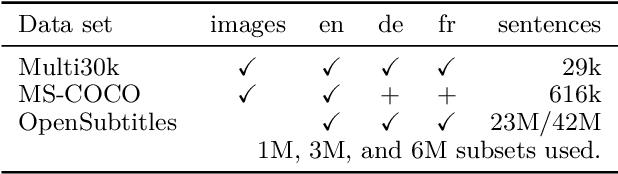
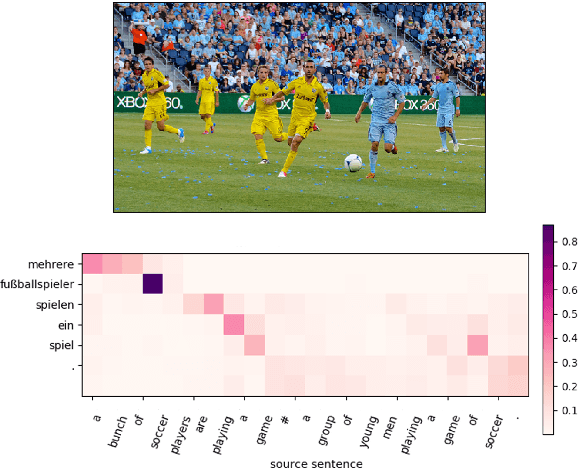
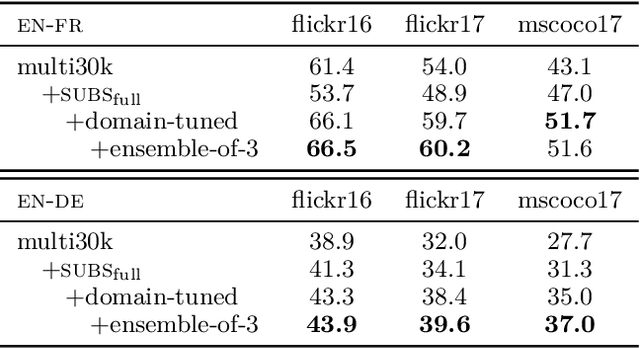

This paper describes the MeMAD project entry to the WMT Multimodal Machine Translation Shared Task. We propose adapting the Transformer neural machine translation (NMT) architecture to a multi-modal setting. In this paper, we also describe the preliminary experiments with text-only translation systems leading us up to this choice. We have the top scoring system for both English-to-German and English-to-French, according to the automatic metrics for flickr18. Our experiments show that the effect of the visual features in our system is small. Our largest gains come from the quality of the underlying text-only NMT system. We find that appropriate use of additional data is effective.