 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Morphomics, Morphological Features on CT scans for lung nodule malignancy diagnosis
Jul 27, 2022
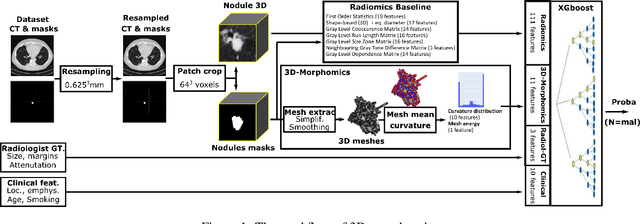
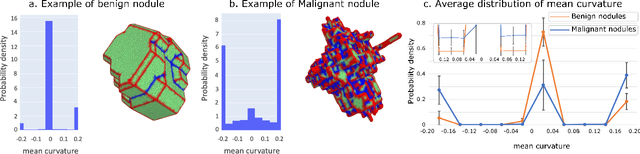
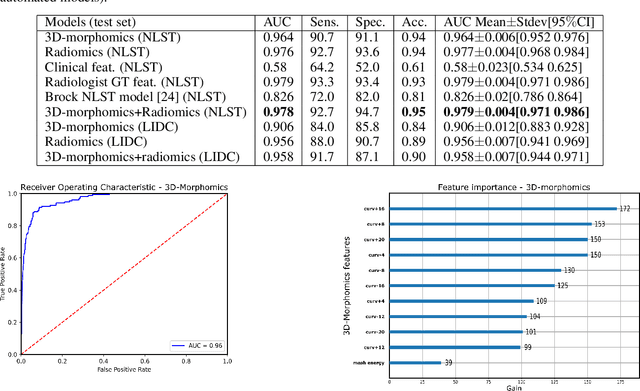
Pathologies systematically induce morphological changes, thus providing a major but yet insufficiently quantified source of observables for diagnosis. The study develops a predictive model of the pathological states based on morphological features (3D-morphomics) on Computed Tomography (CT) volumes. A complete workflow for mesh extraction and simplification of an organ's surface is developed, and coupled with an automatic extraction of morphological features given by the distribution of mean curvature and mesh energy. An XGBoost supervised classifier is then trained and tested on the 3D-morphomics to predict the pathological states. This framework is applied to the prediction of the malignancy of lung's nodules. On a subset of NLST database with malignancy confirmed biopsy, using 3D-morphomics only, the classification model of lung nodules into malignant vs. benign achieves 0.964 of AUC. Three other sets of classical features are trained and tested, (1) clinical relevant features gives an AUC of 0.58, (2) 111 radiomics gives an AUC of 0.976, (3) radiologist ground truth (GT) containing the nodule size, attenuation and spiculation qualitative annotations gives an AUC of 0.979. We also test the Brock model and obtain an AUC of 0.826. Combining 3D-morphomics and radiomics features achieves state-of-the-art results with an AUC of 0.978 where the 3D-morphomics have some of the highest predictive powers. As a validation on a public independent cohort, models are applied to the LIDC dataset, the 3D-morphomics achieves an AUC of 0.906 and the 3D-morphomics+radiomics achieves an AUC of 0.958, which ranks second in the challenge among deep models. It establishes the curvature distributions as efficient features for predicting lung nodule malignancy and a new method that can be applied directly to arbitrary computer aided diagnosis task.
Built Year Prediction from Buddha Face with Heterogeneous Labels
Sep 02, 2021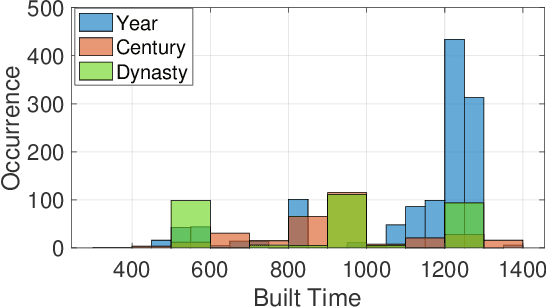
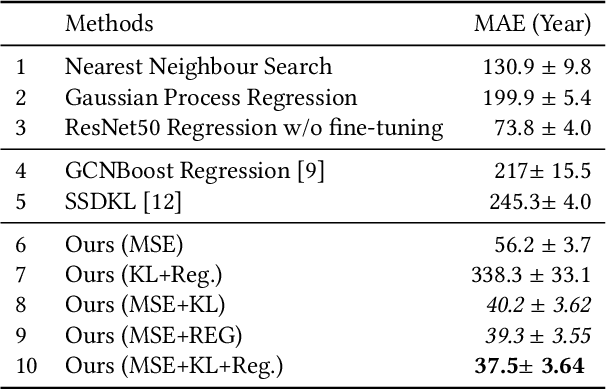

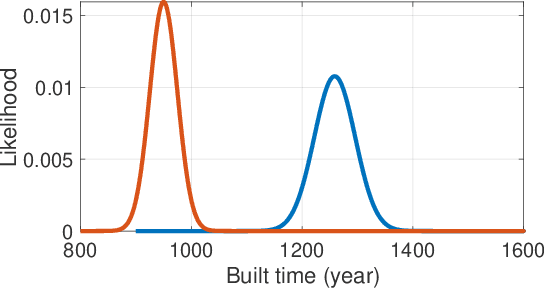
Buddha statues are a part of human culture, especially of the Asia area, and they have been alongside human civilisation for more than 2,000 years. As history goes by, due to wars, natural disasters, and other reasons, the records that show the built years of Buddha statues went missing, which makes it an immense work for historians to estimate the built years. In this paper, we pursue the idea of building a neural network model that automatically estimates the built years of Buddha statues based only on their face images. Our model uses a loss function that consists of three terms: an MSE loss that provides the basis for built year estimation; a KL divergence-based loss that handles the samples with both an exact built year and a possible range of built years (e.g., dynasty or centuries) estimated by historians; finally a regularisation that utilises both labelled and unlabelled samples based on manifold assumption. By combining those three terms in the training process, we show that our method is able to estimate built years for given images with 37.5 years of a mean absolute error on the test set.
GCNBoost: Artwork Classification by Label Propagation through a Knowledge Graph
May 25, 2021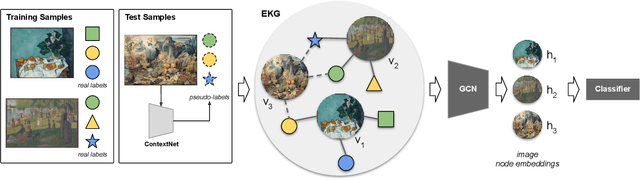
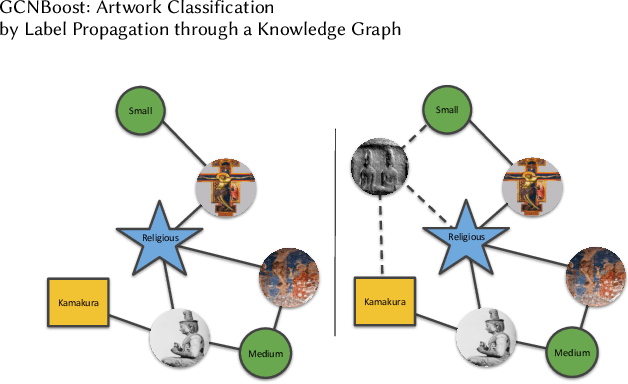
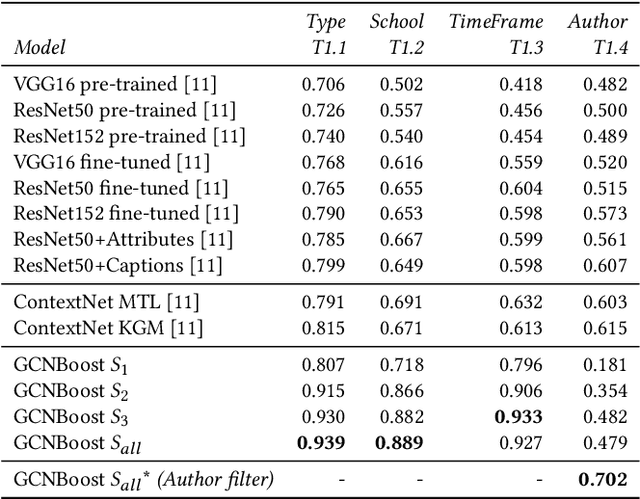
The rise of digitization of cultural documents offers large-scale contents, opening the road for development of AI systems in order to preserve, search, and deliver cultural heritage. To organize such cultural content also means to classify them, a task that is very familiar to modern computer science. Contextual information is often the key to structure such real world data, and we propose to use it in form of a knowledge graph. Such a knowledge graph, combined with content analysis, enhances the notion of proximity between artworks so it improves the performances in classification tasks. In this paper, we propose a novel use of a knowledge graph, that is constructed on annotated data and pseudo-labeled data. With label propagation, we boost artwork classification by training a model using a graph convolutional network, relying on the relationships between entities of the knowledge graph. Following a transductive learning framework, our experiments show that relying on a knowledge graph modeling the relations between labeled data and unlabeled data allows to achieve state-of-the-art results on multiple classification tasks on a dataset of paintings, and on a dataset of Buddha statues. Additionally, we show state-of-the-art results for the difficult case of dealing with unbalanced data, with the limitation of disregarding classes with extremely low degrees in the knowledge graph.
Movienet: A Movie Multilayer Network Model using Visual and Textual Semantic Cues
Oct 18, 2019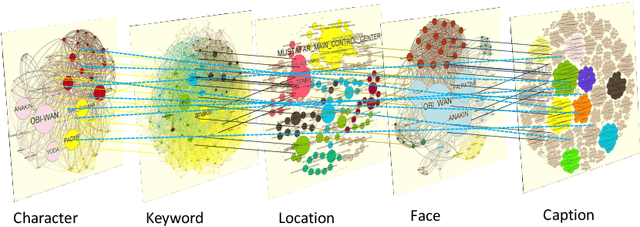
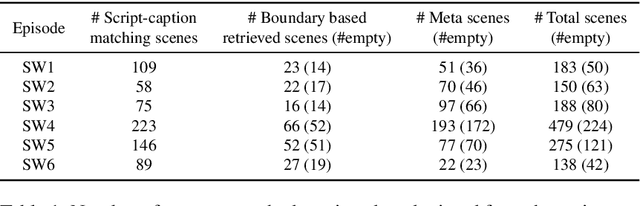
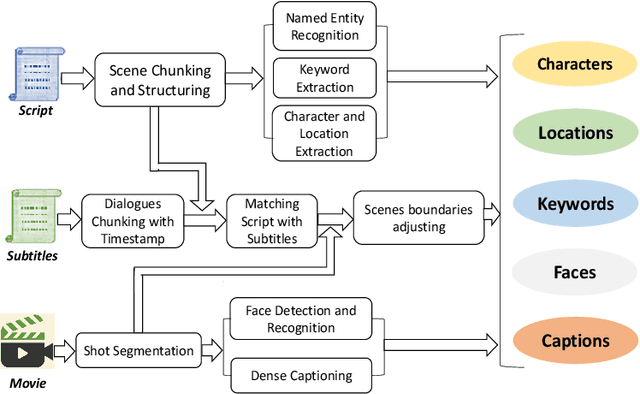
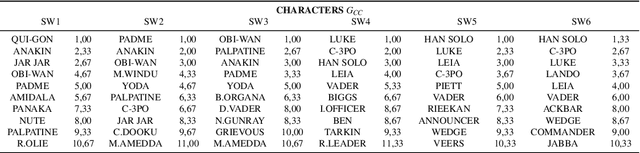
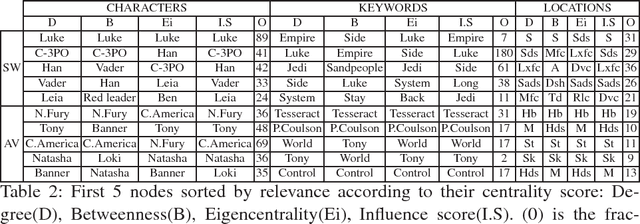
Discovering content and stories in movies is one of the most important concepts in multimedia content research studies. Network models have proven to be an efficient choice for this purpose. When an audience watches a movie, they usually compare the characters and the relationships between them. For this reason, most of the models developed so far are based on social networks analysis. They focus essentially on the characters at play. By analyzing characters' interactions, we can obtain a broad picture of the narration's content. Other works have proposed to exploit semantic elements such as scenes, dialogues, etc. However, they are always captured from a single facet. Motivated by these limitations, we introduce in this work a multilayer network model to capture the narration of a movie based on its script, its subtitles, and the movie content. After introducing the model and the extraction process from the raw data, we perform a comparative analysis of the whole 6-movie cycle of the Star Wars saga. Results demonstrate the effectiveness of the proposed framework for video content representation and analysis.
Historical and Modern Features for Buddha Statue Classification
Oct 06, 2019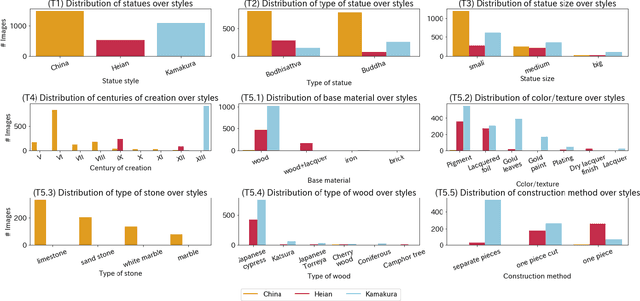
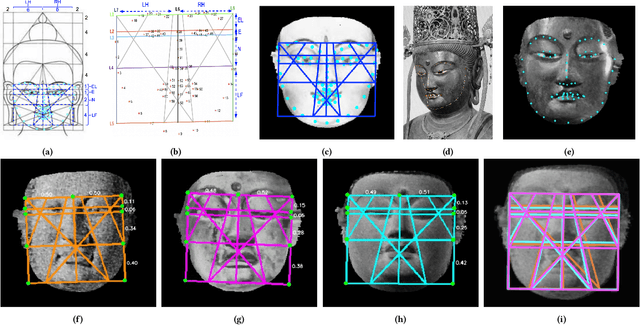

While Buddhism has spread along the Silk Roads, many pieces of art have been displaced. Only a few experts may identify these works, subjectively to their experience. The construction of Buddha statues was taught through the definition of canon rules, but the applications of those rules greatly varies across time and space. Automatic art analysis aims at supporting these challenges. We propose to automatically recover the proportions induced by the construction guidelines, in order to use them and compare between different deep learning features for several classification tasks, in a medium size but rich dataset of Buddha statues, collected with experts of Buddhism art history.
BUDA.ART: A Multimodal Content-Based Analysis and Retrieval System for Buddha Statues
Sep 17, 2019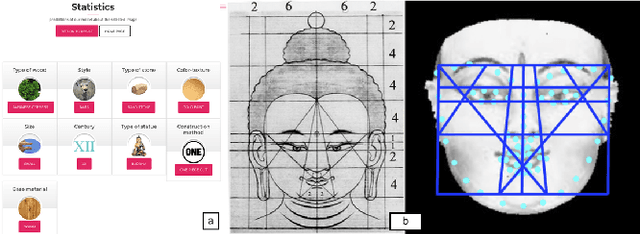
We introduce BUDA.ART, a system designed to assist researchers in Art History, to explore and analyze an archive of pictures of Buddha statues. The system combines different CBIR and classical retrieval techniques to assemble 2D pictures, 3D statue scans and meta-data, that is focused on the Buddha facial characteristics. We build the system from an archive of 50,000 Buddhism pictures, identify unique Buddha statues, extract contextual information, and provide specific facial embedding to first index the archive. The system allows for mobile, on-site search, and to explore similarities of statues in the archive. In addition, we provide search visualization and 3D analysis of the statues
Understanding Art through Multi-Modal Retrieval in Paintings
Apr 24, 2019

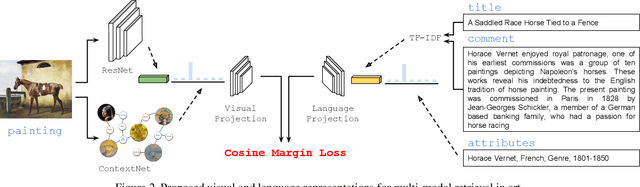
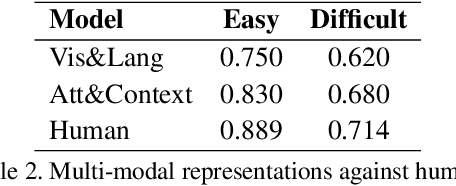
In computer vision, visual arts are often studied from a purely aesthetics perspective, mostly by analysing the visual appearance of an artistic reproduction to infer its style, its author, or its representative features. In this work, however, we explore art from both a visual and a language perspective. Our aim is to bridge the gap between the visual appearance of an artwork and its underlying meaning, by jointly analysing its aesthetics and its semantics. We introduce the use of multi-modal techniques in the field of automatic art analysis by 1) collecting a multi-modal dataset with fine-art paintings and comments, and 2) exploring robust visual and textual representations in artistic images.
Context-Aware Embeddings for Automatic Art Analysis
Apr 10, 2019

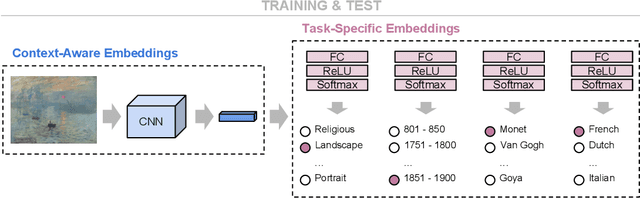
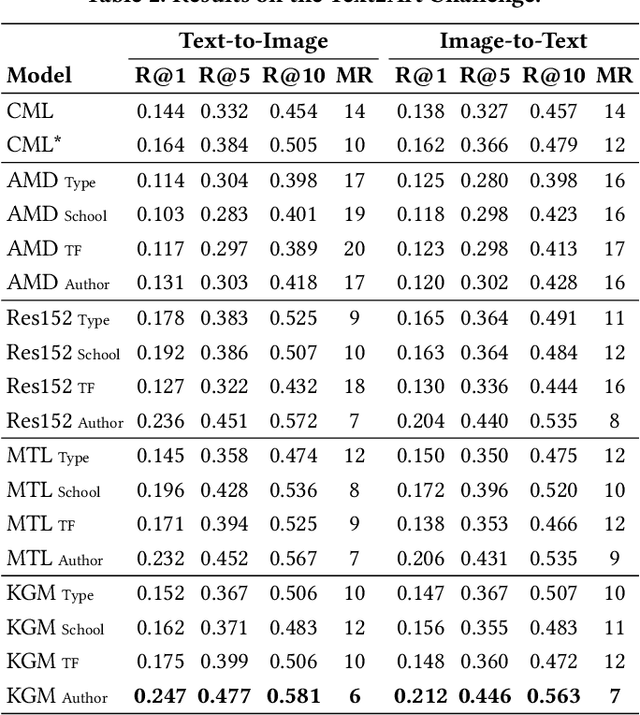
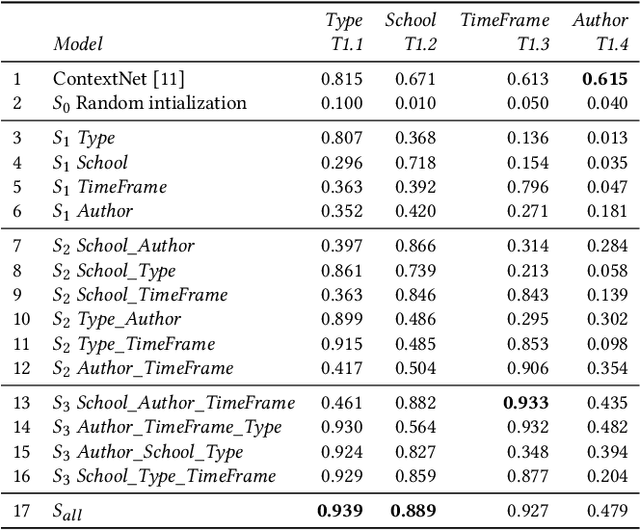
Automatic art analysis aims to classify and retrieve artistic representations from a collection of images by using computer vision and machine learning techniques. In this work, we propose to enhance visual representations from neural networks with contextual artistic information. Whereas visual representations are able to capture information about the content and the style of an artwork, our proposed context-aware embeddings additionally encode relationships between different artistic attributes, such as author, school, or historical period. We design two different approaches for using context in automatic art analysis. In the first one, contextual data is obtained through a multi-task learning model, in which several attributes are trained together to find visual relationships between elements. In the second approach, context is obtained through an art-specific knowledge graph, which encodes relationships between artistic attributes. An exhaustive evaluation of both of our models in several art analysis problems, such as author identification, type classification, or cross-modal retrieval, show that performance is improved by up to 7.3% in art classification and 37.24% in retrieval when context-aware embeddings are used.
Multilayer Network Model of Movie Script
Dec 13, 2018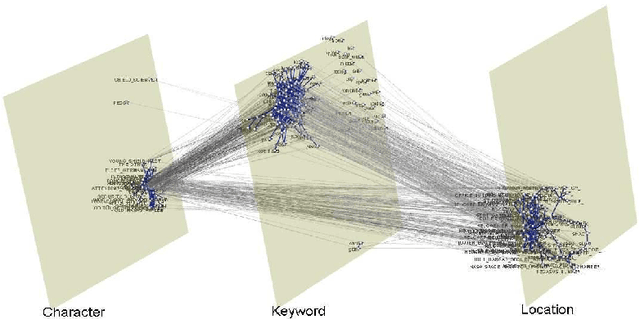
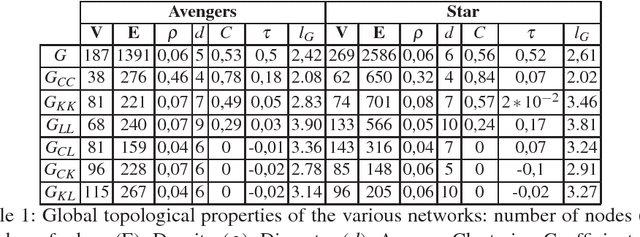
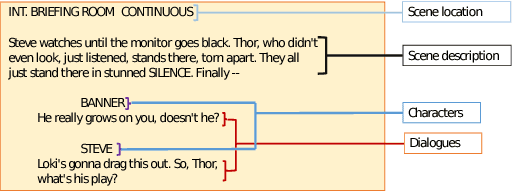
Network models have been increasingly used in the past years to support summarization and analysis of narratives, such as famous TV series, books and news. Inspired by social network analysis, most of these models focus on the characters at play. The network model well captures all characters interactions, giving a broad picture of the narration's content. A few works went beyond by introducing additional semantic elements, always captured in a single layer network. In contrast, we introduce in this work a multilayer network model to capture more elements of the narration of a movie from its script: people, locations, and other semantic elements. This model enables new measures and insights on movies. We demonstrate this model on two very popular movies.