 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Quality Assessment Using the Perceptual Clustering Weighted Graph (PCW-Graph) and Attention Fusion Network
Jun 04, 2025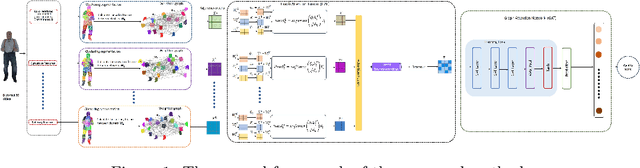



No-Reference Point Cloud Quality Assessment (NR-PCQA) is critical for evaluating 3D content in real-world applications where reference models are unavailable.
Segmentation and ABCD rule extraction for skin tumors classification
Jun 08, 2021
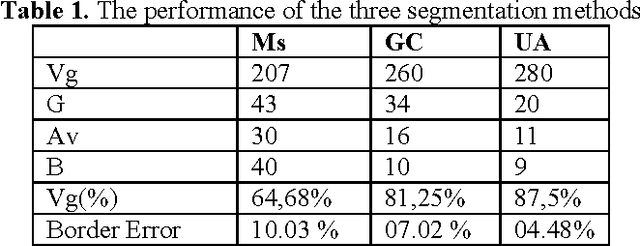

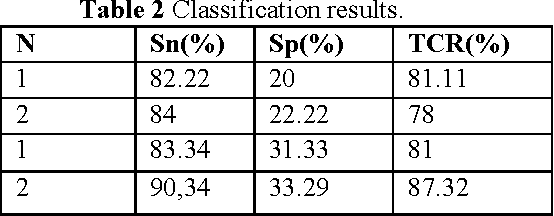
During the last years, computer vision-based diagnosis systems have been widely used in several hospitals and dermatology clinics, aiming at the early detection of malignant melanoma tumor, which is among the most frequent types of skin cancer. In this work, we present an automated diagnosis system based on the ABCD rule used in clinical diagnosis in order to discriminate benign from malignant skin lesions. First, to reduce the influence of small structures, a preprocessing step based on morphological and fast marching schemes is used. In the second step, an unsupervised approach for lesion segmentation is proposed. Iterative thresholding is applied to initialize level set automatically. As the detection of an automated border is an important step for the correctness of subsequent phases in the computerized melanoma recognition systems, we compare its accuracy with growcut and mean shift algorithms, and discuss how these results may influence in the following steps: the feature extraction and the final lesion classification. Relying on visual diagnosis four features: Asymmetry (A), Border (B), Color (C) and Diversity (D) are computed and used to construct a classification module based on artificial neural network for the recognition of malignant melanoma. This framework has been tested on a dermoscopic database [16] of 320 images. The classification results show an increasing true detection rate and a decreasing false positive rate.
A blind Robust Image Watermarking Approach exploiting the DFT Magnitude
Oct 22, 2019
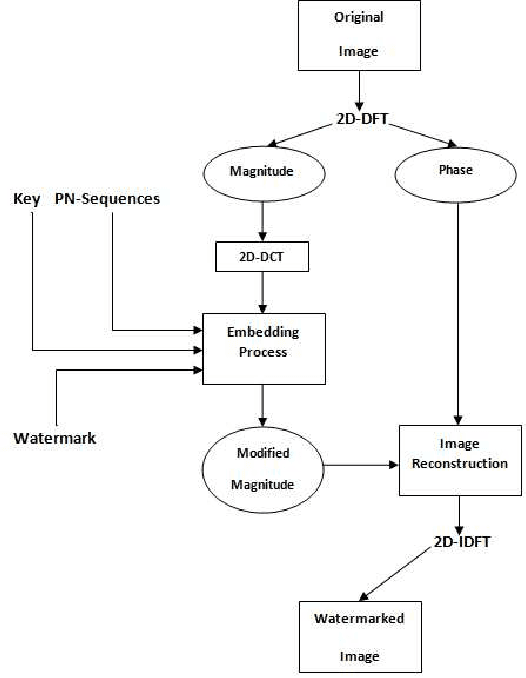
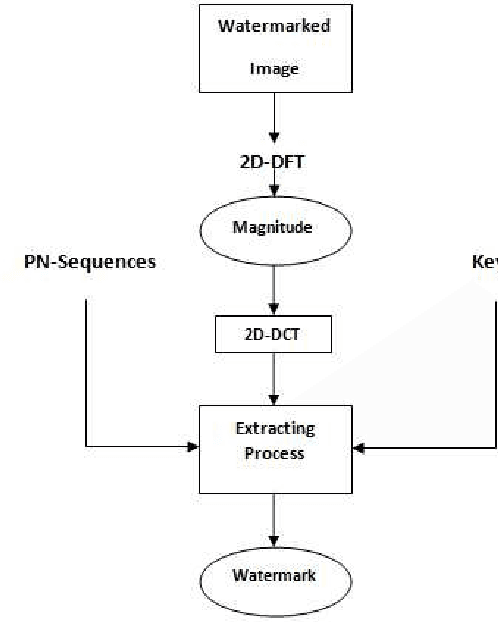

Due to the current progress in Internet, digital contents (video, audio and images) are widely used. Distribution of multimedia contents is now faster and it allows for easy unauthorized reproduction of information. Digital watermarking came up while trying to solve this problem. Its main idea is to embed a watermark into a host digital content without affecting its quality. Moreover, watermarking can be used in several applications such as authentication, copy control, indexation, Copyright protection, etc. In this paper, we propose a blind robust image watermarking approach as a solution to the problem of copyright protection of digital images. The underlying concept of our method is to apply a discrete cosine transform (DCT) to the magnitude resulting from a discrete Fourier transform (DFT) applied to the original image. Then, the watermark is embedded by modifying the coefficients of the DCT using a secret key to increase security. Experimental results show the robustness of the proposed technique to a wide range of common attacks, e.g., Low-Pass Gaussian Filtering, JPEG compression, Gaussian noise, salt & pepper noise, Gaussian Smoothing and Histogram equalization. The proposed method achieves a Peak signal-to-noise-ration (PSNR) value greater than 66 (dB) and ensures a perfect watermark extraction.
Movienet: A Movie Multilayer Network Model using Visual and Textual Semantic Cues
Oct 18, 2019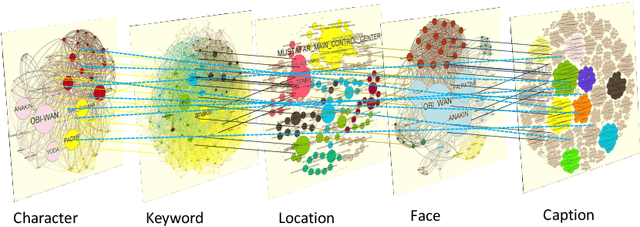
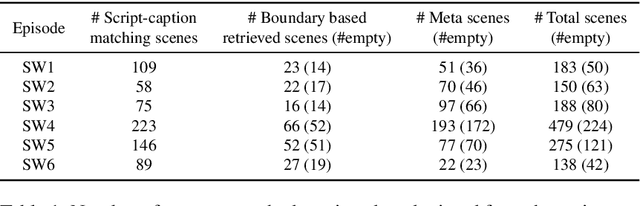
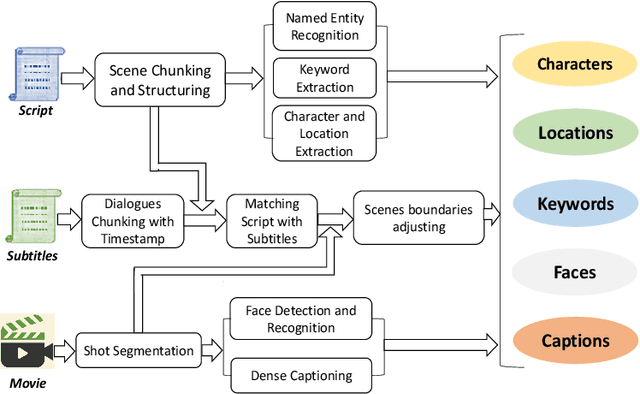
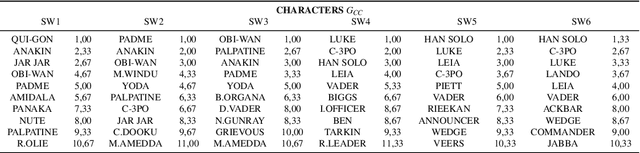
Discovering content and stories in movies is one of the most important concepts in multimedia content research studies. Network models have proven to be an efficient choice for this purpose. When an audience watches a movie, they usually compare the characters and the relationships between them. For this reason, most of the models developed so far are based on social networks analysis. They focus essentially on the characters at play. By analyzing characters' interactions, we can obtain a broad picture of the narration's content. Other works have proposed to exploit semantic elements such as scenes, dialogues, etc. However, they are always captured from a single facet. Motivated by these limitations, we introduce in this work a multilayer network model to capture the narration of a movie based on its script, its subtitles, and the movie content. After introducing the model and the extraction process from the raw data, we perform a comparative analysis of the whole 6-movie cycle of the Star Wars saga. Results demonstrate the effectiveness of the proposed framework for video content representation and analysis.
A General Framework for Complex Network-Based Image Segmentation
Jul 04, 2019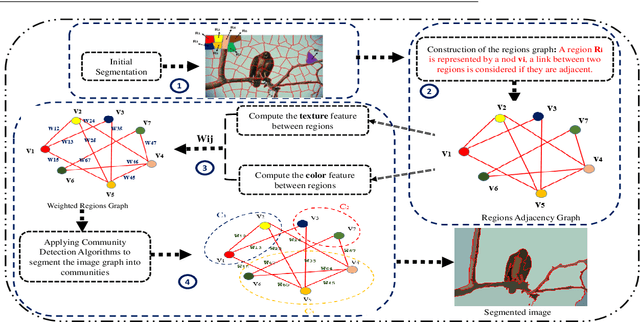

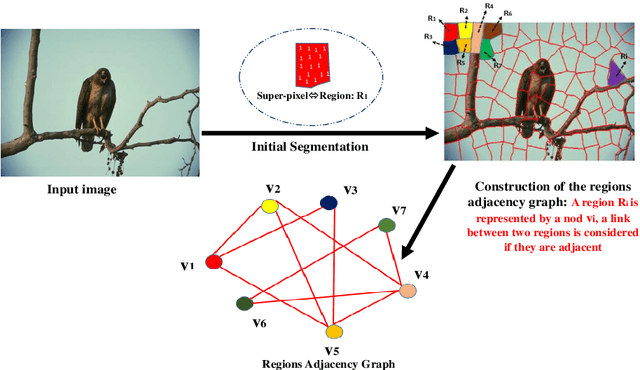

With the recent advances in complex networks theory, graph-based techniques for image segmentation has attracted great attention recently. In order to segment the image into meaningful connected components, this paper proposes an image segmentation general framework using complex networks based community detection algorithms. If we consider regions as communities, using community detection algorithms directly can lead to an over-segmented image. To address this problem, we start by splitting the image into small regions using an initial segmentation. The obtained regions are used for building the complex network. To produce meaningful connected components and detect homogeneous communities, some combinations of color and texture based features are employed in order to quantify the regions similarities. To sum up, the network of regions is constructed adaptively to avoid many small regions in the image, and then, community detection algorithms are applied on the resulting adaptive similarity matrix to obtain the final segmented image. Experiments are conducted on Berkeley Segmentation Dataset and four of the most influential community detection algorithms are tested. Experimental results have shown that the proposed general framework increases the segmentation performances compared to some existing methods.
Multilayer Network Model of Movie Script
Dec 13, 2018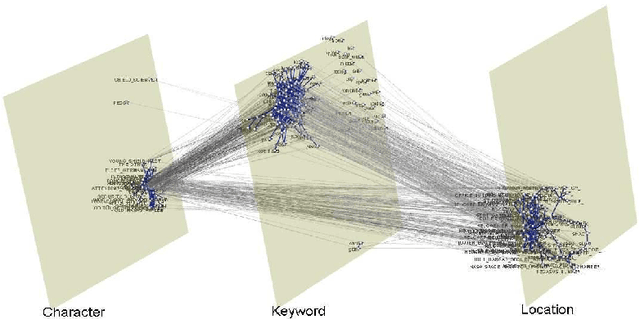
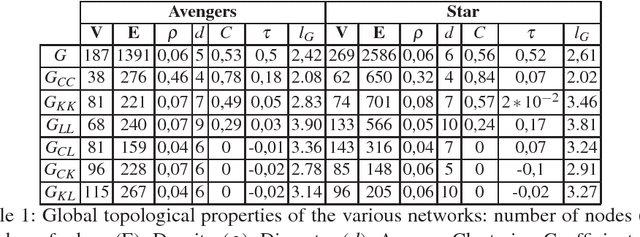
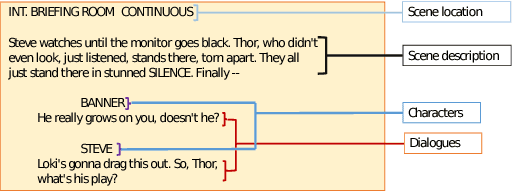
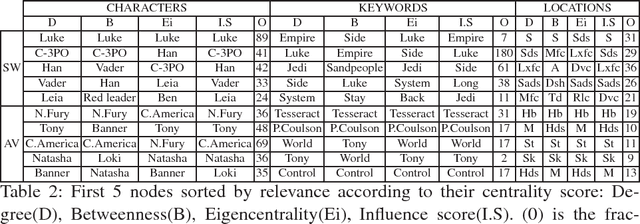
Network models have been increasingly used in the past years to support summarization and analysis of narratives, such as famous TV series, books and news. Inspired by social network analysis, most of these models focus on the characters at play. The network model well captures all characters interactions, giving a broad picture of the narration's content. A few works went beyond by introducing additional semantic elements, always captured in a single layer network. In contrast, we introduce in this work a multilayer network model to capture more elements of the narration of a movie from its script: people, locations, and other semantic elements. This model enables new measures and insights on movies. We demonstrate this model on two very popular movies.
Image quality assessment measure based on natural image statistics in the Tetrolet domain
Dec 08, 2014
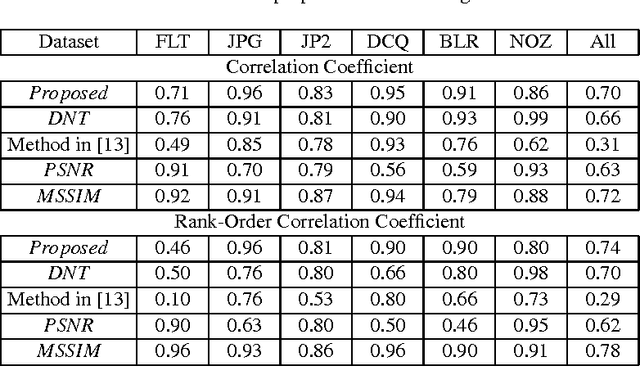

This paper deals with a reduced reference (RR) image quality measure based on natural image statistics modeling. For this purpose, Tetrolet transform is used since it provides a convenient way to capture local geometric structures. This transform is applied to both reference and distorted images. Then, Gaussian Scale Mixture (GSM) is proposed to model subbands in order to take account statistical dependencies between tetrolet coefficients. In order to quantify the visual degradation, a measure based on Kullback Leibler Divergence (KLD) is provided. The proposed measure was tested on the Cornell VCL A-57 dataset and compared with other measures according to FR-TV1 VQEG framework.
Color image quality assessment measure using multivariate generalized Gaussian distribution
Nov 29, 2014
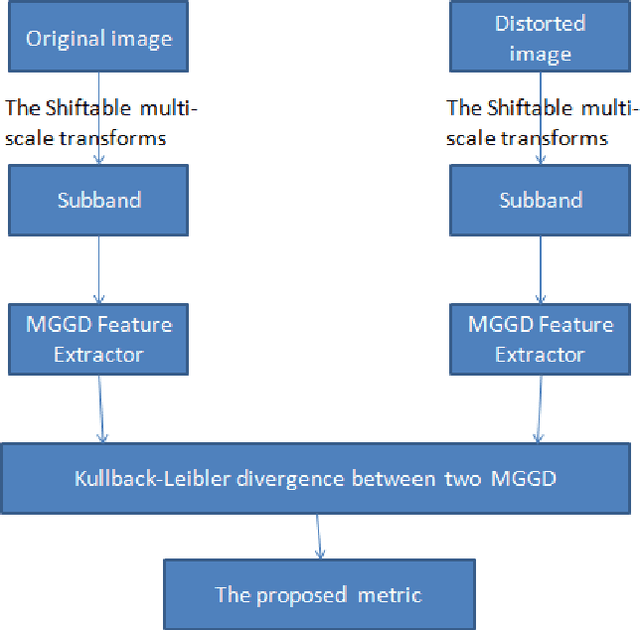

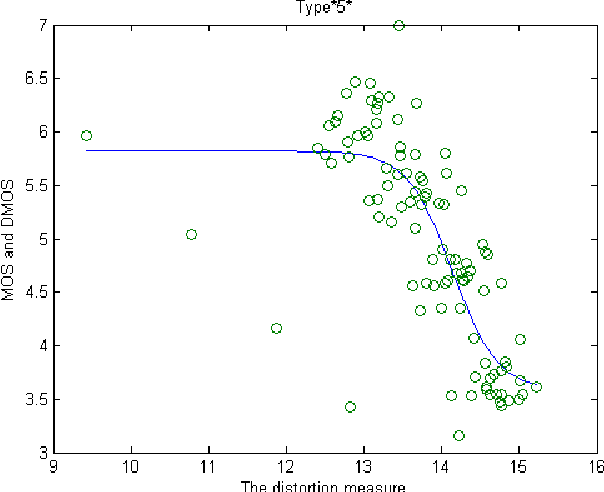
This paper deals with color image quality assessment in the reduced-reference framework based on natural scenes statistics. In this context, we propose to model the statistics of the steerable pyramid coefficients by a Multivariate Generalized Gaussian distribution (MGGD). This model allows taking into account the high correlation between the components of the RGB color space. For each selected scale and orientation, we extract a parameter matrix from the three color components subbands. In order to quantify the visual degradation, we use a closed-form of Kullback-Leibler Divergence (KLD) between two MGGDs. Using "TID 2008" benchmark, the proposed measure has been compared with the most influential methods according to the FRTV1 VQEG framework. Results demonstrates its effectiveness for a great variety of distortion type. Among other benefits this measure uses only very little information about the original image.
On color image quality assessment using natural image statistics
Nov 27, 2014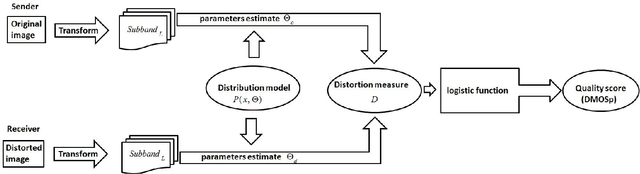


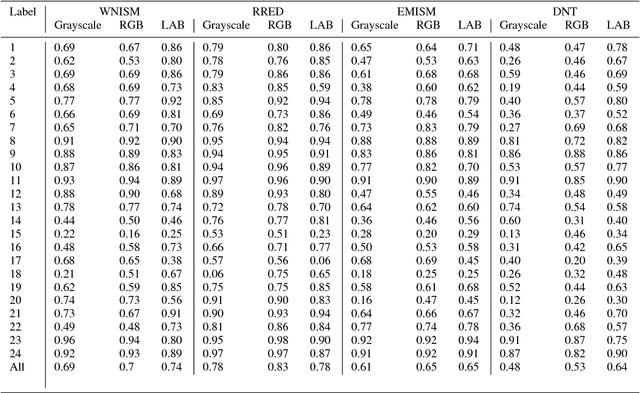
Color distortion can introduce a significant damage in visual quality perception, however, most of existing reduced-reference quality measures are designed for grayscale images. In this paper, we consider a basic extension of well-known image-statistics based quality assessment measures to color images. In order to evaluate the impact of color information on the measures efficiency, two color spaces are investigated: RGB and CIELAB. Results of an extensive evaluation using TID 2013 benchmark demonstrates that significant improvement can be achieved for a great number of distortion type when the CIELAB color representation is used.
A statistical reduced-reference method for color image quality assessment
Nov 27, 2014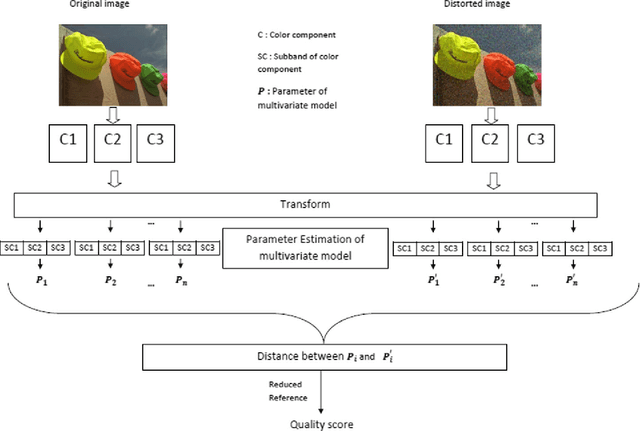

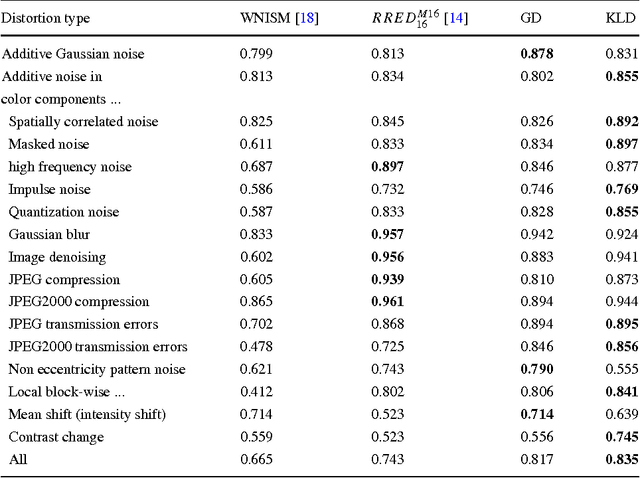
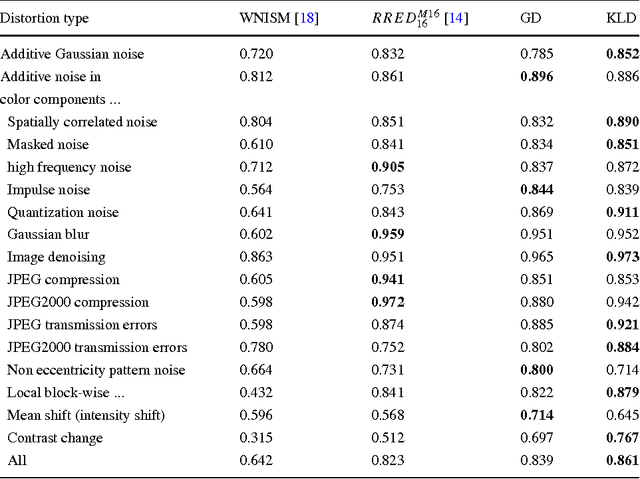
Although color is a fundamental feature of human visual perception, it has been largely unexplored in the reduced-reference (RR) image quality assessment (IQA) schemes. In this paper, we propose a natural scene statistic (NSS) method, which efficiently uses this information. It is based on the statistical deviation between the steerable pyramid coefficients of the reference color image and the degraded one. We propose and analyze the multivariate generalized Gaussian distribution (MGGD) to model the underlying statistics. In order to quantify the degradation, we develop and evaluate two measures based respectively on the Geodesic distance between two MGGDs and on the closed-form of the Kullback Leibler divergence. We performed an extensive evaluation of both metrics in various color spaces (RGB, HSV, CIELAB and YCrCb) using the TID 2008 benchmark and the FRTV Phase I validation process. Experimental results demonstrate the effectiveness of the proposed framework to achieve a good consistency with human visual perception. Furthermore, the best configuration is obtained with CIELAB color space associated to KLD deviation measure.