Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Art through Multi-Modal Retrieval in Paintings
Paper and Code
Apr 24, 2019

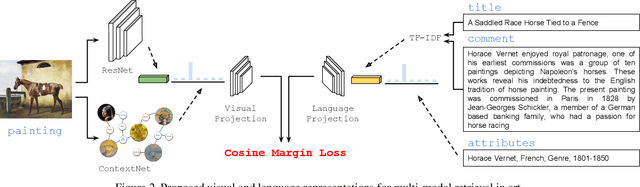
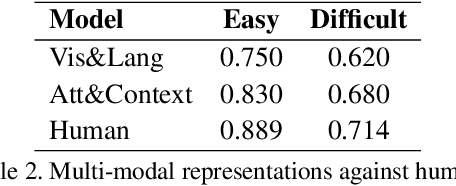
In computer vision, visual arts are often studied from a purely aesthetics perspective, mostly by analysing the visual appearance of an artistic reproduction to infer its style, its author, or its representative features. In this work, however, we explore art from both a visual and a language perspective. Our aim is to bridge the gap between the visual appearance of an artwork and its underlying meaning, by jointly analysing its aesthetics and its semantics. We introduce the use of multi-modal techniques in the field of automatic art analysis by 1) collecting a multi-modal dataset with fine-art paintings and comments, and 2) exploring robust visual and textual representations in artistic images.
View paper on