Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond NDCG: behavioral testing of recommender systems with RecList
Paper and Code

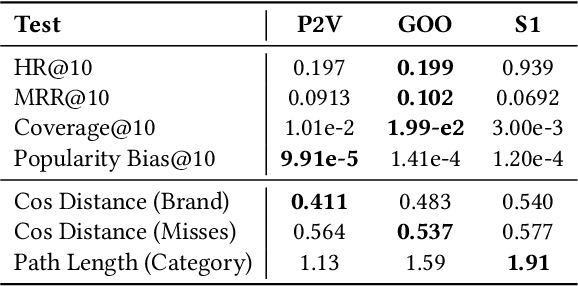
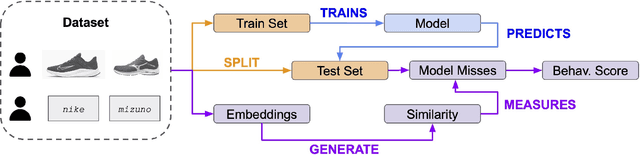
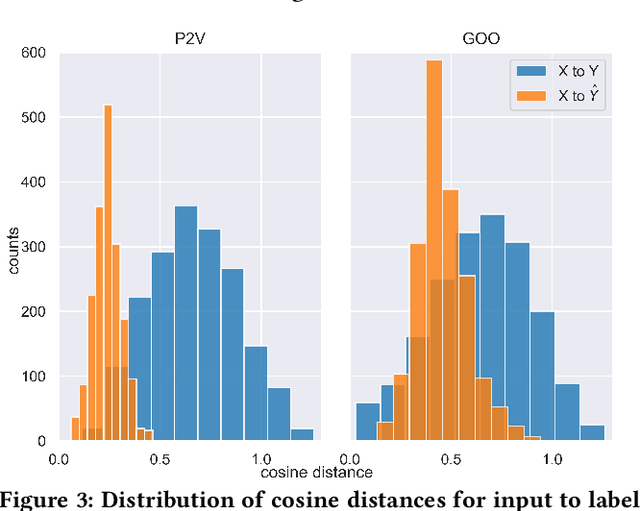
As with most Machine Learning systems, recommender systems are typically evaluated through performance metrics computed over held-out data points. However, real-world behavior is undoubtedly nuanced: ad hoc error analysis and deployment-specific tests must be employed to ensure the desired quality in actual deployments. In this paper, we propose RecList, a behavioral-based testing methodology. RecList organizes recommender systems by use case and introduces a general plug-and-play procedure to scale up behavioral testing. We demonstrate its capabilities by analyzing known algorithms and black-box commercial systems, and we release RecList as an open source, extensible package for the community.
* Alpha draft
View paper on