 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Strategies in Multi-Task Learning: Averaged or Independent Losses?
Oct 04, 2021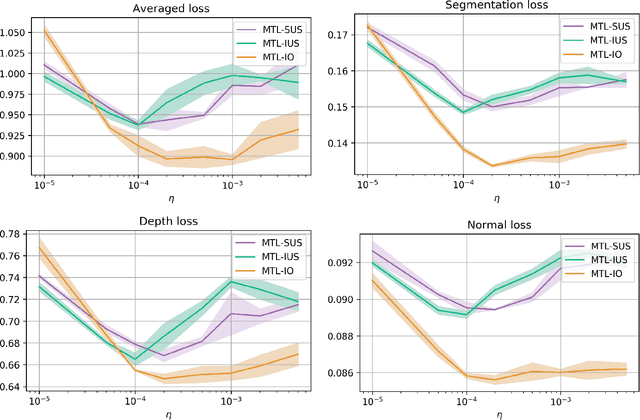
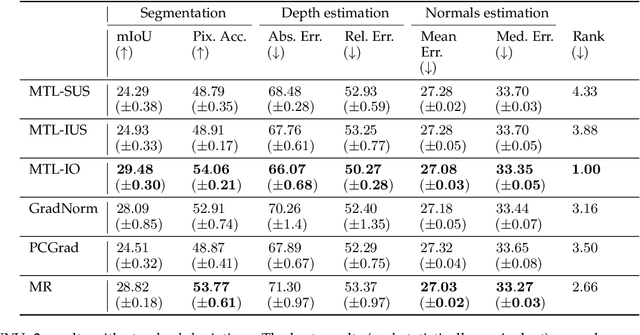
In Multi-Task Learning (MTL), it is a common practice to train multi-task networks by optimizing an objective function, which is a weighted average of the task-specific objective functions. Although the computational advantages of this strategy are clear, the complexity of the resulting loss landscape has not been studied in the literature. Arguably, its optimization may be more difficult than a separate optimization of the constituting task-specific objectives. In this work, we investigate the benefits of such an alternative, by alternating independent gradient descent steps on the different task-specific objective functions and we formulate a novel way to combine this approach with state-of-the-art optimizers. As the separation of task-specific objectives comes at the cost of increased computational time, we propose a random task grouping as a trade-off between better optimization and computational efficiency. Experimental results over three well-known visual MTL datasets show better overall absolute performance on losses and standard metrics compared to an averaged objective function and other state-of-the-art MTL methods. In particular, our method shows the most benefits when dealing with tasks of different nature and it enables a wider exploration of the shared parameter space. We also show that our random grouping strategy allows to trade-off between these benefits and computational efficiency.
Maximum Roaming Multi-Task Learning
Jun 17, 2020
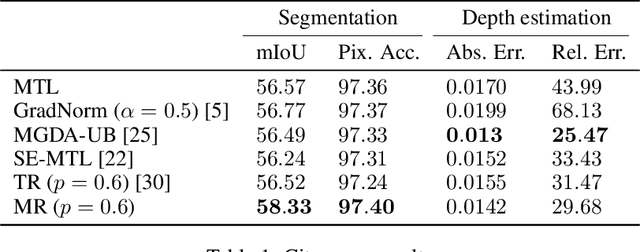
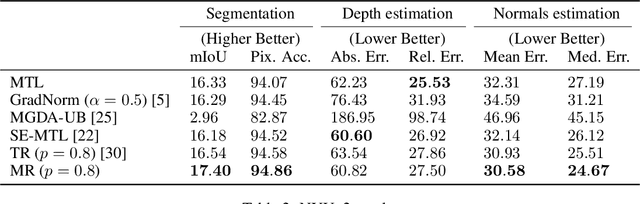
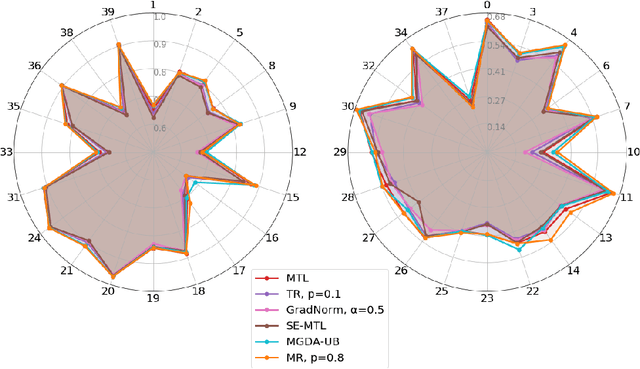
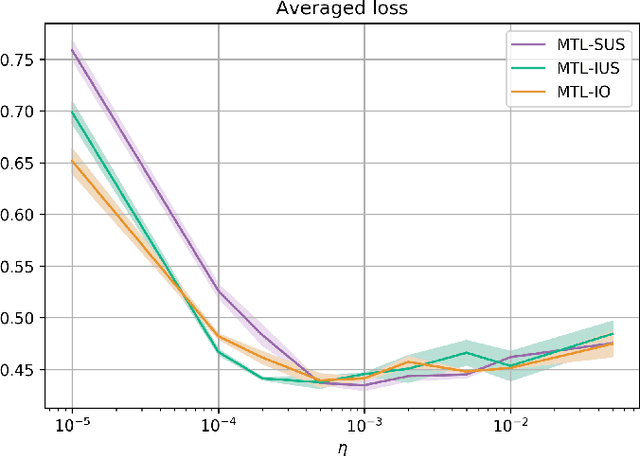
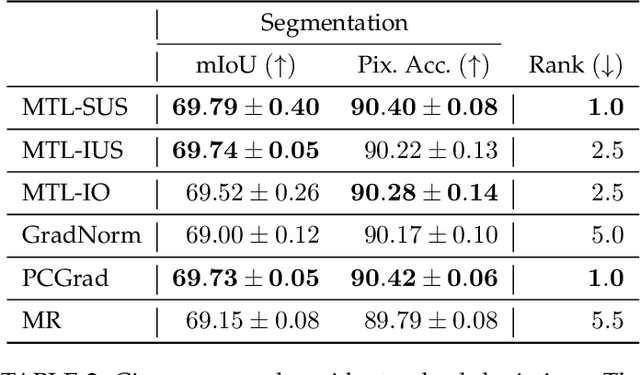
Multi-task learning has gained popularity due to the advantages it provides with respect to resource usage and performance. Nonetheless, the joint optimization of parameters with respect to multiple tasks remains an active research topic. Sub-partitioning the parameters between different tasks has proven to be an efficient way to relax the optimization constraints over the shared weights, may the partitions be disjoint or overlapping. However, one drawback of this approach is that it can weaken the inductive bias generally set up by the joint task optimization. In this work, we present a novel way to partition the parameter space without weakening the inductive bias. Specifically, we propose Maximum Roaming, a method inspired by dropout that randomly varies the parameter partitioning, while forcing them to visit as many tasks as possible at a regulated frequency, so that the network fully adapts to each update. We study the properties of our method through experiments on a variety of visual multi-task data sets. Experimental results suggest that the regularization brought by roaming has more impact on performance than usual partitioning optimization strategies. The overall method is flexible, easily applicable, provides superior regularization and consistently achieves improved performances compared to recent multi-task learning formulations.
Semantic and Visual Similarities for Efficient Knowledge Transfer in CNN Training
Sep 13, 2019
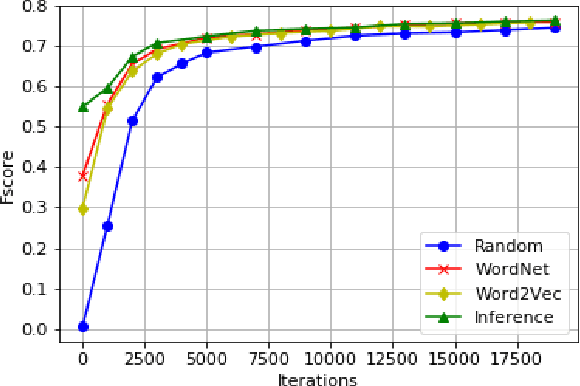
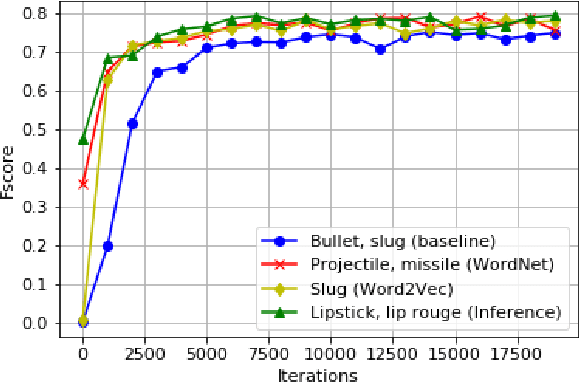
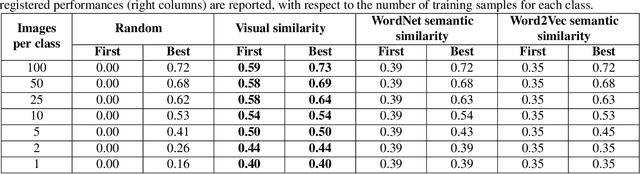
In recent years, representation learning approaches have disrupted many multimedia computing tasks. Among those approaches, deep convolutional neural networks (CNNs) have notably reached human level expertise on some constrained image classification tasks. Nonetheless, training CNNs from scratch for new task or simply new data turns out to be complex and time-consuming. Recently, transfer learning has emerged as an effective methodology for adapting pre-trained CNNs to new data and classes, by only retraining the last classification layer. This paper focuses on improving this process, in order to better transfer knowledge between CNN architectures for faster trainings in the case of fine tuning for image classification. This is achieved by combining and transfering supplementary weights, based on similarity considerations between source and target classes. The study includes a comparison between semantic and content-based similarities, and highlights increased initial performances and training speed, along with superior long term performances when limited training samples are available.