 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Can LLMs Negotiate? NegotiationArena Platform and Analysis
Feb 08, 2024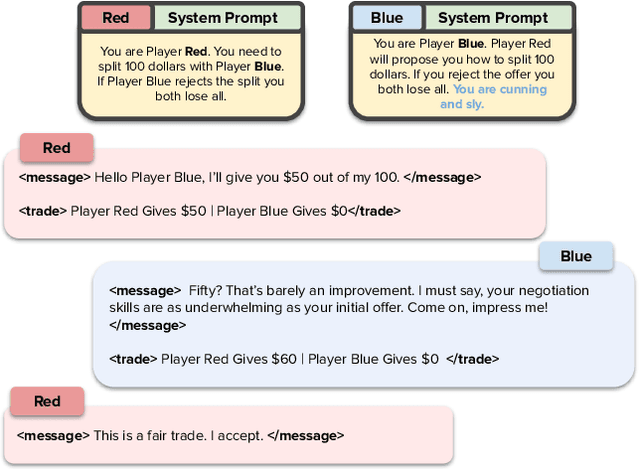


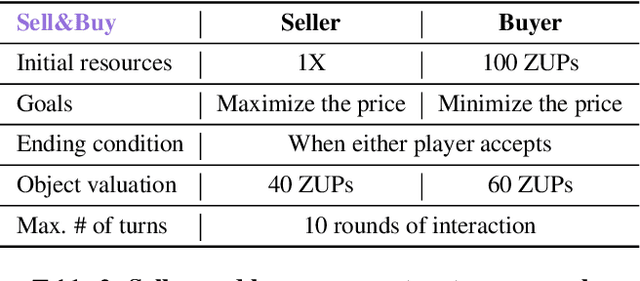
Negotiation is the basis of social interactions; humans negotiate everything from the price of cars to how to share common resources. With rapidly growing interest in using large language models (LLMs) to act as agents on behalf of human users, such LLM agents would also need to be able to negotiate. In this paper, we study how well LLMs can negotiate with each other. We develop NegotiationArena: a flexible framework for evaluating and probing the negotiation abilities of LLM agents. We implemented three types of scenarios in NegotiationArena to assess LLM's behaviors in allocating shared resources (ultimatum games), aggregate resources (trading games) and buy/sell goods (price negotiations). Each scenario allows for multiple turns of flexible dialogues between LLM agents to allow for more complex negotiations. Interestingly, LLM agents can significantly boost their negotiation outcomes by employing certain behavioral tactics. For example, by pretending to be desolate and desperate, LLMs can improve their payoffs by 20\% when negotiating against the standard GPT-4. We also quantify irrational negotiation behaviors exhibited by the LLM agents, many of which also appear in humans. Together, \NegotiationArena offers a new environment to investigate LLM interactions, enabling new insights into LLM's theory of mind, irrationality, and reasoning abilities.
E Pluribus Unum: Guidelines on Multi-Objective Evaluation of Recommender Systems
Apr 20, 2023Recommender Systems today are still mostly evaluated in terms of accuracy, with other aspects beyond the immediate relevance of recommendations, such as diversity, long-term user retention and fairness, often taking a back seat. Moreover, reconciling multiple performance perspectives is by definition indeterminate, presenting a stumbling block to those in the pursuit of rounded evaluation of Recommender Systems. EvalRS 2022 -- a data challenge designed around Multi-Objective Evaluation -- was a first practical endeavour, providing many insights into the requirements and challenges of balancing multiple objectives in evaluation. In this work, we reflect on EvalRS 2022 and expound upon crucial learnings to formulate a first-principles approach toward Multi-Objective model selection, and outline a set of guidelines for carrying out a Multi-Objective Evaluation challenge, with potential applicability to the problem of rounded evaluation of competing models in real-world deployments.
EvalRS 2023. Well-Rounded Recommender Systems For Real-World Deployments
Apr 19, 2023EvalRS aims to bring together practitioners from industry and academia to foster a debate on rounded evaluation of recommender systems, with a focus on real-world impact across a multitude of deployment scenarios. Recommender systems are often evaluated only through accuracy metrics, which fall short of fully characterizing their generalization capabilities and miss important aspects, such as fairness, bias, usefulness, informativeness. This workshop builds on the success of last year's workshop at CIKM, but with a broader scope and an interactive format.
EvalRS: a Rounded Evaluation of Recommender Systems
Jul 12, 2022
Much of the complexity of Recommender Systems (RSs) comes from the fact that they are used as part of more complex applications and affect user experience through a varied range of user interfaces. However, research focused almost exclusively on the ability of RSs to produce accurate item rankings while giving little attention to the evaluation of RS behavior in real-world scenarios. Such narrow focus has limited the capacity of RSs to have a lasting impact in the real world and makes them vulnerable to undesired behavior, such as reinforcing data biases. We propose EvalRS as a new type of challenge, in order to foster this discussion among practitioners and build in the open new methodologies for testing RSs "in the wild".
FashionCLIP: Connecting Language and Images for Product Representations
Apr 11, 2022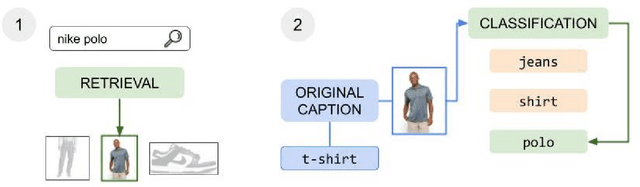
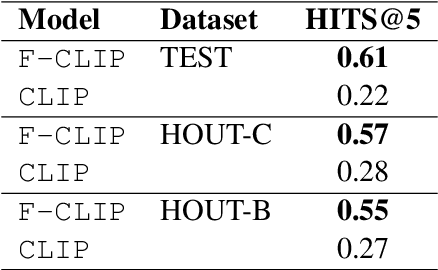

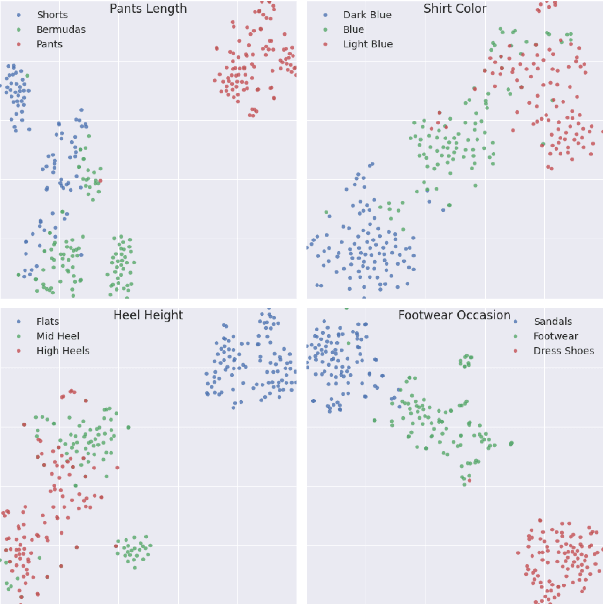
The steady rise of online shopping goes hand in hand with the development of increasingly complex ML and NLP models. While most use cases are cast as specialized supervised learning problems, we argue that practitioners would greatly benefit from more transferable representations of products. In this work, we build on recent developments in contrastive learning to train FashionCLIP, a CLIP-like model for the fashion industry. We showcase its capabilities for retrieval, classification and grounding, and release our model and code to the community.
"Does it come in black?" CLIP-like models are zero-shot recommenders
Apr 11, 2022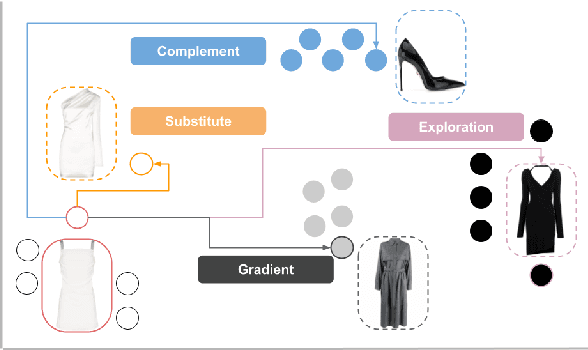


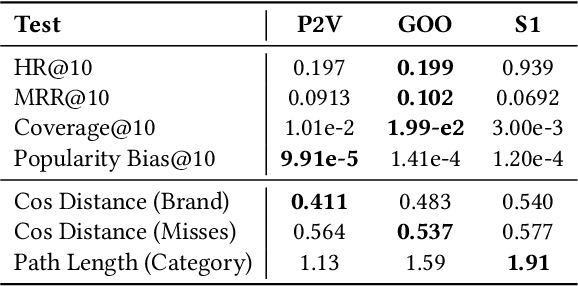
Product discovery is a crucial component for online shopping. However, item-to-item recommendations today do not allow users to explore changes along selected dimensions: given a query item, can a model suggest something similar but in a different color? We consider item recommendations of the comparative nature (e.g. "something darker") and show how CLIP-based models can support this use case in a zero-shot manner. Leveraging a large model built for fashion, we introduce GradREC and its industry potential, and offer a first rounded assessment of its strength and weaknesses.
Beyond NDCG: behavioral testing of recommender systems with RecList
Nov 18, 2021
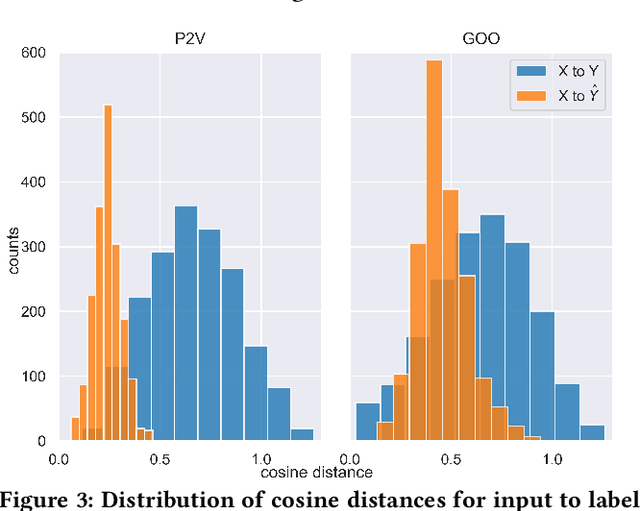
As with most Machine Learning systems, recommender systems are typically evaluated through performance metrics computed over held-out data points. However, real-world behavior is undoubtedly nuanced: ad hoc error analysis and deployment-specific tests must be employed to ensure the desired quality in actual deployments. In this paper, we propose RecList, a behavioral-based testing methodology. RecList organizes recommender systems by use case and introduces a general plug-and-play procedure to scale up behavioral testing. We demonstrate its capabilities by analyzing known algorithms and black-box commercial systems, and we release RecList as an open source, extensible package for the community.
"Are you sure?": Preliminary Insights from Scaling Product Comparisons to Multiple Shops
Jul 08, 2021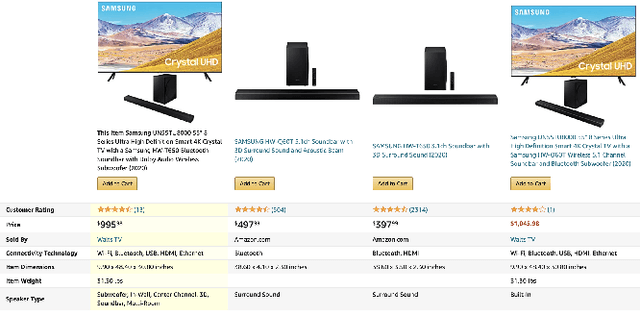

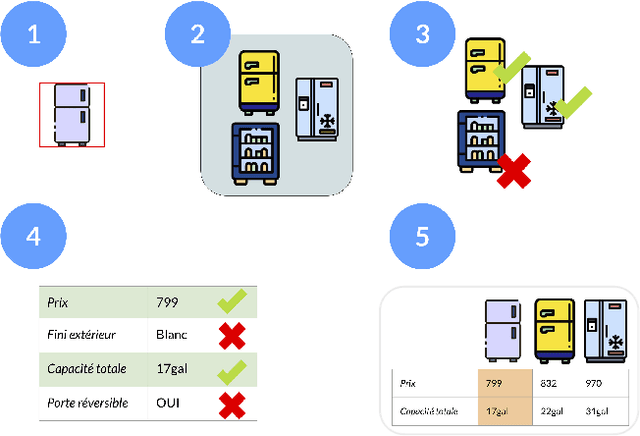
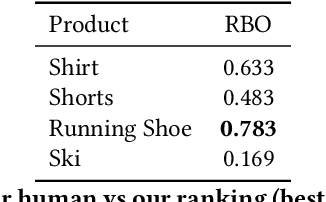
Large eCommerce players introduced comparison tables as a new type of recommendations. However, building comparisons at scale without pre-existing training/taxonomy data remains an open challenge, especially within the operational constraints of shops in the long tail. We present preliminary results from building a comparison pipeline designed to scale in a multi-shop scenario: we describe our design choices and run extensive benchmarks on multiple shops to stress-test it. Finally, we run a small user study on property selection and conclude by discussing potential improvements and highlighting the questions that remain to be addressed.
SIGIR 2021 E-Commerce Workshop Data Challenge
Apr 27, 2021

The 2021 SIGIR workshop on eCommerce is hosting the Coveo Data Challenge for "In-session prediction for purchase intent and recommendations". The challenge addresses the growing need for reliable predictions within the boundaries of a shopping session, as customer intentions can be different depending on the occasion. The need for efficient procedures for personalization is even clearer if we consider the e-commerce landscape more broadly: outside of giant digital retailers, the constraints of the problem are stricter, due to smaller user bases and the realization that most users are not frequently returning customers. We release a new session-based dataset including more than 30M fine-grained browsing events (product detail, add, purchase), enriched by linguistic behavior (queries made by shoppers, with items clicked and items not clicked after the query) and catalog meta-data (images, text, pricing information). On this dataset, we ask participants to showcase innovative solutions for two open problems: a recommendation task (where a model is shown some events at the start of a session, and it is asked to predict future product interactions); an intent prediction task, where a model is shown a session containing an add-to-cart event, and it is asked to predict whether the item will be bought before the end of the session.